吳紅:芒果TV大數據平臺架構與基礎組件優化
原創2015年8月29日由七牛公司舉辦為期兩天主題為—數據重構未來的七牛·數據時代峰會在上海國際時尚中心。本次大會邀請國內外知名數據專家、互聯網行業、傳統行業數據大咖親臨現場,帶來一場有關數據的饕餮盛宴。
芒果TV依托湖南廣電的內容、用戶資源在2014年迅速成長,同年 7月5日周點擊量超過1.7億。本次七牛數據時代峰會特別邀請芒果TV數據負責人彭哲夫分享芒果TV數據處理實踐分享。
以下是演講實錄:
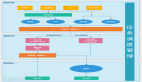
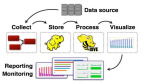
芒果TV團隊從去年開始籌建,現在有十個人,150多個節點,通過數據1.5PB。整體分為三個業務系統分別是數據魔方—負責一些重要指標的統計。第二是系統推薦,是芒果TV 將流量進行轉化引導。第三是視頻內容分析系統,很多互聯網的數據可以轉化成傳統媒體需要的數據,因此芒果TV將一些用戶的記錄可以提供給導演來提供精彩的內容或者劇情發展。
現在芒果TV的數據部門支撐了70%-80%的業務,而今天的演講也分為三個部分:***是基礎篇,第二是整合篇,第三是數據管理篇。
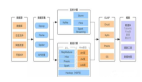
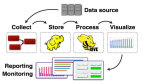
采集是數據的生產方,決定了數據是否可用,而在做搜集時我們會關注一下寬帶成本,作為一家視頻公司,寬帶和版權是成本構成的重要部分。因此我們自己開發了一個SDK把采集到的數據發送到我們自定義的系統上,再進行分類一塊發到FDS上,最終會轉化成數據,形成數據庫。
在實時計算方面,主要是用于播放過程中質量監控。我們回到ES里面去做一些即時查詢。
在采集過程中會列出一個元素然后調用一個方法,然后把所有的參數傳送給服務商,但是弊端在于隨著采集點的增多,代碼需要維護,而且缺少系統性。因此我們做了一個抽象,在采集過程中機型一次分類,比如頁面數據、錯誤數據、播放數據。
另外就是事件問題,事件因為什么處罰?我們通過后端配置把一個元素的名稱和事件整合起來在頁面加載的時候,會把這一塊的配置加載到后端頁面,后端會根據這些加載的配置來決定什么數據需要上報,什么不需要上報。
如果我們需要一個很長的開發周期,使用這個模式時我們只需要在后臺進行一個配置,數據馬上就會過來了。搜集方面,一般采用的是放一個像素的圖片吧一些參數帶到這個圖片后面,但是這種方式會造成寬帶成本非常大,光搜索寬帶會占到600兆左右。為了把服務器資源降低到極值,可以改為PT進行篡數。這樣可以節省接近三分二的帶寬成本。
在傳輸方面我們遇到了一些坑,最重要的問題是占用資源過大,實際上我們隊每一塊進行具體分析也不難解決這個問題。
在數據量過大時我們會遇到一些情況,主要是在于每隔一段時間會建一個文件夾,然而在測試時,時間就要長的很多。所以我們對其做了一個調整,使用單線程的方式做了一個很不錯的優化,當到了1.5 1.6之后會直接導致系統內存膨脹的厲害,所以我們一般會加一條配置參數或者直接把位置進行改掉。
在一般類型文件和文件夾之間選擇,主要考慮效率問題,之前有人提出將二者綜合在數據量高的情況下使用文件。在寫FTX時會導致文件進入關閉的狀態,會導致我們錯誤失敗,我們需要進行監控。另外可能會產生很多小文件會造成比較大的壓力。因為是大數據,數據量不言而喻我們使用的壓縮方式可以壓縮80%的數據量。
在隊列傳輸方面,我們只要使用Kafka,在實踐中來看,并不是分區越多越好,如果分區越多,客戶端和服務端所使用的內存限制也就越多,一個分區會產生兩個文件,這兩個文件會導致具體數量增加,而且Kafka本身的機制—kafka里面有一個頁面分區,會產生投票過程分區越多時間越長會影響使用。
我們的做法是:選擇一臺機器只創建一個分區,然后測試產生和消費的情況如何,我們最關心的是吞吐量,所以TP和TC的***值可以做我們的分區。
在存儲這一塊,我們用的是多級存儲方式,當然遇到的問題在于,當數據量增加時,很多冷數據在里邊,工作壓力會比較大。所以我們會分成三級,主要特點是CPU和內存會比較豐富一點,還可以減少副本以及把冷數據丟到云存儲上面。
在存儲方面另外一個問題就是壓縮,在前期沒有規劃好時,我發現存儲空間已經不夠用了,我們會根據自己的業務進行選擇,使用歸檔日志對小文件進行整理。
在配置方面,我們會把配置整合起來,進行推送,主要是基于RPC的控制模型,對所有的組進行全員的控制。我們的數據服務平臺需要支持公司的很多業務他們只需要一個賬號就可以進行我們采集服務器的傳輸服務、實時計算服務,我們也提供資源流量監控服務……
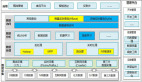
主要說一下我們如何在平臺上管理數據。只要分為幾個部分。一時日志種類的抽象,這和公司的業務息息相關,我們將日志進行分類—播放類日志、廣告類日志。在這其中有一個特別有意思的地方,在芒果TV更關心PV VV這些核心指標,但是如果我們的計算指標的方式和其他同行不一樣,這個數據在行業內就沒有可對比性。所以會從幾個方面去定義:一個是它的概念—運用的常理,如何上報,會導致什么樣的結果。
***上報內容和計算公式,數據到了平臺以后最重要的就是對數據進行管理,為什么要做管理?其實是為了把數據進行分門別類,隨之產生的就是主題式管理—以某一個點為核心,在必須關注的方面我們再次進行分類,這個方式與我們的日志抽象非常相似。
在數據倉庫建立之后,別人需要使用你的倉庫數據們需要一個明細,需要做一個數據的數據。這個元數據分為兩類,一類是技術性元數據主要給開發人員使用,包括一些倉庫結構,以及原始性抽取的一些規則,不然的話數據毫無質量可言。
***為什么需要數據集市?在這個過程中,每一個公司會有很多業務部門,每一個業務部門面臨的問題是不一樣的,比如從統計角度,會更關注哪些數據。但是如果這樣數據倉庫是沒法穩定的。因此需要數據集市進行隔離,在這個過程中我們可以把數據抽出來進行一些隊列,放到我們的關系成本里,這些集市之間的結果是可以互相分享和交換的,更重要的是在于事實表和維表的管理和維護。