眾所周知,數據倉庫的初始架構旨在通過把來自各種異構數據源的數據,收集到集中式的存儲庫中,以提供分析的見解,并充當決策支持和商業智能(business intelligence,BI)的支點。不過,由于它只能支持寫入時模式(schema-on-write),而無法存儲非結構化的數據、不能與計算緊密集成、以及只能實現本地設備存儲,因此近年來,數據倉庫碰到了諸如數據模型設計耗時過長等各種挑戰。
盡管目前的數據倉庫能夠支持以在線分析處理(OLAP)服務器作為中間層的三層架構,但是它仍然屬于一種被用于機器學習和數據科學的整合平臺。此類平臺雖然具有元數據層、緩存層和索引層,但是這些層次并非單獨存在。下面,我將向您重點介紹如何改進當前的數據湖平臺,并最終將其變成Lakehouse,以增強架構模式,進而改造傳統的數據倉庫。
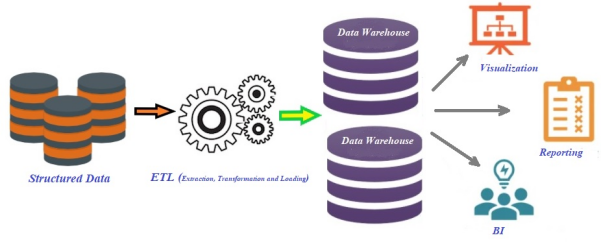
傳統數據倉庫平臺的架構
HDFS
上圖展示了傳統數據倉庫平臺的邏輯架構。近年來,隨著音頻、視頻等非結構化數據集的快速增長,許多組織和企業都在尋找和探索某種高級的替代產品,以解決與傳統數據倉庫系統相關的復雜性問題(正如本文開頭所提到的各種痛點)。目前,業界常用的是于2006年面世的Apache Hadoop生態系統。通過利用HDFS(Hadoop分布式文件系統),它解決了在被加載到傳統數據倉庫系統之前,將原始數據提取并轉換為結構化格式(即:行和列的形式)的主要瓶頸問題。
HDFS不但能夠處理在商用硬件上運行的大型數據集,而且可以適應通常具有GB和TB體量的數據集應用程序。此外,它還可以通過在集群上添加新的節點,來進行水平擴展,以適應海量的數據,而無需考慮任何數據格式的需求。你可以通過鏈接—https://dataview.in/installation-of-apache-hadoop-3-2-0/,來進一步了解如何在多節點集群上安裝和配置Apache Hadoop。
Hadoop生態系統(Apache Hive)的另一個優勢在于,它支持讀取時模式(schema-on-read)。由于傳統數據倉庫具有嚴格的寫入時模式原則,因此ETL(Extract-Transform-Load的縮寫)步驟在遵守已設計好的表空間時,非常耗費時間。而通過一行語句,我們可以將數據湖定義為一個存儲庫,以存儲大量原始數據的原生格式(包括:結構化、非結構化和半結構化等),以用于后續分析,預測分析,通過執行機器學習代碼與APP,來構建算法等大數據處理操作。
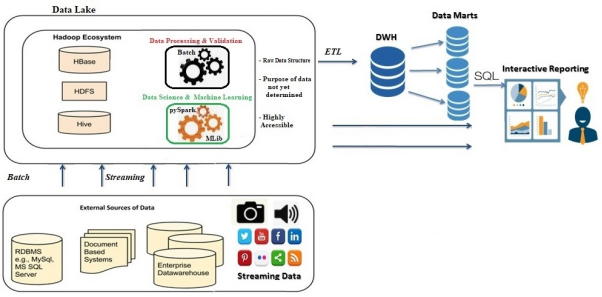
數據湖架構
如上圖所示,由于沒有適合的數據模式,因此數據湖在加載之前不需要進行任何數據轉換,那么如何保持數據質量便成了一個大問題。數據湖并沒有完全具備解決數據治理和安全相關問題的能力。因此,機器學習(ML)以及數據科學的應用,需要使用非SQL代碼,來處理海量的數據,以便成功地部署和運行在數據湖上。但是與SQL引擎相比,由于缺乏已優化的處理引擎,因此數據湖往往無法很好地服務此類應用。而且,僅靠這些引擎,是不足以解決數據湖的所有問題,甚至取代數據倉庫的。此外,數據湖中仍然缺少諸如ACID(原子性,atomicity;一致性,consistency;隔離性,isolation;持久性durability)屬性等功能、以及索引等高效的訪問方法。據此,構建在它上面的機器學習和數據科學等應用,也會遇到例如數據質量、一致性和隔離性等數據管理問題。因此,數據湖需要額外的工具和技術,來支持SQL查詢,以便執行各種商業智能和報告。
