獨特低運營成本海量日志處理系統架構
原創本文是WOT2016互聯網運維與開發者大會的現場干貨, 新一屆主題為WOT2016企業安全技術峰會將在2016年6月24日-25日于北京珠三角JW萬豪酒店隆重召開!
黃慧攀表示,又拍云主要做CDN,因此網內會有大量日志產出,量級超乎想象。通常在處理類似這樣量級的大數據時會用到Hadoop、Spark等流行的解決方案,但又拍云卻沒有選擇這些流行的算法。下面我們就走近又拍云來體會這套執行成本高,但運營成本較低的獨特海量日志處理系統架構。
又拍云業務架構概述
業務架構
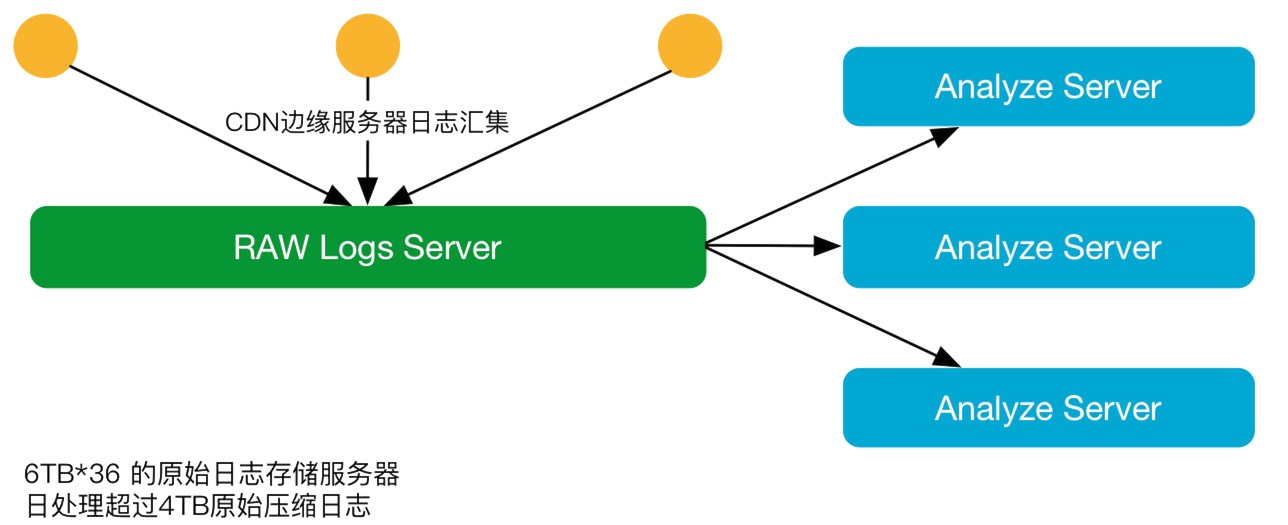
黃慧攀表示,又拍云業務架構非常簡單原始,把NGS日志全部打出來,CDN邊緣有100多個節點,每個節點里面有幾十臺服務器,乘起來就是幾千臺服務器的日志。每隔每五分鐘把邊緣每一臺服務器的日志給收集到原始日志服務器,然后再從原始日志服務器里面供給Work,Work里可多可少,大部分是橫向擴展。然后分析日志,最終產生統計數據,切割出來一些為客戶提供下載日志。在NGS上一個CDN節點是給所有的用戶提供訪問的,不管是大客戶還是小客戶,很有可能你們都在用同一臺NGS,也就是說它的日志里面會混雜著很多個域名。那么日志處理系統就會面臨如何把這些日志按照域名給切分開來?在切分開來數據的基礎上,如何做必要的數據統計及分析?
