解密 Uber 數據團隊的基礎數據架構優化之路
如果你用過Uber,你一定會注意到它的操作是如此的簡單。你一鍵叫車,隨后車就來找你了,***自動完成支付,整個過程行云流水。但是,在這簡單的流程背后其實是用Hadoop和Spark這樣復雜的基礎大數據架構來支撐的。
Uber 在現實世界和虛擬世界的十字路口有令人羨慕的一席之地。這令每天在各個城市穿行的數十萬司機大軍趨之若鶩。當然這也會一個相對淺顯的數據問題。但是,就像 Uber數據部門的主管 Aaron Schildkrout所說:商業計劃的簡單明了帶給Uber利用數據優化服務的巨大機會。
“這本質上來說是一個數據問題”,Schildkrout 最近在一個Uber和Databricks的演講記錄中說道。“因為事情是如此淺顯,我們想讓用車體驗變得自動化。在某種程度上,我們正在嘗試為全世界的載客司機提供智能、自動化、實時的服務并且支撐服務的規模化。”
不論是Uber在峰時計價、幫助司機規避事故還是為司機尋找***盈利位置,這一切 Uber 的計算服務都依賴于的數據。這些數據問題是一道數學和全球目的地預測的真正結晶。他說:”這使得這里的數據非常振奮人心,也驅動我們斗志昂揚地用Spark解決這些問題”
Uber 的大數據之道
在Data bricks的演講中,Uber 工程師描述了(顯然是***公開演講)一些在應用擴展和滿足需求上公司遇到的挑戰。
作為負責Uber 數據架構的總負責人,Vinoth Chandar說道:Spark 已經是”必備神器了”。
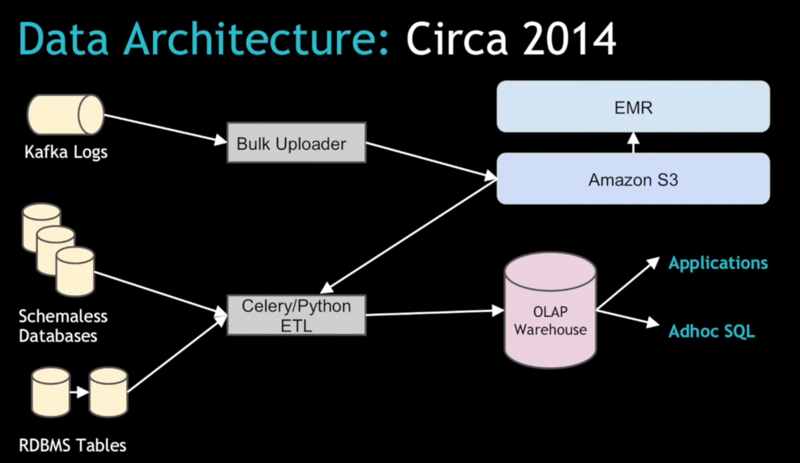
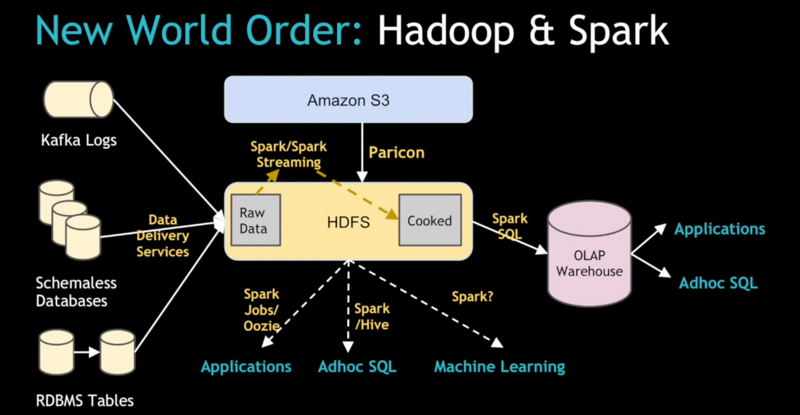
在舊的架構下,Uber依賴于Kafka的數據流將大量的日志數據傳輸到AWS的S3上,然后使用EMR來處理這些數據。然后再從EMR導入到可以被內部用戶以及各個城市總監使用的關系型數據庫中。
