游戲行業如何實現運維自動化與故障自愈
原創本文是WOT2016互聯網運維與開發者大會的現場干貨,新一屆主題為WOT2016企業安全技術峰會將在2016年6月24日-25日于北京珠三角JW萬豪酒店隆重召開!
關于本次的技術分享,主要是游戲行業運維體系的介紹,側重于游戲行業的運維體系的構建。
第一部分,37游戲的運維體系
馬辰龍總結道,公司從創業到后面的上市基本會經歷四個階段。
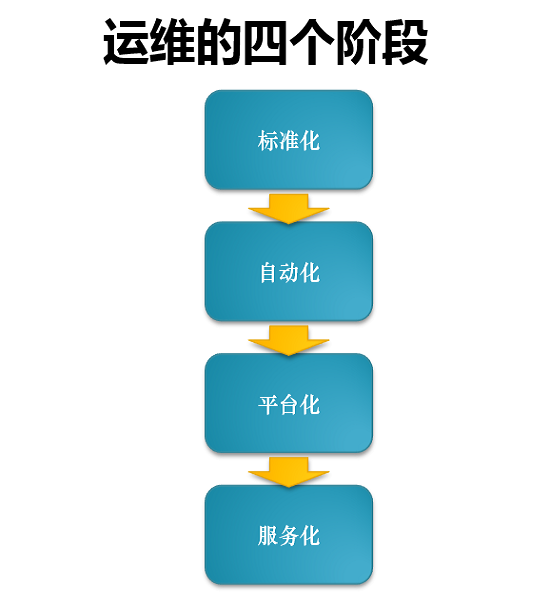
第一個階段就是標準化。標準化的意思是把主機名、內網以及配置文件統一起來,如果不統一,后面的東西就無法繼續。沒有一個標準化的環境,腳本是無法寫下去的。
第二個階段是自動化。中小型企業階段都是自動化到平臺化的過渡,平臺化就是把自動化的東西分裝,把功能整合,把數據做聚合,然后放在平臺上來可視化。
第三個階段是平臺化。以后的趨勢是腳本和功能必須是外部化的,這樣新來的一個人才能接手。不用在服務器上跑腳本,還要同下個人交代在哪兒裝。
最后一個階段就是服務化。服務化是指現在云平臺所承載的東西。舉個例子,搭一個redis集群,用戶不需要知道服務器有多少個,因為所提供的NOSQL服務打開后,用戶就可以直接使用了。
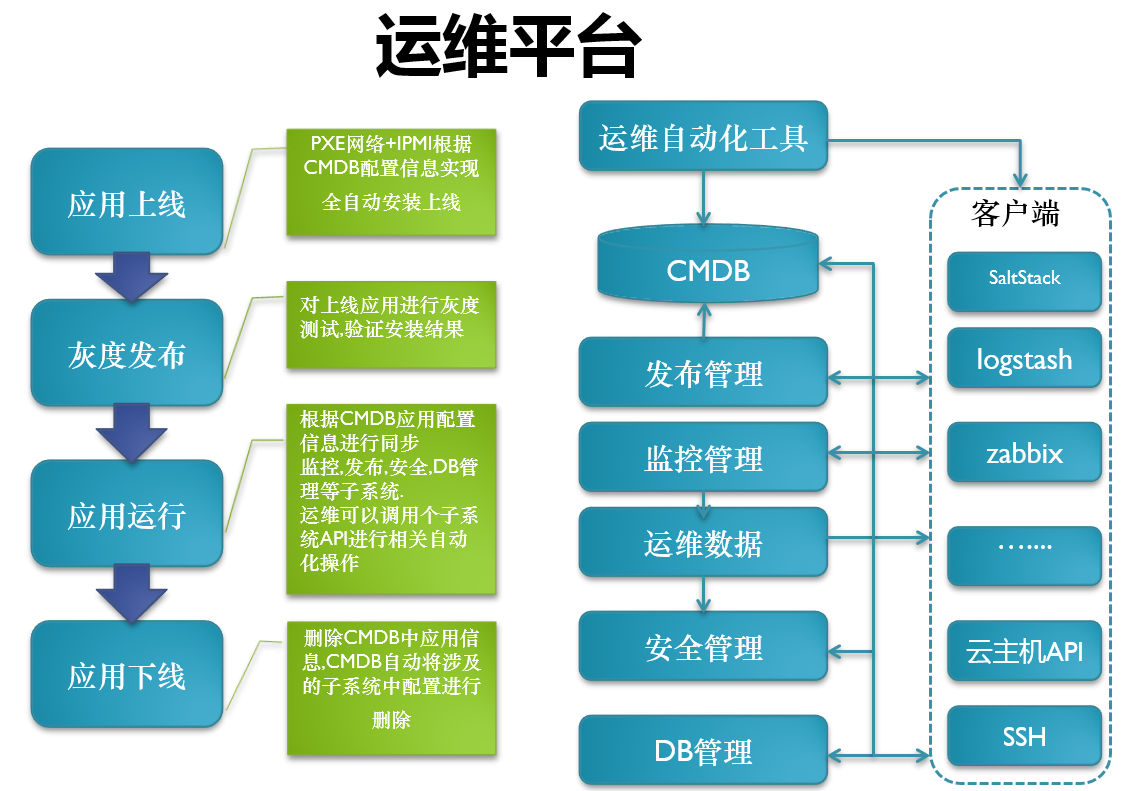
37游戲的自動化工具。37游戲所有的重點數據都在CMDB當中。公司剛開始建立的時候發布是很頭疼的事情,雖然利用SVN來提交,但是沒有一個自動化的發布流程。運維的重點工作是監控,監控做好,運維就會清閑許多,因為大部分的時間都在接收短信告急。很多公司只知道運維是給開發打雜的,熟不知有了運維數據,便可以推動業務的發展。安全管理。如果在大公司里面的話,有專業的團隊做安全管理,跟運維是分離的。如果是在中型企業的話,安全管理是跟運維在一個部門的,二者是離不開的。最后一個是DB管理,DB是37游戲相關的關系型數據庫,NOSQL和集群的管理。
客戶端的分類。服務器操作類就是用SaltStack做Agent,然后用日志收集logstash,API需要的數據可以利用zabbix監控獲得。
應用的上線。應用上線,灰度發布,應用運行,應用下線,這四點貫穿在運維平臺里。舉個例子,配置一個wab服務,wab服務首先是應用去安裝,從CMDB拉數據,再進行灰度發布,然后開始上線,使用到最后下線, CMDB自動將涉及的子系統中配置進行刪除。
CMDB是運維里開始最麻煩的,其實最主要是理清關系,然后信息關聯。在這里簡單地分了幾類,比如域名庫、軟件庫、資源庫、IP庫、配置庫,這些建立起來的話,CMDB必須是可維護性的,建立這些模型之初一定要想到它的可維護性,沒有可維護性后面的數據會很亂從而自動化就不用談了。DB管理、安全管理、監控管理。DB管理分為DB部署、DB監控,里面是關于數據的操作,權限的一些劃分。安全管理就是安全規則管理。
