用Python挖掘Twitter數據:數據采集
這是7部系列中的第1部分,注重挖掘Twitter數據以用于各種案例。這是***篇文章,專注于數據采集,起到奠定基礎的作用。
Twitter是一個流行的社交網絡,用戶可以共享稱為tweets的類似SMS的短消息。用戶在Twitter上分享想法、鏈接和圖片,記者發表現場活動評論,企業改進產品和吸引客戶等等。使用Twitter的不同的方式列表可能會很長,伴隨著每天5億的tweets,這里有大量的數據等著我們分析。
這是一系列使用Python專門用于Twitter數據挖掘的文章中的***篇。在***部分中,我們將看到通過不同的方式來進行Twitter的數據收集。一旦我們建立好了一個數據集,在接下來的環節中,我們就將會討論一些有趣的數據應用。
注冊應用
為了能夠訪問Twitter數據編程,我們需要創建一個與Twitter的API交互的應用程序。
***步是注冊一個你的應用程序。值得注意的是,您需要將您的瀏覽器轉到http://apps.twitter.com,登錄到Twitter(如果您尚未登錄),并注冊一個新的應用程序。您現在可以為您的應用程序選擇一個名稱和說明(例如“挖掘演示”或類似)。您將收到一個消費者密鑰和消費者密碼:這些都是應用程序設置,應始終保密。在您的應用程序的配置頁面,你也可以要求獲取一個訪問令牌和訪問令牌的密碼。類似于消費者密鑰,這些字符串也必須保密:他們提供的應用程序是代表您的帳戶訪問到Twitter。默認權限是只讀的,這是我們在案例中需要的,但如果你決定改變您的許可,在應用中提供更改功能,你就必須再獲得一個新的訪問令牌。
重要提示:使用Twitter的API時有速率限制,或者你想要提供一個可下載的數據集也會有限制,請參見: >
您可以使用 Twitter提供的REST APIs與他們的服務進行交互。那里還有一群基于Python的客戶,我們可以重復循環使用。尤其Tweepy是其中最有趣和最直白的一個,所以我們一起把它安裝起來:
更新:Tweepy發布的3.4.0版本在Python3上出現了一些問題,目前被綁定在GitHub上還不能進行使用,因此在新的版本出來之前,我們一直使用3.3.0版本。
更多的更新:Tweepy發布的3.5.0版本已經可以使用,似乎解決了上述提到的在Python3上的問題。
為了授權我們的應用程序以代表我們訪問Twitter,我們需要使用OAuth的界面:

現在的API變量是我們為可以在Twitter上執行的大多數操作的入口點。
例如,我們可以看到我們自己的時間表(或者我們的Twitter主頁):

Tweepy提供便捷的光標接口,對不同類型的對象進行迭代。在上面的例子中我們用10來限制我們正在閱讀的tweets的數量,但是當然其實我們是可以訪問更多的。狀態變量是Status() class的一個實例,是訪問數據時一個漂亮的包裝。Twitter API的JSON響應在_json屬性(帶有前導下劃線)上是可用的,它不是純JSON字符串,而是一個字典。
所以上面的代碼可以被重新寫入去處理/存儲JSON:

如果我們想要一個所有用戶的名單?來這里:

那么我們所有的tweets的列表呢? 也很簡單:

通過這種方式,我們可以很容易地收集tweets(以及更多),并將它們存儲為原始的JSON格式,可以很方便的依據我們的存儲格式將其轉換為不同的數據模型(很多NoSQL技術提供一些批量導入功能)。
process_or_store()功能是您的自定義實施占位符。最簡單的方式就是你可以只打印出JSON,每行一個tweet:

流
如果我們要“保持連接”,并收集所有關于特定事件將會出現的tweets,流API就是我們所需要的。我們需要擴展StreamListener()來定義我們處理輸入數據的方式。一個用#python hashtag收集了所有新的tweet的例子:
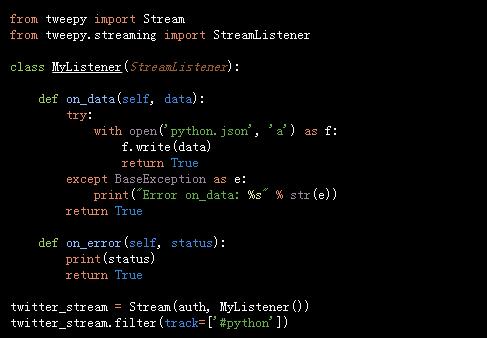
根據不同的搜索詞,我們可以在幾分鐘之內收集到成千上萬的tweet。世界性覆蓋的現場活動尤其如此(世界杯、超級杯、奧斯卡頒獎典禮等),所以保持關注JSON文件,看看它增長的速度是多么的快,并考量你的測試可能需要多少tweet。以上腳本將把每個tweet保存在新的行中,所以你可以從Unix shell中使用wc-l python.json命令來了解到你收集了多少tweet。
你可以在下面的要點中看到Twitter的API流的一個最小工作示例:
twitter_stream_downloader.py
總結
我們已經介紹了tweepy作為通過Python訪問Twitter數據的一個相當簡單的工具。我們可以根據明確的“tweet”項目目標收集一些不同類型的數據。
一旦我們收集了一些數據,在分析應用方面的就可以進行展開了。在接下來的內容中,我們將討論部分問題。
簡介:Marco Bonzanini是英國倫敦的一個數據科學家。活躍于PyData社區的他喜歡從事文本分析和數據挖掘的應用工作。他是“用Python掌握社會化媒體挖掘”( 2016月7月出版)的作者。