Chandar說道:”原來的 Celery+Python的ETL架構其實運轉得挺好的,但是當Uber想要規模化時就遇到了一些瓶頸”。隨著我們擴展的城市越來越多,這個數據規模也不斷增加,在現有的系統上我們遇到了一系列的問題,尤其是在數據上傳的批處理過程。
Uber 需要確保最重要的數據集之一的行程數據,這里成百上千的真實準確的消費記錄將會影響到下游的用戶和應用。Chandar 說道:”這個系統原來并不是為了多數據中心設計的。我們需要用一系列的融合方式將數據放到一個數據中心里面。”
解決方案演化出了一個所謂的基于Spark的流式IO架構,用來取代之前的Celery/Python ETL 架構。新系統從關系型數據倉庫表模型將原始數據攝取做了必要的解耦。Chandar說:”你可以在HDFS上獲取數據然后再依賴于一些像Spark這樣的工具來處理大規模的數據處理。”
因此,取而代之的是在一個關系模型中從多個分布式數據中心聚合行程數據,公司新的架構使用Kafka從本地數據中心來提供實時數據日志,并且加載他們到中心化的Hadoop集群中。接著,系統用Spark SQL 將非結構化的JSON轉化為更加結構化的可以使用Hive來做SQL分析的Parquet文件。
他說:”這解決了一系列我們遇到的額外問題,而且我們現在處在一個利用Spark和Spark Streaming 將系統變得長期穩定運行的節點上。我們也計劃從訪問和獲取原始數據也都用Spark任務、Hive、機器學習以及所有有趣的組件,將Spark的潛能徹底釋放出來。”
Paricon 和 Komondor
在 Chandar 給出了 Uber 涉險進入Spark的概況之后,另外兩名 Uber 工程師,Kelvin Chu 和 Reza Shiftehfar 提供了關于 Paricon 和 Shiftehfar 的更多細節。而這其實是Uber 進軍Spark的兩個核心項目。
雖然非結構化數據可以輕松搞定,Uber最終還是需要通過數據管道生成結構化數據,因為結構化數據在數據生產者和數據使用者之間生成的”契約”可以有效避免”數據破損”。
