一文看懂神經(jīng)網(wǎng)絡(luò)工作原理
本文帶來對深度神經(jīng)網(wǎng)絡(luò)的通俗介紹。
現(xiàn)在談人工智能已經(jīng)繞不開“神經(jīng)網(wǎng)絡(luò)”這個詞了。人造神經(jīng)網(wǎng)絡(luò)粗線條地模擬人腦,使得計算機能夠從數(shù)據(jù)中學(xué)習(xí)。
機器學(xué)習(xí)這一強大的分支結(jié)束了 AI 的寒冬,迎來了人工智能的新時代。簡而言之,神經(jīng)網(wǎng)絡(luò)可能是今天***有根本顛覆性的技術(shù)。
看完這篇神經(jīng)網(wǎng)絡(luò)的指南,你也可以和別人聊聊深度學(xué)習(xí)了。為此,我們將盡量不用數(shù)學(xué)公式,而是盡可能用打比方的方法,再加一些動畫來說明。
強力思考
AI 的早期流派之一認(rèn)為,如果您將盡可能多的信息加載到功能強大的計算機中,并盡可能多地提供方法來了解這些數(shù)據(jù),那么計算機就應(yīng)該能夠“思考”。比如 IBM 著名的國際象棋 AI Deep Blue 背后就是這么一個思路:通過對棋子可能走出的每一步進(jìn)行編程,再加上足夠的算力,IBM 程序員創(chuàng)建了一臺機器,理論上可以計算出每一個可能的動作和結(jié)果,以此來擊敗對手。
通過這種計算,機器依賴于工程師精心預(yù)編程的固定規(guī)則——如果發(fā)生了 A,那么就會發(fā)生 B ; 如果發(fā)生了 C,就做 D——這并不是如人類一樣的靈活學(xué)習(xí)。當(dāng)然,它是強大的超級計算,但不是“思考”本身。
教機器學(xué)習(xí)
在過去十年中,科學(xué)家已經(jīng)復(fù)活了一個舊概念,不再依賴大型百科全書式記憶庫,而是框架性地進(jìn)行模擬人類思維,以簡單而系統(tǒng)的方式分析輸入數(shù)據(jù)。 這種技術(shù)被稱為深度學(xué)習(xí)或神經(jīng)網(wǎng)絡(luò),自20世紀(jì)40年代以來一直存在,但是由于今天數(shù)據(jù)的大量增長—— 圖像、視頻、語音搜索、瀏覽行為等等——以及運算能力提升而成本下降的處理器,終于開始顯示其真正的威力。
機器——它們和我們很像
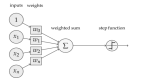
人工神經(jīng)網(wǎng)絡(luò)(ANN)是一種算法結(jié)構(gòu),使得機器能夠?qū)W習(xí)一切,從語音命令、播放列表到音樂創(chuàng)作和圖像識別。典型的 ANN 由數(shù)千個互連的人造神經(jīng)元組成,它們按順序堆疊在一起,以稱為層的形式形成數(shù)百萬個連接。在許多情況下,層僅通過輸入和輸出與它們之前和之后的神經(jīng)元層互連。(這與人類大腦中的神經(jīng)元有很大的不同,它們的互連是全方位的。)
網(wǎng)絡(luò)工作原理")
這種分層的 ANN 是今天機器學(xué)習(xí)的主要方式之一,通過饋送其大量的標(biāo)簽數(shù)據(jù),可以幫助它學(xué)習(xí)如何解讀數(shù)據(jù)(有時甚至比人類做得更好)。
以圖像識別為例,它依賴于稱為卷積神經(jīng)網(wǎng)絡(luò)(CNN)的特定類型的神經(jīng)網(wǎng)絡(luò),因為它使用稱為卷積的數(shù)學(xué)過程來以非文字的方式分析圖像, 例如識別部分模糊的對象或僅從某些角度可見的對象。 (還有其他類型的神經(jīng)網(wǎng)絡(luò),包括循環(huán)神經(jīng)網(wǎng)絡(luò)和前饋神經(jīng)網(wǎng)絡(luò),但是這些神經(jīng)網(wǎng)絡(luò)對于識別諸如圖像的東西不太有用,下面我們會用示例來說明)
神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程
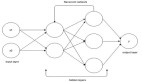
那么神經(jīng)網(wǎng)絡(luò)到底是如何學(xué)習(xí)的? 讓我們看一個非常簡單但有效的流程,它叫作監(jiān)督學(xué)習(xí)。我們?yōu)樯窠?jīng)網(wǎng)絡(luò)提供了大量的人類標(biāo)記的訓(xùn)練數(shù)據(jù),以便神經(jīng)網(wǎng)絡(luò)可以進(jìn)行基本的自我檢查。
