一文看懂網(wǎng)絡(luò)爬蟲(chóng)
從基礎(chǔ)理論入手,詳細(xì)講解了爬蟲(chóng)內(nèi)容,分為六個(gè)部分:我們的目的是什么;內(nèi)容從何而來(lái);了解網(wǎng)絡(luò)請(qǐng)求;一些常見(jiàn)的限制方式;嘗試解決問(wèn)題的思路;效率問(wèn)題的取舍。
一、我們的目的是什么
一般來(lái)講對(duì)我們而言,需要抓取的是某個(gè)網(wǎng)站或者某個(gè)應(yīng)用的內(nèi)容,提取有用的價(jià)值,內(nèi)容一般分為兩部分,非結(jié)構(gòu)化的文本,或結(jié)構(gòu)化的文本。
1. 關(guān)于非結(jié)構(gòu)化的數(shù)據(jù)
1.1 HTML文本(包含JavaScript代碼)
HTML文本基本上是傳統(tǒng)爬蟲(chóng)過(guò)程中最常見(jiàn)的,也就是大多數(shù)時(shí)候會(huì)遇到的情況,例如抓取一個(gè)網(wǎng)頁(yè),得到的是HTML,然后需要解析一些常見(jiàn)的元素,提取一些關(guān)鍵的信息。HTML其實(shí)理應(yīng)屬于結(jié)構(gòu)化的文本組織,但是又因?yàn)橐话阄覀冃枰年P(guān)鍵信息并非直接可以得到,需要進(jìn)行對(duì)HTML的解析查找,甚至一些字符串操作才能得到,所以還是歸類于非結(jié)構(gòu)化的數(shù)據(jù)處理中。
常見(jiàn)解析方式如下:
CSS選擇器
現(xiàn)在的網(wǎng)頁(yè)樣式比較多,所以一般的網(wǎng)頁(yè)都會(huì)有一些CSS的定位,例如class,id等等,或者我們根據(jù)常見(jiàn)的節(jié)點(diǎn)路徑進(jìn)行定位,例如騰訊首頁(yè)的財(cái)經(jīng)部分。

這里id就為finance,我們用css選擇器,就是”#finance”就得到了財(cái)經(jīng)這一塊區(qū)域的html,同理,可以根據(jù)特定的css選擇器可以獲取其他的內(nèi)容。
XPATH
XPATH是一種頁(yè)面元素的路徑選擇方法,利用Chrome可以快速得到,如:
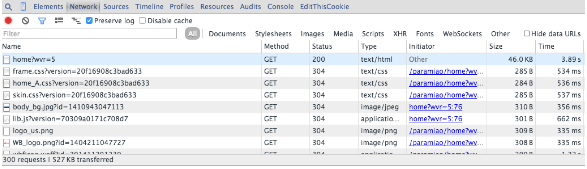
copy XPATH 就能得到——//*[@id=”finance”]
正則表達(dá)式
正則表達(dá)式,用標(biāo)準(zhǔn)正則解析,一般會(huì)把HTML當(dāng)做普通文本,用指定格式匹配當(dāng)相關(guān)文本,適合小片段文本,或者某一串字符,或者HTML包含javascript的代碼,無(wú)法用CSS選擇器或者XPATH。
字符串分隔
同正則表達(dá)式,更為偷懶的方法,不建議使用。
1.2 一段文本
例如一篇文章,或者一句話,我們的初衷是提取有效信息,所以如果是滯后處理,可以直接存儲(chǔ),如果是需要實(shí)時(shí)提取有用信息,常見(jiàn)的處理方式如下:
分詞
根據(jù)抓取的網(wǎng)站類型,使用不同詞庫(kù),進(jìn)行基本的分詞,然后變成詞頻統(tǒng)計(jì),類似于向量的表示,詞為方向,詞頻為長(zhǎng)度。
NLP
自然語(yǔ)言處理,進(jìn)行語(yǔ)義分析,用結(jié)果表示,例如正負(fù)面等。
2. 關(guān)于結(jié)構(gòu)化的數(shù)據(jù)
結(jié)構(gòu)化的數(shù)據(jù)是***處理,一般都是類似JSON格式的字符串,直接解析JSON數(shù)據(jù)就可以了,提取JSON的關(guān)鍵字段即可。
二、內(nèi)容從何而來(lái)