原始日志的收集和存儲
黃慧攀表示,又拍云原始數據的收集經歷了三個階段,分別是在2011~2014年、2015年、2016年。
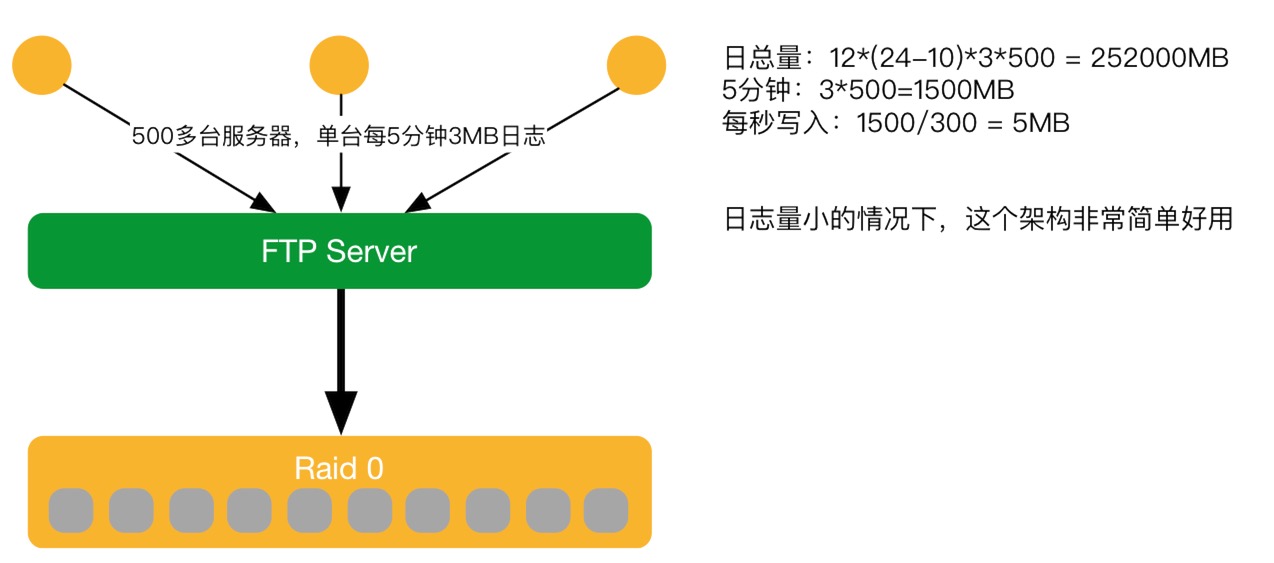
2011~2014年V1
2011~2014年第一階段。在中心搭一臺FTPserver,其他邊緣服務器直接把日志FTP上傳,之后存起來的一個簡單架構。黃慧攀表示,當量級小時,這個架構很好用,簡單又成熟。但如果一旦數據量變大,就會出現瓶頸。又拍云在2014年做云存儲,CDN賣的不多,訪問量不太大,數據量也少,所以這個架構可以應對。
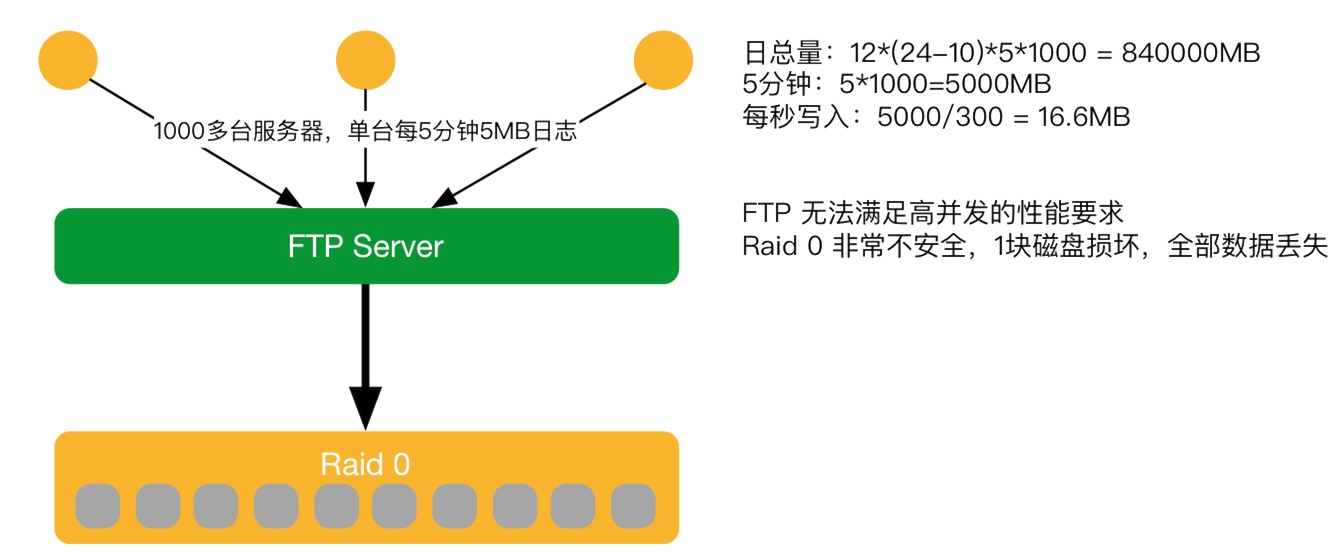
2015年V1顯露不足
隨著這個業務擴展,又拍云在市場做了很多的工作,接入很多的大客戶,導致日志量翻超過10倍之多。那么之前2011年設計的系統只考慮到考慮到10倍的處理能力,所以 FTPserver弊端瓶頸就都顯露出來。如在FTPserver沒有辦法接收這么多的客戶端上傳,邊緣節點太多,連接到FTPserver上,FTP的進程幾千個,服務器很快會被卡死,導致數據不能上傳。如上圖,下面Raid 0非常不安全,1塊磁盤損壞,全部數據丟失。雖然邊緣日志緩存7天,邊緣重新再上報,及時修復沒有影響業務。但會導致人有點手忙腳亂也不是很好。
