為什么說建立統一數據平臺是重要的
原創本文是WOT2016互聯網運維與開發者大會的現場干貨, 新一屆主題為WOT2016企業安全技術峰會將在2016年6月24日-25日于北京珠三角JW萬豪酒店隆重召開!
楊大海表示,對于一個外行人或剛入門的人來說,建立一個數據平臺就是搭一個Hadoop集群而已。但基于這個集群,想要把它很好的用起來會暴露很多的問題。那么針對這些問題就需要研發很多系統來應對,所以建立統一數據平臺是非常重要的。
為什么說建立統一數據平臺是重要的
門檻,這里楊大海表示,并不是現在做大數據的門檻有多高,因為整個大數據領域的技術非常成熟,人員也很多,很多公司都自己的團隊做大數據。這里所說的門檻是指非大數據領域的一些人,如分析師可能只會寫一些SQL語句或只能看懂一些數據,出一些報表,如果讓這類人寫Mapreduce或數據收集研發東西,就會覺得非常難,如果建立一個完善的數據平臺,可有效幫助他們。
共享, 假設某公司有很多技術團隊、不同部門、不同業務團隊。如每個團隊都搭一套Hadoop群,中間的數據共享就成了問題。還就是資源浪費,像人力資源浪費和服務器資源浪費等。
規范,基于大數據系統做一個數據產品,需要數據采集、收集、存儲和計算等多個步驟,這樣整個流程是非常長,花30%時間做業務系統開發,70%時間用于平臺搭建或一些開源的完善,是非常不劃算的。設想做數據產品之前就已經有系統供選擇,有數據需要采集,有新計算模型需要誕生時候只需要接入,不需要再花時間調研。制定規范之后,日志放在哪,通過標準配置,就可以把日志采上來供使用。這樣一來,就保證盡可能縮短數據采集整個的流程。
成本,這里指人力成本和服務器,就是硬件資源的成本。有統一數據平臺,就可以做很多優化。面對一千臺規模的服務器,可通過一些修改原碼、參數優化等提升10%,就可節省約64G或者128G、4核服務器一百臺。
時間,開發一套業務系統,大可不必花一個月的時間調研Hadoop,花一個月時間的調研Kafka,因為這些不在業務團隊的競爭范圍之內。更多的精力應放在產品或系統,如何把系統做得更***,而不是怎么把Hadoop打好。
Hadoop集群的發展進程
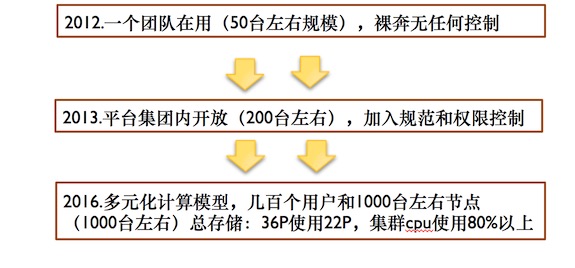
Hadoop發展規模
如上圖,楊大海表示,從2012年到2016年,Hadoop集群在不斷進化發展中。集群最初起點比較低,只是為了滿足數據分析團隊和推薦團隊使用,只有三四十臺的規模。在2012年到2013年的時間,集群擴張的非常快。到2013年接入很多用戶,公司其他團隊如廣告、分成等團隊接進。集群膨脹厲害,半年時間翻了四五倍,到200臺左右的規模。到2016年時間,整個集群將近一千臺規模,中間做了一次升級,就是1.3升級2.3,當時升級是為了滿足周邊的一些生態圈。
Hadoop集群發展過程中遇到的問題

hadoop問題演變
如上圖,楊大海表示,整個集群發展過程中遇到的問題是隨著階段的推移不斷地變化的,也就是說不同階段遇到的不同的問題各不一樣。
50臺規模時,整個生態圈不完善,像Hive等本身還有很多Bug,但因為剛開始,應用簡單所以并沒有發現。此時團隊技術功底非常差,集群管理基本上沒做,直接搭了一條集群,裸奔的集群。