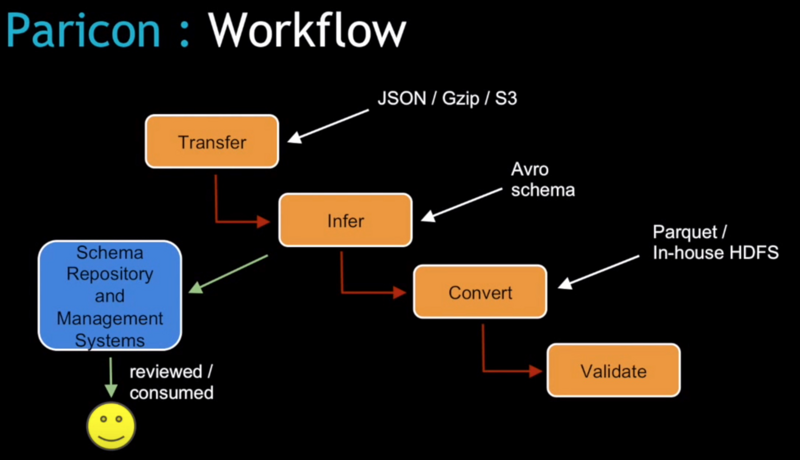
這就是為什么Parino 會進入這個藍圖,Chu說道,Parino 這個工具是由4個 Spark為基礎的任務組成的:轉移、推斷、轉化并且驗證。”因此不論誰想要改變這個數據結構,他們都將進入這個系統,并且必須使用我們提供的工具來修改數據結構。然后系統將運行多個驗證和測試來確保這個改變不會有任何問題。”
Paricon 的一大亮點是所謂的”列式剪枝”。我們有許多寬表,但是通常我們每次都不會用到所有的列,因此剪枝可以有效節約系統的IO。他說道:”Paricon 也可以處理一些”數據縫合”工作。一些Uber的數據文件很大,但是大多數都是比HDFS區塊來得小的,因此我司將這些小數據縫合在一起對齊HDFS文件大小并且避免IO的運轉失常。加之Spark的”數據結構聚合”功能也幫助我們用Paricon 工作流工具直觀簡化的方式處理Uber數據。”
與此同時, Shiftehfar 為Komondor、Spark Streaming內建的數據攝取服務提供了架構級別的諸多細節。而數據源是”烹飪”的基礎,原始非結構數據從Kafka流入HDFS然后準備被下游應用消費。
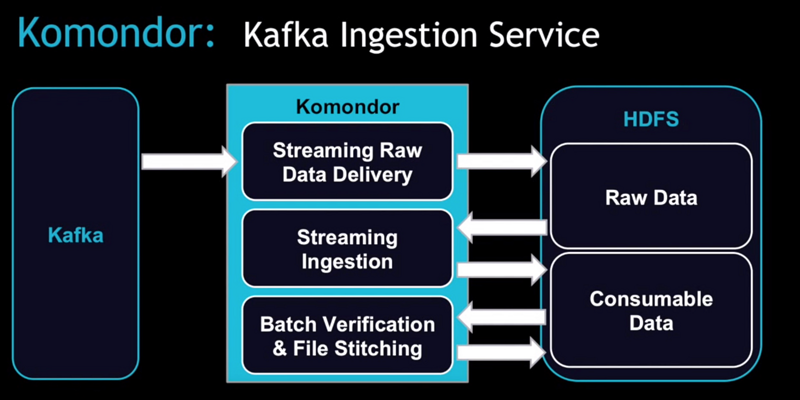
在 Komondor 之前,它是用來為每個獨立應用確保數據準確性的工具(包括獲取他們正在處理的數據的上游數據)并且在必要的時候做數據備份。現在通過 Komondor 可以自動處理或多或少的數據。如果用戶需要加載數據,使用 Spark Streaming 就相對簡單得多。
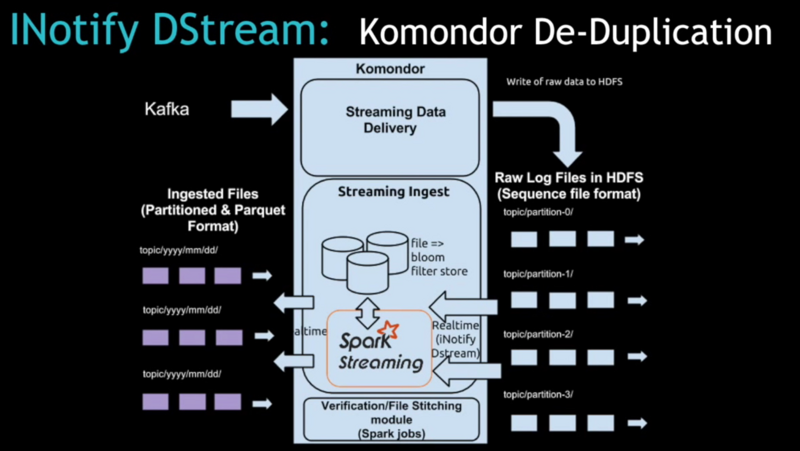
為了處理每天***的事件和請求正在重金投入 Spark 并且打算撬動更多的 Spark技術棧,包括使用MLib和GraphX庫做機器學習和圖計算。更多細節,可以觀看下面演講的整個視頻。