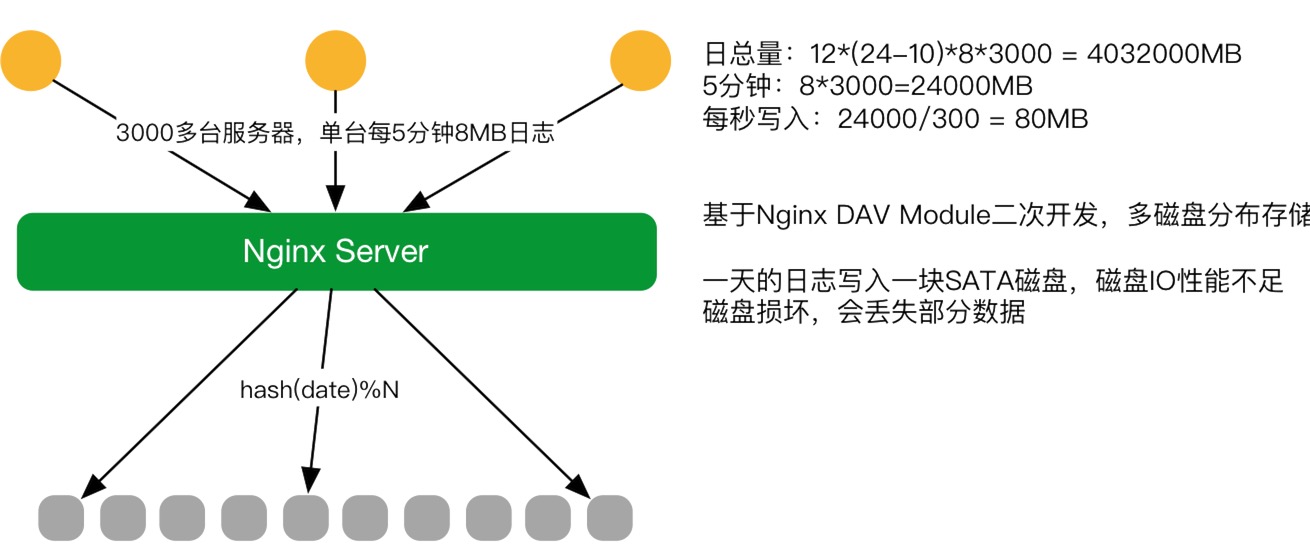
2016年V2
2016年初第二個階段,對原有系統進行改造。把FTPserver,換成了Nginx Server,Nginx Server文件上傳基于DAV Module并做二次開發就可以接受文件的請求。 因原生模塊只支持配置一個路徑,也就是日志只能固定寫入一塊磁盤。可服務器不可能用一塊盤能存得下,每天有幾百G、幾個T的數據需要存儲,磁盤定會爆掉,當時并沒有這么大的磁盤。所以對DAV Module做二次開發,如根據日期,存儲機器一塊盤是6T能存下一天的日志,第一天用1號盤,第二天用2號盤的模式。
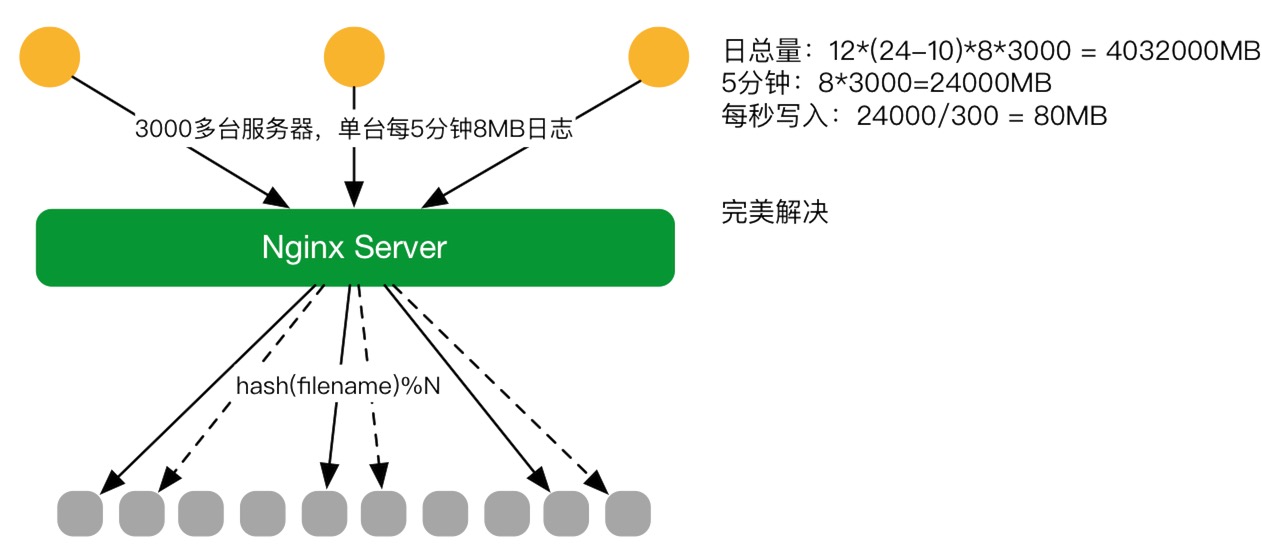
2016年V2.1
第二個版本上線之后,發現了磁盤的寫入成了瓶頸,磁盤不夠快,因為它是SATA磁盤,寫不進去這么多數據。這時第三個版(2.1版本),目前正在實用的版本誕生。對DAV Module進行更改,從原來的根據日期改成用文件名。另外在這個基礎上做增強,原始日志在上傳上來的過程中,同時拷貝到旁邊一塊盤一份,這樣就可以避免單盤故障而導致服務不可用,也不會有數據丟失的問題,盡量的保障業務可以24小時在運行,不需要停下來。這個方案比較完美的解決原始數據的收集問題。