200百臺規模時,遇到的問題相對多一些,楊大海在這里介紹了權限問題、用戶管理、資源調度、調度系統、數據安全、目錄規范、參數規范、本地化八大問題。
- 權限問題, 用戶增多,十個上百個,那權限就成了問題。
- 用戶管理,如何把用戶管理好,保證用戶的作業及時提交,而不是因為某個用戶提交一個大作業,把整個集群資源占完,其他的腳本沒法跑。如何保證這個用戶存儲不會***擴張。如何給用戶規劃存儲。
- 資源調度,保證用戶一定獨立空間,控制占有的資源數目,不至于把整個集群的資源給占完。
- 調度系統,一臺服務器,一臺客戶端,可能會給三個團隊用,每天晚上會有上萬個,甚至幾千個、幾百個作業來提交,通過這臺機器來提交。調度系統是為了解決客戶端單節點的問題,單點故障的問題。
- 數據安全,公司內部雖是同一個集團公司,但分為不同的BU,這些BU之間的數據是需要共享、也需隔離。
- 目錄規范,日志如何存儲,用戶目錄如何規劃,目錄需要多大的空間,如果超過空間我如何提醒刪除。
- 參數規范,Hadoop有很多參數,需要增加,也需要優化。
- 本地化 ,有時需對Mapreduce本地化,因為突然間上了兩百臺機器,Mapreduce從中取數據,但本地沒有需遠程,這還需要對本地化參數做優化。
1000臺左右高可用多計算模型共存時,問題就更多,更加繁瑣。如用戶水平、高可用、小文件、數據遷移、任務問題、存儲計劃、機房瓶頸、歸檔、資源爭強分類、資源隔離、任務監控、列隊監控等。
- 用戶水平,用戶水平有低有高,這就需要有一個人專門解答每天用戶的問題。
- 高可用,這里需要做HHA,因為宕機后影響太大,所有團隊的任務都需要重跑,所有團隊的數據都需要重鋪。
- 小文件,集群有一千臺服務器,小文件數是非常多。內目錄內存現在已經用到150G左右,這就需要對文件數進行控制,對近兩年文件做歸檔。
- 任務,需要看許多指標找出問題,這更強大的監控系統來支持。
- 存儲計劃,同運維報一個存儲計劃,如集群打算一個月擴多少臺服務器、如根據流量、數據量、任務量去申報。因為不可能現在突然間擴一百個機器,運維也不一定有兩百臺的機器提供。
- 資源爭搶,是比較嚴重的問題,集群升級變快,但突然間可能提交不上去。
- 因為當時的調度策略,在做版本迭代升級時,有一些新功能剛推出,很多特徑還不支持。
- 資源隔離,這個是之后需要做的事情。如一個任務死循環把整個服務器跑掛問題的解決。
Hadoop數據平臺的發展現狀
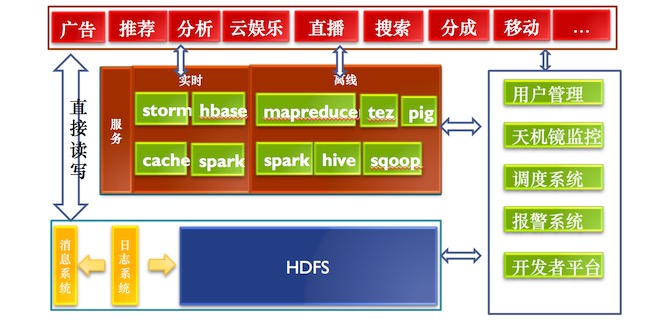
數據平臺現狀
楊大海表示,上圖是現在數據平臺的發展現狀。最上層系統如團隊、廣告、推薦、分析、云娛樂、直播、搜索、分成、移動等,這些系統最原始的它們需要數據,所以有一套日志系統,把數據采集并存儲。日志系統是研發的,因為需要解決跨機房的問題。日志收集需要遍布在全國很多個機房,機房日志收集是需要聚合,最終的數據都要聚合到一個點。左邊是數據的計算部分,可直接讀取日志系統的數據。右邊用戶管理系統是為了滿足用戶申請賬號、放文件、需要歸屬一個團隊、訪問團隊資源。監控報警系統,來做統一的監控報警。
Hadoop數據平臺的未來
