有容乃大 UCloud數據倉庫UDW架構解析
數據分析對于很多企業是不可或缺的。幾乎所有大型企業都已構建了數據倉庫, 以便對各種來源的數據進行報告和分析,為決策提供依據,從而指導業務流程改進。構建并運行數據倉庫是一件復雜而費力的事情。大部分數據倉庫都很復雜,前期投入的軟件、硬件、人力都會很多。另外,傳統數據倉庫在數據爆炸性增長的今天、擴展比較困難、性能下降明顯。
為了解決這些問題,UCloud 近日推出了大規模并行、完全托管的PB級數據倉庫服務——UDW,可以極大地減少部署數據倉庫相關的成本和工作量,更高效地使用商業智能 (BI)工具來分析海量數據。
MPP體系結構+高可用架構 實現高性能
UDW提供可視化的控制臺,能方便快捷的管理和監控數據倉庫,降低使用門檻;此外,支持數據壓縮、深度優化的軟硬件方案,按實際數據處理需求開通節點實例,無需為搭建數據倉庫一次性投入高額成本;同時,支持行存儲及列存儲的數據存儲方式,滿足不同場景下的數據存儲需求。
UDW是基于PostgreSQL開發的大規模并行、完全托管的PB級數據倉庫服務,幾乎支持了PostgreSQL的所有特性。用戶只需掌握標準SQL語法,就可以熟練地使用UDW。
架構上采用了可擴展的MPP分布式體系,能為用戶提供高性能、低成本、高可用的分布式數據倉庫。
MPP體系結構
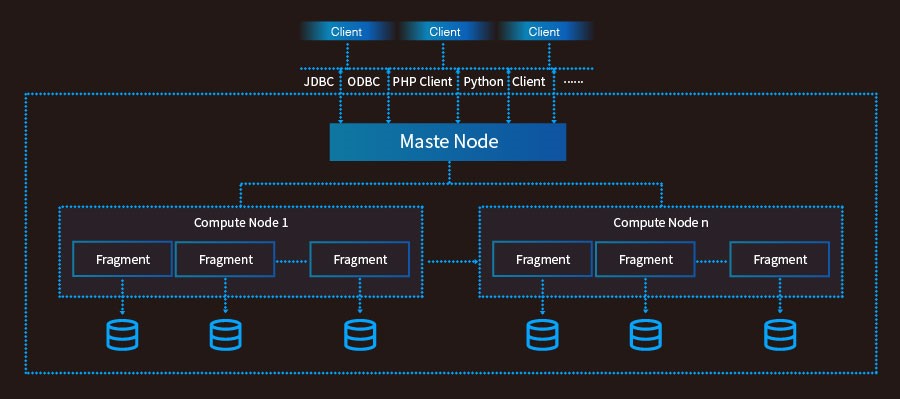
圖1.1 UDW架構圖
UDW采用無共享的MPP架構,適用于海量數據的存儲和計算。UDW的架構如上圖1.1所示,主要有Client、Master Node和Compute Node組成。基本組成部分的功能如下:
Client:訪問UDW的客戶端、支持通過JDBC、ODBC、PHP、Python、命令行SQL訪問UDW。
Master Node:訪問UDW數據倉庫的入口,它接收客戶端的連接請求、負責權限認證、處理SQL命令、調度分發執行計劃、匯總Fragment的執行結果并將結果返回給客戶端。
Compute Node:Compute Node管理節點的計算和存儲資源,每個Compute Node有多個Fragment組成,Fragment負責業務數據的存儲、用戶SQL的執行。
UDW的高可用架構
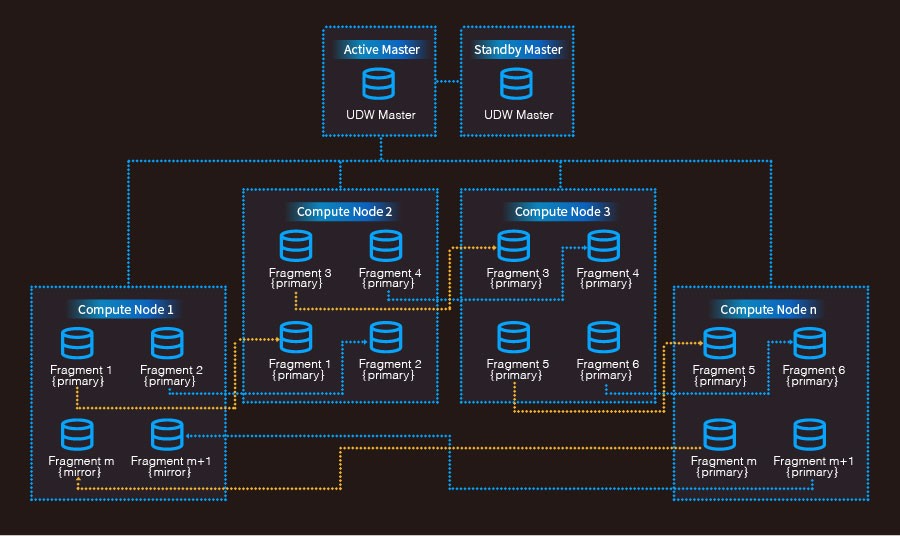
圖1.2 UDW的高可用架構