第二部分,監控、日志數據智能分析。
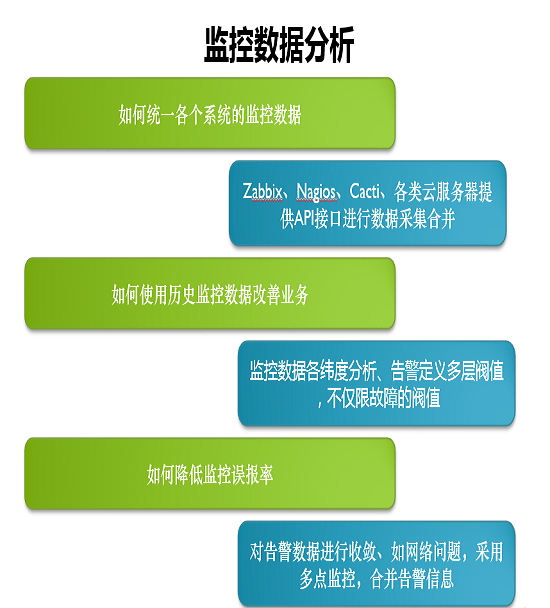
監控數據,因為平臺眾多,所以怎么統一這些數據?37游戲有Zabbix、Nagios、Cacti各種云資源服務器的管理數據,通過API拿到這些數據。Zabbix應該是支持所有的去、增、長、改、查。Nagios其實本身是不支持API的,但可以從它的配件文件里面把數據抓過來。Cacti可以從頁面上抓下來,這些都有一些實踐。只要云服務商是比較可靠的云,也就可能提供API接口。
如何改善我們的監控業務,我們的監控數據從各維度分析,告警定義,就是多層閾值。
還有一個是降低誤報率,運維每天可能收到一百條短信,大概九十條都是誤報。
馬辰龍舉了一個例子:怎么樣用我們的監控數據去推動業務?運維的工作并不是僅僅處理告警了,也需要推動業務的進程。游戲行業的環境是相當復雜的,37游戲有自己的IDC機房去存放游戲。所有的東西都是通過接口去取,再把監控數據匯總到歷史監控數據里。根據天、周、月,和系統應用、網絡等其他維度生成一個報表。值得注意的是,所得數據不是實時的,而是監控歷史數據,因為用實時分析的話,只能是一個告警。之所以判定服務器出現問題,肯定是根據周期性的平均告警率達到多少,平均的使用率低于一定閾值了,才會判定有問題。閾值需要同運營定義。
Web日志的應用。場景就是安全人員需要運維定期的推送一些異常日志,進行XSS注入分析。游戲行業遇到最多的就是被撞庫了,每天都在不停的刷賬號,刷密碼。這個事不光是在游戲行業,在其他行業也會遇到。
37游戲制訂了一個目標,運維負責相關業務日志統一匯總,需要有標準的API查詢接口。現在所有跟跨部門合作,或者同其他人合作都是通過API。安全人員可以自己定義Web過濾規則,寫正則,對異常日志做分析,然后確定攻擊類型,采取相應的措施。各平臺有日志的實時匯總,如果是集群的話,則服務器是分片的,只是每一臺去統計防護失常,或者PV、UV的東西,很難全局性地去判斷。因為經典的架構就是前面ALVS,把它分散到下面的服務器,數據需要先合并,也需要聚合,肯定要花費很大、很長的時間。
拿到數據可以根據用戶的地區,優化服務器區服的配置和用戶體驗。游戲的區域性是很強的,可以根據IP進行精準定位。