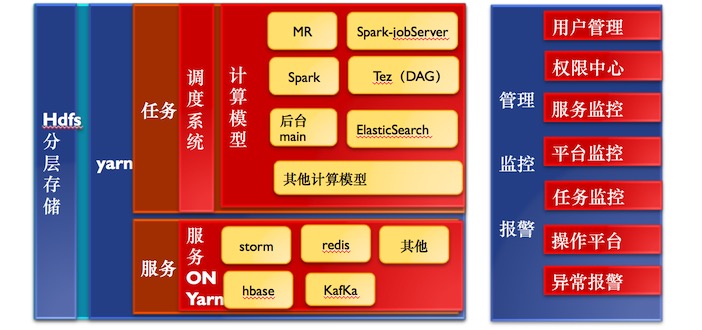
hadoop平臺未來
楊大海表示,上圖是集群的未來的樣子,現在我們已經做到90%,但還沒有完全解決。未來整個存儲分為實時和離線兩部分。HDFS存儲可能會遍布到大數據所有服務器,很多團隊是不做存儲的,所以可以把存儲遍布到所有的服務器,給你團隊的賬號。基于Yarn話會做虛擬化,完全把解決資源,資源無法隔離的痛點。基于Yarn開發更多的計算模型出來,如自定義的一些計算模型。
Hadoop平臺將要面臨的挑戰

Hadoop平臺將要面臨的挑戰
如上圖,楊大海表示,Hadoop平臺將要面臨的挑戰分為三部分HDFS、Yarn、Client。針對HDFS面臨的挑戰有Namenode性能瓶頸、日志大小的控制、節點操作的API、多機房方案、集群規模太大Namenode性能瓶頸等。針對Yarn面對的挑戰有調度個性化分類、資源隔離、數據倉庫的必要性、基于標簽調度完善、更強大的監控平臺等。針對Client面對的挑戰有Docker統一管理、配置問題、業務依賴升級問題等。
Hadoop數據平臺的運營問題
關于Hadoop數據平臺的運營問題 ,楊大海這樣說,對內部運營是非常有必要的,綜上那么多問題,就因為初期運營預料到這些問題,但沒有做好,導致后期花非常大的代價去挽回。他還從規范、計劃、流程和策略四方面針對運營問題,做了講解。
- 規范,就是目錄怎么存,可以放多大文件,放多少文件,占用多少資源。讓用戶一開始就了解這個事情,以免一起限制導致客戶煩感。
- 計劃,集群要做一下計劃,不同的時間做不同的事情,滿足用戶更個性化的需求,如何時完善更多的計算模型。
- 流程,用戶在使用平臺期間詳細的知道整套的流程,如用戶賬號申請,如用HDFS的話做那些事,用Kafka的話做哪些事等等。所有系統之間的賬號全部打通,一個賬號全部搞定。
- 策略,很多時間需要制定策略來限制用戶,這里說的限制并不是讓用戶用的不爽,是讓它更健康的發展下去。
在演講***,楊大海提到了兩個問題數據倉庫和數據服務。建立一個數據倉庫,對數據平臺來說表面上看起來是兩件毫不相關的事情,一個是做數據底層,一個是做數據服務。其實兩邊關系非常大,如果沒有一個數據倉庫,做底層的會非常痛苦。這里的痛苦并不是技術滿足不了,而是要不斷的擴容。數據服務更大的意義是保證數據的一致性,如廣告團隊算了一個視頻的VV量和播放量和分析團隊算的一個視頻的播放量不一致,這個數據是沒法解釋的。其實大家原數據都一樣,統計口徑不一樣,才造成這個問題。所以數據服務是把一部分可以公開的數據算好,通過接口去公開,部分不可以公開數據,做成帶有偷窺認證,帶有用戶認證數據結構提供出去。盡可能做到的把公司的業務前面的幾個主題做倉庫。
演講視頻:
http://edu.51cto.com/lesson/id-100760.html
http://edu.51cto.com/lesson/id-101082.html
【講師簡介】
楊大海,前優酷土豆大數據平臺高級架構師,優酷土豆的大數據開放平臺研發負責人,主要負責優酷土豆開放大數據平臺的研發和運營。曾就職于亞信聯創負責bi商業智能產品的研發。