如上圖所示,Compute Node中的Fragment通過mirror備份到其他的Compute Node上。當primary Fragment出現不可用的時候會自動切換到mirror Fragment、當primary Fragment恢復之后、primary Fragment會自動恢復這期間的變更。
除了Compute Node節點為Fragment配置鏡像之外、UDW也會為Active Node配置鏡像,確保系統的變更信息不會丟失,提升系統的健壯性。當Active Master不可用時會自動切換到Standby master。
分布式數據存儲和并發執行任務
在UDW數據倉庫中所有的表都是分布式的,每張表都會被切片。切片規則可以選擇按照指定的Key進行Hash分片或者選擇隨機分片。如下圖所示test1、test2、test3、test4四張表的數據都會切片分布到所有的Fragment上面。
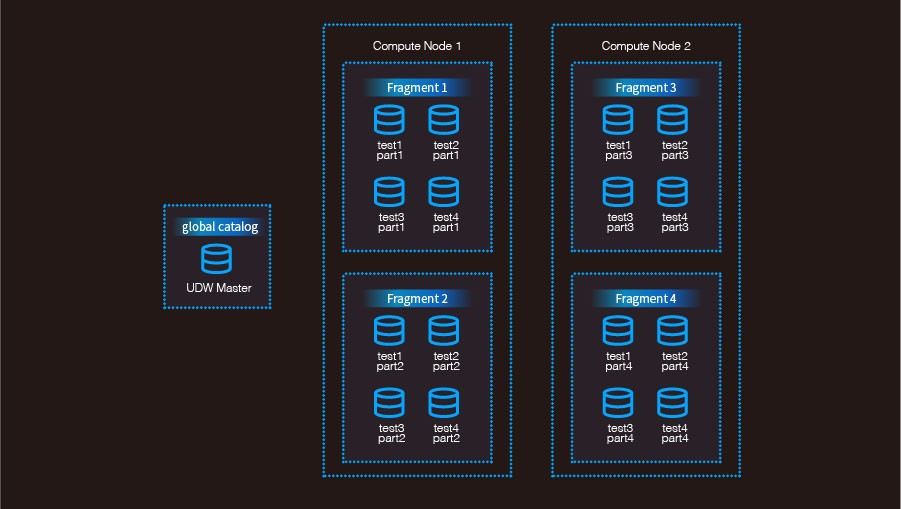
圖1.3 UDW數據分布圖
在進行數據分析的時候、所有的Fragment同時工作、每個Fragment只需計算一部分數據、所以計算效率會大大提升。如下圖所示、Master Node會把查詢任務下發到每個Fragment,Fragment接收到任務后,把任務劃分若干步執行。
Step 1:scan表格數據,如果數據不需要重新分布直接本地做計算、數據處理之后由master做匯總,進入Step3。如果數據需要重新分布,則通過網絡傳輸到對應的Fragment,然后進入Step2。
Step2:數據處理
Step3:master節點匯總數據

圖1.4 UDW的并發執行
結語
UDW非常適合商業智能(BI)領域的大數據聯機分析處理(OLAP)。充分滿足用戶對海量歷史數據的存取需求,為系統日志、銷售數據、監控數據等歷史數據提供低成本的存儲方案。
可對傳統互聯網、移動互聯網、金融、電信、物聯網等領域提供PB級別海量數據存儲、查詢、統計、分析,方便企業BI業務。
當你的數據規模達到500G,單個MySQL數據庫已經難以支持。隨著業務增長,數據規模可能會達到TB級別甚至可能達到PB級別,如果希望后續能夠平滑的擴容,UDW為你提供了一個低成本、高效率的解決方案。
UDW現在已經進入全面公測,只要你了解一點SQL語法就能快速熟練的使用UDW。另外我們也提供了詳細的說明文檔。詳見:https://docs.UCloud.cn/upd-docs/udw/index.html