37游戲用的是互聯網比較經典的架構ELK。logstash收集日志,隊列用redis,放到redis里面,然后logstash再取,放給ElasticSearch,最后去存儲。建立初期可以直接用圖形化,用Kibana做圖形化視圖的分析。中間的redis只是充當一個隊列,但是架構是不變的,所以上手是非常之快的。如果有開發運維的話,直接可以從Lsearch里面把日志分析出來。web端用自己的過濾規則。如果有問題就扔到黑名單里面,業務在前端做邏輯控制。
第三部分,故障自愈。
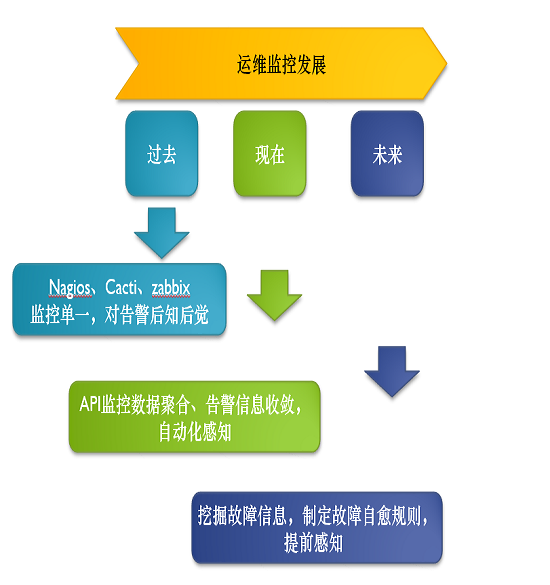
現在大部分中型的企業都有自己的API,監控數據的聚合,告警數據的收斂,很多做自動化。這些做起來并不是很難,關鍵是在做未來的時候,去挖掘故障信息,去制定自己的故障自愈規則。
其所面臨的問題就是系統網絡,業務層面自生的邏輯造成的一些異常,監控誤報還有監控自身的一些可靠性。還有非自愈業務,因為故障自愈不是萬能的,就像現在的人工智能一樣,有些東西是機器代替不了的。比如說復雜的業務場景,可能機器是沒辦法判斷的,可能有些東西是需要人工看,才能知道應該怎么處理。
37游戲所有的告警信息都是發送到告警信息處理中心的,比如說的短信告警,這些都是經過信息統一推送。
這里馬辰龍分享了一個實例,搬到任意一個場景下都可以應用。用自己的Zabbix監控或者somkeping監控甚至第三方監控,獲取監控信息。然后把所有的監控信息全部推送,推送到回調隊列里面去,然后去分析這個告警信息。

故障自愈能帶來什么呢?非工作時間可以處理自己私人的事情,運維第一個要求就是24小時要待命。減少直接對線上的操作,比如出現了故障,直接去操作線上,很有可能會出現二次故障。所以必須要從故障原因里面分析,鍛煉運維人員對工作的積極性,并不是每天都是鼓噪的東西。長遠看來,對玩家,對公司利益,以及自身價值都將有顯著的提升。

最后馬辰龍總結了一點:一定要在自己的領域有獨特的解決方案。
“有很多開源方案是不能直接用的,必須要用到自己的生產環境當中,有自己的一些解決方案。運維工具的設計要很簡單,因為要考慮下一個接手你的東西的時候,維護成本有多高。敲過代碼的人都知道,重寫會比維護代碼好很多。所有的東西都要以業務為核心,一旦脫離了業務,你做的數據其實并沒有什么用。最后要說的是,好的架構是演化來的,不是設計出來的。”馬辰龍講到。
本文整理自,由51CTO傳媒主辦的WOT2016互聯網運維與開發者大會上來自37游戲運維架構師馬辰龍主題為《游戲行業運維自動化與故障自愈》的精彩演講。
演講視頻:http://edu.51cto.com/lesson/id-100749.html
講師簡介:
馬辰龍,負責37游戲運維平臺開發,目前專注游戲行業運維自動化,監控系統故障自愈,擅長perl開發,正則表達式,日志精確匹配。