對大量數據進行切割-排序-合并
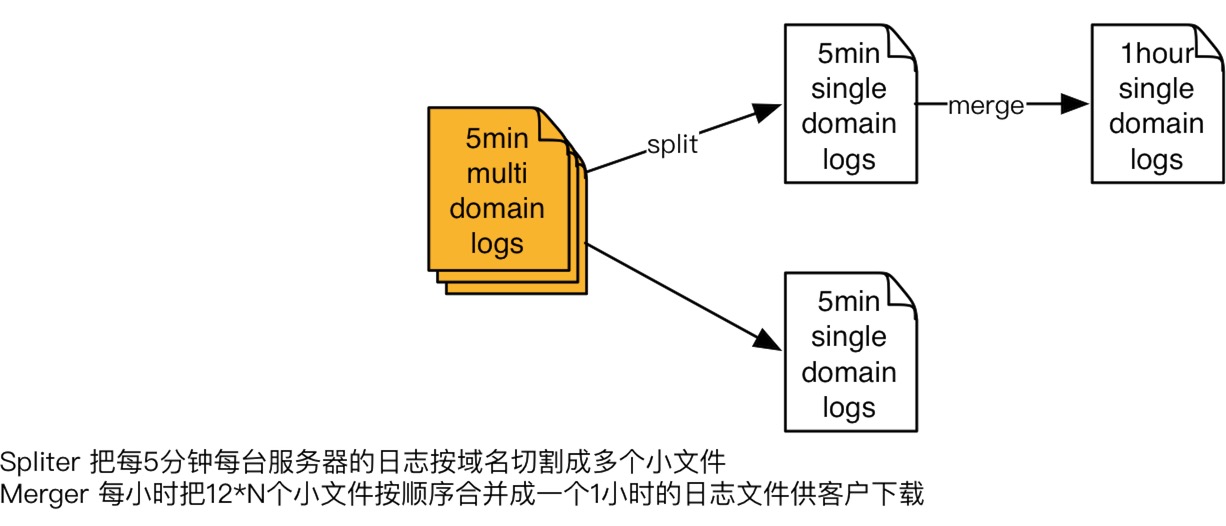
切割-排序-合并
切割。用C寫的一個日志切割程序,把每5分鐘每臺服務器的日志按域名切割成多個小文件,臨時的存在SSD磁盤上面去。切割完成之后,還會有線程檢查前一個小時是不是切割已經完成。
排序。如想要讓排序變得簡單,就要在前期做日志收集規劃時做好基礎。如每五分鐘會有一個文件要上傳上來,可把文件名做加工(把時日期時間點、哪五分鐘的數據)。如一個小時有一千個小文件,在這一千個里面,一定有其中一百個是某一個五分鐘的,就直接拿這一百個做排序。做排序時不用把這些數據減壓出來,放到其他地方臨時存儲來做排序。是把這一百個文件打開,到每個文件在里面讀,讀第一秒,再問另外幾個文件有沒有,沒有就跳下一秒,這樣一個一個順序下來,就按照時間序來讀日志,合并到一個具體文件輸出,這樣的模式是最高效的。因為在處理過程中,就不用把一個具體的文件減壓成文本。如把要減壓,拿什么機器能夠把原始日志給存下來是個問題,因為太大了。
合并。待切割排序完成,就把每小時把12*N個小文件按順序合并成一個1小時的日志文件供客戶下載。
對大量數據進行統計分析

凌晨零點最后一個文件合并出來會啟動統計分析的業務流程,就可以綜合的拿到一些比較有用的指標,如熱門IP分布、URL分布、客戶端、來源、狀態碼計數等數據。