Lakehouse
借助著S3、HDFS、Azure Blob等數據湖的處理能力,Lakehouse結合了數據湖的低成本存儲優勢,以開放的格式為各種系統提供訪問,并凸顯了數據倉庫強大的管理和優化功能。目前,??Databricks???和??AWS??都相繼引入了數據Lakehouse的概念。
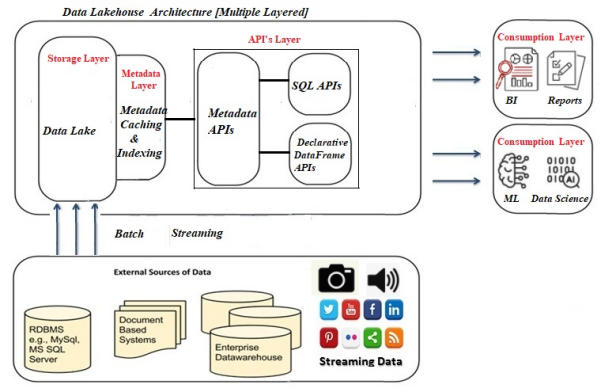
數據Lakehouse架構的多層架構
Lakehouse能夠提高各種高級分析負載的速度,并為其提供更好的數據管理功能。如上圖所示,Lakehouse通常分為五層,它們分別是攝取層、存儲層、元數據層、API 層、以及最后的消費層。
- 攝取層是Lakehouse的第一層,負責從各種來源提取數據,并將其傳送到存儲層。該層可以使用各種組件來攝取數據。其中包括:用于從IoT設備處流式傳輸數據的Apache Kafka、用于從關系數據庫管理系統(Relational Database Management System,RDBMS)處導入數據的Apache Sqoop、以及支持批量數據處理的更多組件。
- 由于計算層和存儲層得到了分離,因此數據Lakehouse最適合云存儲庫服務。它可以利用HDFS平臺在本地得以實施。在設計上,Lakehouse允許開發者將各種數據保存在諸如AWS S3等低成本對象的存儲中,并作為使用標準文件格式(例如Apache Parquet)的對象。
- Lakehouse中的元數據層負責為湖存儲(lake storage)中的所有對象提供元數據(即,提供有關其他數據片段信息的數據)。此外,它還可以管理如下方面:
- 確保并發各項ACID事務
- 使用更快的存儲設備(如,處理節點上的SSD和RAM)緩存來自云服務對象所存儲的文件
- 通過索引,以加快查詢的速度
- Lakehouses中的API層提供了兩種類型的API:聲明性DataFrame API和SQL API。在DataFrame API的幫助下,數據科學家可以直接使用數據,來執行他們的各種應用。例如,TensorFlow和Spark MLlib等機器學習代碼庫,可以讀取Parquet等開放的文件格式,并直接查詢元數據層。而SQL API可以用于為組合業務分析、數據挖掘、數據可視化等商業智能、以及各種報告類工具,獲取數據。
- 最后,消費層包含了諸如Power BI、Tableau等各種工具和應用。整個企業的所有用戶都可以使Lakehouse的消費層,來執行各種分析任務。其中包括:商業智能化儀表板、數據可視化、SQL查詢、以及機器學習作業等。
此外,Lakehouse架構也最適合在組織內部,為各種數據提供單點式訪問。
小結
Lakehouse架構是應對數據提純的復雜性、查詢的兼容性、熱數據的緩存等需求產生的。目前,該單體架構尚處于初級階段。但是,在不久的將來,Lakehouse作為一種數據工具,將能夠實現數據發現、數據使用指標、數據治理等更加豐富的功能。
原文標題:??The Lakehouse: An Uplift of Data Warehouse Architecture??,作者:Gautam Goswami