假設(shè)這個標(biāo)簽數(shù)據(jù)分別由蘋果和橘子的圖片組成。照片是數(shù)據(jù);“蘋果”和“橘子”是標(biāo)簽。當(dāng)輸入圖像數(shù)據(jù)時,網(wǎng)絡(luò)將它們分解為最基本的組件,即邊緣、紋理和形狀。當(dāng)圖像數(shù)據(jù)在網(wǎng)絡(luò)中傳遞時,這些基本組件被組合以形成更抽象的概念,即曲線和不同的顏色,這些元素在進(jìn)一步組合時,就開始看起來像莖、整個的橘子,或是綠色和紅色的蘋果。
在這個過程的***,網(wǎng)絡(luò)試圖對圖片中的內(nèi)容進(jìn)行預(yù)測。首先,這些預(yù)測將顯示為隨機猜測,因為真正的學(xué)習(xí)還未發(fā)生。如果輸入圖像是蘋果,但預(yù)測為“橘子”,則網(wǎng)絡(luò)的內(nèi)部層需要被調(diào)整。
調(diào)整的過程稱為反向傳播,以增加下一次將同一圖像預(yù)測成“蘋果”的可能性。這一過程持續(xù)進(jìn)行,直到預(yù)測的準(zhǔn)確度不再提升。正如父母教孩子們在現(xiàn)實生活中認(rèn)蘋果和橘子一樣,對于計算機來說,訓(xùn)練造就***。如果你現(xiàn)在已經(jīng)覺得“這不就是學(xué)習(xí)嗎?”,那你可能很適合搞人工智能。
很多很多層……
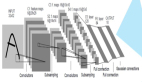
通常,卷積神經(jīng)網(wǎng)絡(luò)除了輸入和輸出層之外還有四個基本的神經(jīng)元層:
- 卷積層(Convolution)
- 激活層(Activation)
- 池化層(Pooling)
- 完全連接層(Fully connected)
卷積層
在最初的卷積層中,成千上萬的神經(jīng)元充當(dāng)***組過濾器,搜尋圖像中的每個部分和像素,找出模式(pattern)。隨著越來越多的圖像被處理,每個神經(jīng)元逐漸學(xué)習(xí)過濾特定的特征,這提高了準(zhǔn)確性。
比如圖像是蘋果,一個過濾器可能專注于發(fā)現(xiàn)“紅色”這一顏色,而另一個過濾器可能會尋找圓形邊緣,另一個過濾器則會識別細(xì)細(xì)的莖。如果你要清理混亂的地下室,準(zhǔn)備在車庫搞個大銷售,你就能理解把一切按不同的主題分類是什么意思了(玩具、電子產(chǎn)品、藝術(shù)品、衣服等等)。 卷積層就是通過將圖像分解成不同的特征來做這件事的。
特別強大的是,神經(jīng)網(wǎng)絡(luò)賴以成名的絕招與早期的 AI 方法(比如 Deep Blue 中用到的)不同,這些過濾器不是人工設(shè)計的。他們純粹是通過查看數(shù)據(jù)來學(xué)習(xí)和自我完善。
卷積層創(chuàng)建了不同的、細(xì)分的圖像版本,每個專用于不同的過濾特征——顯示其神經(jīng)元在哪里看到了紅色、莖、曲線和各種其他元素的實例(但都是部分的) 。但因為卷積層在識別特征方面相當(dāng)自由,所以需要額外的一雙眼睛,以確保當(dāng)圖片信息在網(wǎng)絡(luò)中傳遞時,沒有任何有價值的部分被遺漏。
神經(jīng)網(wǎng)絡(luò)的一個優(yōu)點是它們能夠以非線性的方式學(xué)習(xí)。如果不用數(shù)學(xué)術(shù)語解釋,它們的意思是能夠發(fā)現(xiàn)不太明顯的圖像中的特征——樹上的蘋果,陽光下的,陰影下的,或廚房柜臺的碗里的。這一切都要歸功于于激活層,它或多或少地突出了有價值的東西——一些既明了又難以發(fā)現(xiàn)的屬性。
在我們的車庫大甩賣中,想像一下,從每一類東西里我們都挑選了幾件珍貴的寶物:書籍,大學(xué)時代的經(jīng)典 T 恤。要命的是,我們可能還不想扔它們。我們把這些“可能”會留下的物品放在它們各自的類別之上,以備再考慮。
池化層
整個圖像中的這種“卷積”會產(chǎn)生大量的信息,這可能會很快成為一個計算噩夢。進(jìn)入池化層,可將其全部縮小成更通用和可消化的形式。有很多方法可以解決這個問題,但***的是“***池”(Max Pooling),它將每個特征圖編輯成自己的“讀者文摘”版本,因此只有紅色、莖或曲線的***樣本被表征出來。