過(guò)去我們常需要獲取的內(nèi)容主要來(lái)源于網(wǎng)頁(yè),一般來(lái)講,我們決定進(jìn)行抓取的時(shí)候,都是網(wǎng)頁(yè)上可看到的內(nèi)容,但是隨著這幾年移動(dòng)互聯(lián)網(wǎng)的發(fā)展,我們也發(fā)現(xiàn)越來(lái)越多的內(nèi)容會(huì)來(lái)源于移動(dòng)App,所以爬蟲(chóng)就不止局限于一定要抓取解析網(wǎng)頁(yè),還有就是模擬移動(dòng)app的網(wǎng)絡(luò)請(qǐng)求進(jìn)行抓取,所以這一部分我會(huì)分兩部分進(jìn)行說(shuō)明。
1 網(wǎng)頁(yè)內(nèi)容
網(wǎng)頁(yè)內(nèi)容一般就是指我們最終在網(wǎng)頁(yè)上看到的內(nèi)容,但是這個(gè)過(guò)程其實(shí)并不是網(wǎng)頁(yè)的代碼里面直接包含內(nèi)容這么簡(jiǎn)單,所以對(duì)于很多新人而言,會(huì)遇到很多問(wèn)題,比如:
明明在頁(yè)面用Chrome或者Firefox進(jìn)行審查元素時(shí)能看到某個(gè)HTML標(biāo)簽下包含內(nèi)容,但是抓取的時(shí)候?yàn)榭铡?/p>
很多內(nèi)容一定要在頁(yè)面上點(diǎn)擊某個(gè)按鈕或者進(jìn)行某個(gè)交互操作才能顯示出來(lái)。
所以對(duì)于很多新人的做法是用某個(gè)語(yǔ)言別人模擬瀏覽器操作的庫(kù),其實(shí)就是調(diào)用本地瀏覽器或者是包含了一些執(zhí)行JavaScript的引擎來(lái)進(jìn)行模擬操作抓取數(shù)據(jù),但是這種做法顯然對(duì)于想要大量抓取數(shù)據(jù)的情況下是效率非常低下,并且對(duì)于技術(shù)人員本身而言也相當(dāng)于在用一個(gè)盒子,那么對(duì)于這些內(nèi)容到底是怎么顯示在網(wǎng)頁(yè)上的呢?主要分為以下幾種情況:
網(wǎng)頁(yè)包含內(nèi)容
這種情況是最容易解決的,一般來(lái)講基本上是靜態(tài)網(wǎng)頁(yè)已經(jīng)寫(xiě)死的內(nèi)容,或者動(dòng)態(tài)網(wǎng)頁(yè),采用模板渲染,瀏覽器獲取到HTML的時(shí)候已經(jīng)是包含所有的關(guān)鍵信息,所以直接在網(wǎng)頁(yè)上看到的內(nèi)容都可以通過(guò)特定的HTML標(biāo)簽得到。
JavaScript代碼加載內(nèi)容
這種情況是由于雖然網(wǎng)頁(yè)顯示時(shí),內(nèi)容在HTML標(biāo)簽里面,但是其實(shí)是由于執(zhí)行js代碼加到標(biāo)簽里面的,所以這個(gè)時(shí)候內(nèi)容在js代碼里面的,而js的執(zhí)行是在瀏覽器端的操作,所以用程序去請(qǐng)求網(wǎng)頁(yè)地址的時(shí)候,得到的response是網(wǎng)頁(yè)代碼和js的代碼,所以自己在瀏覽器端能看到內(nèi)容,解析時(shí)由于js未執(zhí)行,肯定找到指定HTML標(biāo)簽下內(nèi)容肯定為空,這個(gè)時(shí)候的處理辦法,一般來(lái)講主要是要找到包含內(nèi)容的js代碼串,然后通過(guò)正則表達(dá)式獲得相應(yīng)的內(nèi)容,而不是解析HTML標(biāo)簽。
Ajax異步請(qǐng)求
這種情況是現(xiàn)在很常見(jiàn)的,尤其是在內(nèi)容以分頁(yè)形式顯示在網(wǎng)頁(yè)上,并且頁(yè)面無(wú)刷新,或者是對(duì)網(wǎng)頁(yè)進(jìn)行某個(gè)交互操作后,得到內(nèi)容。那我們?cè)撊绾畏治鲞@些請(qǐng)求呢?這里我以Chrome的操作為例,進(jìn)行說(shuō)明:
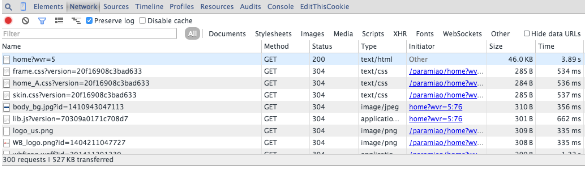
所以當(dāng)我們開(kāi)始刷新頁(yè)面的時(shí)候就要開(kāi)始跟蹤所有的請(qǐng)求,觀察數(shù)據(jù)到底是在哪一步加載進(jìn)來(lái)的。然后當(dāng)我們找到核心的異步請(qǐng)求的時(shí)候,就只用抓取這個(gè)異步請(qǐng)求就可以了,如果原始網(wǎng)頁(yè)沒(méi)有任何有用信息,也沒(méi)必要去抓取原始網(wǎng)頁(yè)了。
2 App內(nèi)容
因?yàn)楝F(xiàn)在移動(dòng)應(yīng)用越來(lái)越多,很多有用信息都在App里面,另外解析非結(jié)構(gòu)化文本和結(jié)構(gòu)文本對(duì)比而言,結(jié)構(gòu)化文本會(huì)簡(jiǎn)單多了,不同去找內(nèi)容,去過(guò)多分析解析,所有既有網(wǎng)站又有App的話,推薦抓取App,大多數(shù)情況下基本上只是一些JSON數(shù)據(jù)的API了。
那么App的數(shù)據(jù)該如何抓取呢?通用的方法就是抓包,基本的做法就是電腦安裝抓包軟件,配置好端口,然后記下ip,手機(jī)端和電腦在同一個(gè)局域網(wǎng)里面,然后在手機(jī)的網(wǎng)絡(luò)連接里面設(shè)置好代理,這個(gè)時(shí)候打開(kāi)App進(jìn)行一些操作,如果有網(wǎng)絡(luò)數(shù)據(jù)請(qǐng)求,則都會(huì)被抓包軟件記下,就如上Chrome分析網(wǎng)絡(luò)請(qǐng)求一樣,你可以看到所有的請(qǐng)求情況,可以模擬請(qǐng)求操作。這里Mac上我推薦軟件Charles,Windows推薦Fiddler2。
具體如何使用,之后我再做詳述,可能會(huì)涉及到HTTPS證書(shū)的問(wèn)題。
三、了解網(wǎng)絡(luò)請(qǐng)求
剛剛一直在寬泛的提到一些我們需要找到請(qǐng)求,進(jìn)行請(qǐng)求,對(duì)于請(qǐng)求只是一筆帶過(guò),但請(qǐng)求是很重要的一部分,包括如何繞過(guò)限制,如何發(fā)送正確地?cái)?shù)據(jù),都需要對(duì)的請(qǐng)求,這里就要詳細(xì)的展開(kāi)說(shuō)下請(qǐng)求,以及如何模擬請(qǐng)求。
我們常說(shuō)爬蟲(chóng)其實(shí)就是一堆的HTTP請(qǐng)求,找到待爬取的鏈接,不管是網(wǎng)頁(yè)鏈接還是App抓包得到的API鏈接,然后發(fā)送一個(gè)請(qǐng)求包,得到一個(gè)返回包(也有HTTP長(zhǎng)連接,或者Streaming的情況,這里不考慮),所以核心的幾個(gè)要素就是:
URL
請(qǐng)求方法(POST, GET)
請(qǐng)求包headers
請(qǐng)求包內(nèi)容
返回包headers
在用Chrome進(jìn)行網(wǎng)絡(luò)請(qǐng)求捕獲或者用抓包工具分析請(qǐng)求時(shí),最重要的是弄清楚URL,請(qǐng)求方法,然后headers里面的字段,大多數(shù)出問(wèn)題就出在headers里面,最常限制的幾個(gè)字段就是User-Agent, Referer, Cookie 另外Base Auth也是在headers里面加了Autheration的字段。
請(qǐng)求內(nèi)容也就是post時(shí)需要發(fā)送的數(shù)據(jù),一般都是將Key-Value進(jìn)行urlencode。返回包headers大多數(shù)會(huì)被人忽視,可能只得到內(nèi)容就可以了,但是其實(shí)很多時(shí)候,很多人會(huì)發(fā)現(xiàn)明明url,請(qǐng)求方法還有請(qǐng)求包的內(nèi)容都對(duì)了,為什么沒(méi)有返回內(nèi)容,或者發(fā)現(xiàn)請(qǐng)求被限制,其實(shí)這里大概有兩個(gè)原因:
一個(gè)是返回包的內(nèi)容是空的,但是在返回包的headers的字段里面有個(gè)Location,這個(gè)Location字段就是告訴瀏覽器重定向,所以有時(shí)候代碼沒(méi)有自動(dòng)跟蹤,自然就沒(méi)有內(nèi)容了;
另外一個(gè)就是很多人會(huì)頭疼的Cookie問(wèn)題,簡(jiǎn)單說(shuō)就是瀏覽器為什么知道你的請(qǐng)求合法的,例如已登錄等等,其實(shí)就是可能你之前某個(gè)請(qǐng)求的返回包的headers里面有個(gè)字段叫Set-Cookie,Cookie存在本地,一旦設(shè)置后,除非過(guò)期,一般都會(huì)自動(dòng)加在請(qǐng)求字段上,所以Set-Cookie里面的內(nèi)容就會(huì)告訴瀏覽器存多久,存的是什么內(nèi)容,在哪個(gè)路徑下有用,Cookie都是在指定域下,一般都不跨域,域就是你請(qǐng)求的鏈接host。
所以分析請(qǐng)求時(shí),一定要注意前四個(gè),在模擬時(shí)保持一致,同時(shí)觀察第五個(gè)返回時(shí)是不是有限制或者有重定向。
四、一些常見(jiàn)的限制方式
上述都是講的都是一些的基礎(chǔ)的知識(shí),現(xiàn)在我就列一些比較常見(jiàn)的限制方式,如何突破這些限制抓取數(shù)據(jù)。
Basic Auth
一般會(huì)有用戶授權(quán)的限制,會(huì)在headers的Autheration字段里要求加入;
Referer
通常是在訪問(wèn)鏈接時(shí),必須要帶上Referer字段,服務(wù)器會(huì)進(jìn)行驗(yàn)證,例如抓取京東的評(píng)論;
User-Agent
會(huì)要求真是的設(shè)備,如果不加會(huì)用編程語(yǔ)言包里自有User-Agent,可以被辨別出來(lái);
Cookie
一般在用戶登錄或者某些操作后,服務(wù)端會(huì)在返回包中包含Cookie信息要求瀏覽器設(shè)置Cookie,沒(méi)有Cookie會(huì)很容易被辨別出來(lái)是偽造請(qǐng)求;
也有本地通過(guò)JS,根據(jù)服務(wù)端返回的某個(gè)信息進(jìn)行處理生成的加密信息,設(shè)置在Cookie里面;
Gzip
請(qǐng)求headers里面帶了gzip,返回有時(shí)候會(huì)是gzip壓縮,需要解壓;
JavaScript加密操作
一般都是在請(qǐng)求的數(shù)據(jù)包內(nèi)容里面會(huì)包含一些被javascript進(jìn)行加密限制的信息,例如新浪微博會(huì)進(jìn)行SHA1和RSA加密,之前是兩次SHA1加密,然后發(fā)送的密碼和用戶名都會(huì)被加密;
其他字段
因?yàn)閔ttp的headers可以自定義地段,所以第三方可能會(huì)加入了一些自定義的字段名稱或者字段值,這也是需要注意的。
真實(shí)的請(qǐng)求過(guò)程中,其實(shí)不止上面某一種限制,可能是幾種限制組合在一次,比如如果是類似RSA加密的話,可能先請(qǐng)求服務(wù)器得到Cookie,然后再帶著Cookie去請(qǐng)求服務(wù)器拿到公鑰,然后再用js進(jìn)行加密,再發(fā)送數(shù)據(jù)到服務(wù)器。所以弄清楚這其中的原理,并且耐心分析很重要。
五、嘗試解決問(wèn)題的思路
首先大的地方,加入我們想抓取某個(gè)數(shù)據(jù)源,我們要知道大概有哪些路徑可以獲取到數(shù)據(jù)源,基本上無(wú)外乎三種:
PC端網(wǎng)站;
針對(duì)移動(dòng)設(shè)備響應(yīng)式設(shè)計(jì)的網(wǎng)站(也就是很多人說(shuō)的H5, 雖然不一定是H5);
移動(dòng)App;
原則是能抓移動(dòng)App的,***抓移動(dòng)App,如果有針對(duì)移動(dòng)設(shè)備優(yōu)化的網(wǎng)站,就抓針對(duì)移動(dòng)設(shè)備優(yōu)化的網(wǎng)站,***考慮PC網(wǎng)站。因?yàn)橐苿?dòng)App基本都是API很簡(jiǎn)單,而移動(dòng)設(shè)備訪問(wèn)優(yōu)化的網(wǎng)站一般來(lái)講都是結(jié)構(gòu)簡(jiǎn)單清晰的HTML,而PC網(wǎng)站自然是最復(fù)雜的了;
針對(duì)PC端網(wǎng)站和移動(dòng)網(wǎng)站的做法一樣,分析思路可以一起講,移動(dòng)App單獨(dú)分析。
1 網(wǎng)站類型的分析
首先是網(wǎng)站類的,使用的工具就是Chrome,建議用Chrome的隱身模式,分析時(shí)不用頻繁清楚cookie,直接關(guān)閉窗口就可以了。
具體操作步驟如下:
輸入網(wǎng)址后,先不要回車確認(rèn),右鍵選擇審查元素,然后點(diǎn)擊網(wǎng)絡(luò),記得要勾上preserve log選項(xiàng),因?yàn)槿绻霈F(xiàn)上面提到過(guò)的重定向跳轉(zhuǎn),之前的請(qǐng)求全部都會(huì)被清掉,影響分析,尤其是重定向時(shí)還加上了Cookie;
接下來(lái)觀察網(wǎng)絡(luò)請(qǐng)求列表,資源文件,例如css,圖片基本都可以忽略,***個(gè)請(qǐng)求肯定就是該鏈接的內(nèi)容本身,所以查看源碼,確認(rèn)頁(yè)面上需要抓取的內(nèi)容是不是在HTML標(biāo)簽里面,很簡(jiǎn)單的方法,找到自己要找的內(nèi)容,看到父節(jié)點(diǎn),然后再看源代碼里面該父節(jié)點(diǎn)里面有沒(méi)有內(nèi)容,如果沒(méi)有,那么一定是異步請(qǐng)求,如果是非異步請(qǐng)求,直接抓該鏈接就可以了。
分析異步請(qǐng)求,按照網(wǎng)絡(luò)列表,略過(guò)資源文件,然后點(diǎn)擊各個(gè)請(qǐng)求,觀察是否在返回時(shí)包含想要的內(nèi)容,有幾個(gè)方法:
內(nèi)容比較有特點(diǎn),例如人的屬性信息,物品的價(jià)格,或者微博列表等內(nèi)容,直接觀察可以判斷是不是該異步請(qǐng)求;
知道異步加載的內(nèi)容節(jié)點(diǎn)或者父節(jié)點(diǎn)的class或者id的名稱,找到j(luò)s代碼,閱讀代碼得到異步請(qǐng)求;
確認(rèn)異步請(qǐng)求之后,就是要分析異步請(qǐng)求了,簡(jiǎn)單的,直接請(qǐng)求異步請(qǐng)求,能得到數(shù)據(jù),但是有時(shí)候異步請(qǐng)求會(huì)有限制,所以現(xiàn)在分析限制從何而來(lái)。
針對(duì)分析對(duì)請(qǐng)求的限制,思路是逆序方法。