系統架構演變過程中踩過的坑
黃慧攀表示,在系統架構演變過程中遇到了一些坑,把這些分享出來,希望大家不要踩。
第一:SSD inode 數不足,每5分鐘切割出來的小文件非常多,要以最小block大小格式化磁盤。
第二:跨網絡上傳很慢,需要多線路支持;小運營商會改寫內容,走HTTPS。
第三:日志存儲磁盤SATA容易壞,要分別寫入2個磁盤(SSD 也會壞)。
第四:服務器也不穩定,要雙集群模式處理,保障業務不中斷。
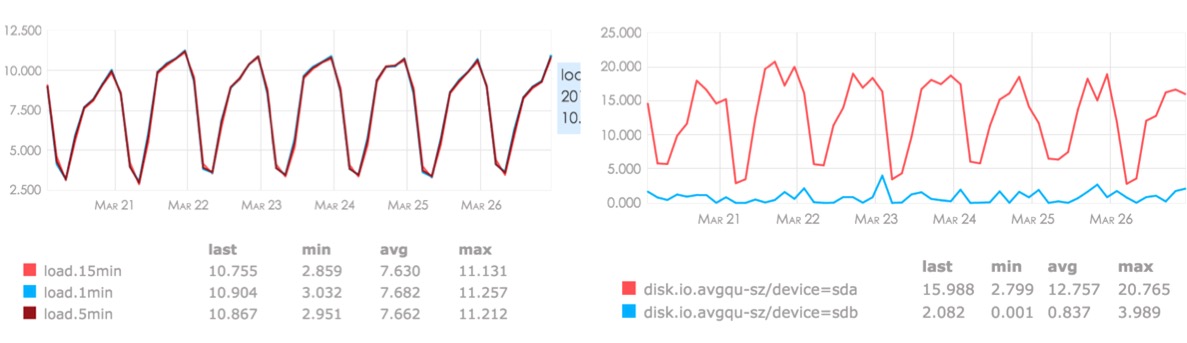
存儲服務器和處理服務器的監控圖
演講最后,黃慧攀為大家展示了存儲服務器和處理服務器的監控圖。他表示,當下這個海量日志處理系統架構基本是非常穩定,集群狀態很正常健康,冗余度也比較高。
演講視頻:http://edu.51cto.com/lesson/id-100758.html
【講師簡介】
黃慧攀,又拍云CTO。他是 aLiLua Web 開發框架的作者,有 14 年互聯網從業經驗,技術經驗涵蓋范圍比較廣,早期以前端 Web 開發為主,后期逐步轉到底層研發方向。QCon 、ArchSummit、中華架構師大會講師,在高性能網絡服務、分布式存儲系統等方面有較深入的研究。