在車庫春季清理的例子中,如果我們使用著名的日本清理大師 Marie Kondo 的原則,將不得不從每個類別堆中較小的收藏夾里選擇“激發(fā)喜悅”的東西,然后賣掉或處理掉其他東西。 所以現(xiàn)在我們?nèi)匀话凑瘴锲奉愋蛠矸诸悾话▽嶋H想要保留的物品。其他一切都賣了。
這時,神經(jīng)網(wǎng)絡(luò)的設(shè)計師可以堆疊這一分類的后續(xù)分層配置——卷積、激活、池化——并且繼續(xù)過濾圖像以獲得更高級別的信息。在識別圖片中的蘋果時,圖像被一遍又一遍地過濾,初始層僅顯示邊緣的幾乎不可辨別的部分,比如紅色的一部分或僅僅是莖的***,而隨后的更多的過濾層將顯示整個蘋果。無論哪種方式,當(dāng)開始獲取結(jié)果時,完全連接層就會起作用。
網(wǎng)絡(luò)工作原理")
完全連接層
現(xiàn)在是時候得出結(jié)果了。在完全連接層中,每個削減的或“池化的”特征圖“完全連接”到表征了神經(jīng)網(wǎng)絡(luò)正在學(xué)習(xí)識別的事物的輸出節(jié)點(神經(jīng)元)上。 如果網(wǎng)絡(luò)的任務(wù)是學(xué)習(xí)如何發(fā)現(xiàn)貓、狗、豚鼠和沙鼠,那么它將有四個輸出節(jié)點。 在我們描述的神經(jīng)網(wǎng)絡(luò)中,它將只有兩個輸出節(jié)點:一個用于“蘋果”,一個用于“橘子”。
如果通過網(wǎng)絡(luò)饋送的圖像是蘋果,并且網(wǎng)絡(luò)已經(jīng)進(jìn)行了一些訓(xùn)練,且隨著其預(yù)測而變得越來越好,那么很可能一個很好的特征圖塊就是包含了蘋果特征的高質(zhì)量實例。 這是最終輸出節(jié)點實現(xiàn)使命的地方,反之亦然。
“蘋果”和“橘子”節(jié)點的工作(他們在工作中學(xué)到的)基本上是為包含其各自水果的特征圖“投票”。因此,“蘋果”節(jié)點認(rèn)為某圖包含“蘋果”特征越多,它給該特征圖的投票就越多。兩個節(jié)點都必須對每個特征圖進(jìn)行投票,無論它包含什么。所以在這種情況下,“橘子”節(jié)點不會向任何特征圖投很多票,因為它們并不真正包含任何“橘子”的特征。***,投出最多票數(shù)的節(jié)點(在本例中為“蘋果”節(jié)點)可以被認(rèn)為是網(wǎng)絡(luò)的“答案”,盡管事實上可能不那么簡單。
因為同一個網(wǎng)絡(luò)正在尋找兩個不同的東西——蘋果和橘子——網(wǎng)絡(luò)的最終輸出以百分比表示。在這種情況下,我們假設(shè)網(wǎng)絡(luò)在訓(xùn)練中表現(xiàn)已經(jīng)有所下降了,所以這里的預(yù)測可能就是75%的“蘋果”,25%的“橘子”。或者如果是在訓(xùn)練早期,可能會更加不正確,它可能是20%的“蘋果”和80%的“橘子”。這可不妙。
網(wǎng)絡(luò)工作原理")
如果一開始沒成功,再試,再試…
所以,在早期階段,神經(jīng)網(wǎng)絡(luò)可能會以百分比的形式給出一堆錯誤的答案。 20%的“蘋果”和80%的“橘子”,預(yù)測顯然是錯誤的,但由于這是使用標(biāo)記的訓(xùn)練數(shù)據(jù)進(jìn)行監(jiān)督學(xué)習(xí),所以網(wǎng)絡(luò)能夠通過稱為“反向傳播”的過程來進(jìn)行系統(tǒng)調(diào)整。
避免用數(shù)學(xué)術(shù)語來說,反向傳播將反饋發(fā)送到上一層的節(jié)點,告訴它答案差了多少。然后,該層再將反饋發(fā)送到上一層,再傳到上一層,直到它回到卷積層,來進(jìn)行調(diào)整,以幫助每個神經(jīng)元在隨后的圖像在網(wǎng)絡(luò)中傳遞時更好地識別數(shù)據(jù)。
這個過程一直反復(fù)進(jìn)行,直到神經(jīng)網(wǎng)絡(luò)以更準(zhǔn)確的方式識別圖像中的蘋果和橘子,最終以100%的正確率預(yù)測結(jié)果——盡管許多工程師認(rèn)為85%是可以接受的。這時,神經(jīng)網(wǎng)絡(luò)已經(jīng)準(zhǔn)備好了,可以開始真正識別圖片中的蘋果了。
注:谷歌 AlphaGo 用自學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)評估棋盤位置的方法和我們介紹的方法仍有不同。