先找到***一個(gè)得到內(nèi)容的請(qǐng)求,然后觀察headers,先看post數(shù)據(jù)或者url的某個(gè)參數(shù)是不是都是已知數(shù)據(jù),或者有意義數(shù)據(jù),如果發(fā)現(xiàn)不確定的先帶上,只是更改某個(gè)關(guān)鍵字段,例如page,count看結(jié)果是不是會(huì)正常,如果不正常,比如多了個(gè)token,或者某個(gè)字段明顯被加密,例如用戶名密碼,那么接下來(lái)就要看JS的代碼,看到底是哪個(gè)函數(shù)進(jìn)行了加密,一般會(huì)是原生JS代碼加密,那么看到代碼,直接加密就行,如果是類似RSA加密,那么就要看公鑰是從何而來(lái),如果是請(qǐng)求得到的,那么就要往上分析請(qǐng)求,另外如果是發(fā)現(xiàn)請(qǐng)求headers里面有陌生字段,或者有Cookie也要往上看請(qǐng)求,Cookie在哪一步設(shè)置的;
接下來(lái)找到剛剛那個(gè)請(qǐng)求未知來(lái)源的信息,例如Cookie或者某個(gè)加密需要的公鑰等等,看看上面某個(gè)請(qǐng)求是不是已經(jīng)包含,依次類推。
2 App的分析
然后是App類的,使用的工具是Charles,手機(jī)和電腦在一個(gè)局域網(wǎng)內(nèi),先用Charles配置好端口,然后手機(jī)設(shè)置代理,ip為電腦的ip,端口為設(shè)置的端口,然后如果手機(jī)上請(qǐng)求網(wǎng)絡(luò)內(nèi)容時(shí),Charles會(huì)顯示相應(yīng)地請(qǐng)求,那么就ok了,分析的大體邏輯基本一致,限制會(huì)相對(duì)少很多,但是也有幾種情況需要注意:
加密,App有時(shí)候也有一些加密的字段,這個(gè)時(shí)候,一般來(lái)講都會(huì)進(jìn)行反編譯進(jìn)行分析,找到對(duì)應(yīng)的代碼片段,逆推出加密方法;
gzip壓縮或者base64編碼,base64編碼的辨別度較高,有時(shí)候數(shù)據(jù)被gzip壓縮了,不過(guò)Charles都是有自動(dòng)解密的;
https證書(shū),有的https請(qǐng)求會(huì)驗(yàn)證證書(shū),Charles提供了證書(shū),可以在官網(wǎng)找到,手機(jī)訪問(wèn),然后信任添加就可以。
六、效率問(wèn)題的取舍
一般來(lái)講在抓取大量數(shù)據(jù),例如全網(wǎng)抓取京東的評(píng)論,微博所有人的信息,微博信息,關(guān)注關(guān)系等等,這種上十億到百億次設(shè)置千億次的請(qǐng)求必須考慮效率,否者一天只有86400秒,那么一秒鐘要抓100次,一天也才864w次請(qǐng)求,也需要100多天才能到達(dá)十億級(jí)別的請(qǐng)求量。
涉及到大規(guī)模的抓取,一定要有良好的爬蟲(chóng)設(shè)計(jì),一般很多開(kāi)源的爬蟲(chóng)框架也都是有限制的,因?yàn)橹虚g涉及到很多其他的問(wèn)題,例如數(shù)據(jù)結(jié)構(gòu),重復(fù)抓取過(guò)濾的問(wèn)題,當(dāng)然最重要的是要把帶寬利用滿,所以分布式抓取很重要,接下來(lái)我會(huì)有一篇專門(mén)講分布式的爬蟲(chóng)設(shè)計(jì),分布式最重要的就是中間消息通信,如果想要抓的越多越快,那么對(duì)中間的消息系統(tǒng)的吞吐量要求也越高。
但是對(duì)于一些不太大規(guī)模的抓取就沒(méi)要用分布式的一套,比較消耗時(shí)間,基本只要保證單機(jī)器的帶寬能夠利用滿就沒(méi)問(wèn)題,所以做好并發(fā)就可以,另外對(duì)于數(shù)據(jù)結(jié)構(gòu)也要有一定的控制,很多人寫(xiě)程序,內(nèi)存越寫(xiě)越大,抓取越來(lái)越慢,可能存在的原因就包括,一個(gè)是用了內(nèi)存存一些數(shù)據(jù)沒(méi)有進(jìn)行釋放,第二個(gè)可能有一些hashset的判斷,***判斷的效率越來(lái)越低,比如用bloomfilter替換就會(huì)優(yōu)化很多。