













玩C一定用得到的19款Java開源Web爬蟲
網絡爬蟲(又被稱為網頁蜘蛛,網絡機器人,在FOAF社區中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本。另外一些不常使用的名字還有螞蟻、自動索引、模擬程序或者蠕蟲。
今天將為大家介紹19款Java開源Web爬蟲,需要的小伙伴們趕快收藏吧。
一、Heritrix
Heritrix 是一個由 java 開發的、開源的網絡爬蟲,用戶可以使用它來從網上抓取想要的資源。其最出色之處在于它良好的可擴展性,方便用戶實現自己的抓取邏輯。
Heritrix 是個“Archival Crawler”——來獲取完整的、精確的、站點內容的深度復制。包括獲取圖像以及其他非文本內容。抓取并存儲相關的內容。對內容來者不拒,不對頁面進行內容上的修改。重新爬行對相同的URL不針對先前的進行替換。爬蟲主要通過Web用戶界面啟動、監控和調整,允許彈性的定義要獲取的url。
Heritrix是按多線程方式抓取的爬蟲,主線程把任務分配給Teo線程(處理線程),每個Teo線程每次處理一個URL。Teo線程對每個URL執行一遍URL處理器鏈。URL處理器鏈包括如下5個處理步驟。
(1)預取鏈:主要是做一些準備工作,例如,對處理進行延遲和重新處理,否決隨后的操作。
(2)提取鏈:主要是下載網頁,進行DNS轉換,填寫請求和響應表單。
(3)抽取鏈:當提取完成時,抽取感興趣的HTML和JavaScript,通常那里有新的要抓取的URL。
(4)寫鏈:存儲抓取結果,可以在這一步直接做全文索引。Heritrix提供了用ARC格式保存下載結果的ARCWriterProcessor實現。
(5)提交鏈:做和此URL相關操作的最后處理。檢查哪些新提取出的URL在抓取范圍內,然后把這些URL提交給Frontier。另外還會更新DNS緩存信息。
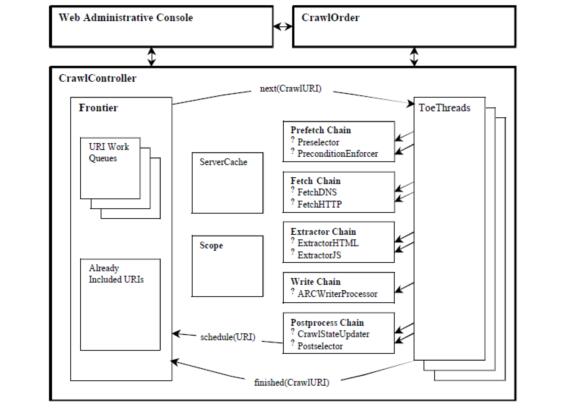
Heritrix系統框架圖
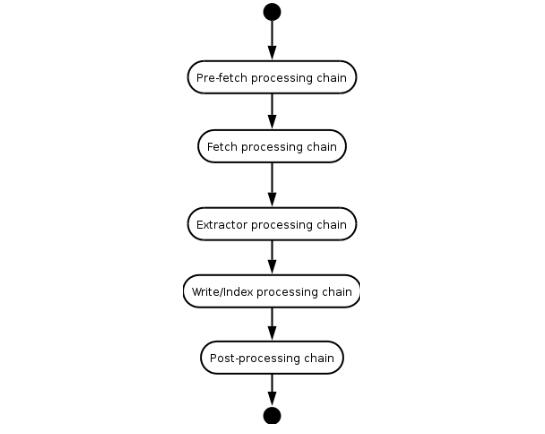
heritrix處理一個url的流程
二、WebSPHINX
WebSPHINX 是一個 Java 類包和 Web 爬蟲的交互式開發環境。 Web 爬蟲 ( 也叫作機器人或蜘蛛 ) 是可以自動瀏覽與處理 Web 頁面的程序。 WebSPHINX 由兩部分組成:爬蟲工作平臺和 WebSPHINX 類包。
WebSPHINX 是一個 Java 類包和 Web 爬蟲的交互式開發環境。 Web 爬蟲 ( 也叫作機器人或蜘蛛 ) 是可以自動瀏覽與處理 Web 頁面的程序。 WebSPHINX 由兩部分組成:爬蟲工作平臺和 WebSPHINX 類包。
WebSPHINX – 用途
1.可視化顯示頁面的集合
2.下載頁面到本地磁盤用于離線瀏覽
3.將所有頁面拼接成單個頁面用于瀏覽或者打印
4.按照特定的規則從頁面中抽取文本字符串
5.用Java或Javascript開發自定義的爬蟲
三、WebLech
WebLech是一個功能強大的Web站點下載與鏡像工具。它支持按功能需求來下載web站點并能夠盡可能模仿標準Web瀏覽器的行為。WebLech有一個功能控制臺并采用多線程操作。
WebLech是一個功能強大的Web站點下載與鏡像免費開源工具。它支持按功能需求來下載web站點并能夠盡可能模仿標準Web瀏覽器的行為。WebLech有一個功能控制臺并采用多線程操作。
這款爬蟲足夠簡單,如果初學如果編寫爬蟲,可做入門參考。所以我選擇了用這個爬蟲開始我的研究。如果只是做要求不高的應用,也可試試。如果想找一款功能強大,就別在WebLech上浪費時間了。
該項目主頁:http://weblech.sourceforge.net/
特點:
1)開源,免費
2)代碼是用純Java寫的,可以在任何支持Java的平臺上也行
3)支持多線程下載網頁
4)可維持網頁間的鏈接信息
5)可配置性強: 深度優先或寬度優先爬行網頁 可定制URL過濾器,這樣就可以按需要爬行單個web服務器,單個目錄或爬行整 個WWW網絡 可設置URL的優先級,這樣就可以優先爬行我們感興趣或重要的網頁 可記錄斷點時程序的狀態,一邊重新啟動時可接著上次繼續爬行。
四、Arale
Arale主要為個人使用而設計,而沒有像其它爬蟲一樣是關注于頁面索引。Arale能夠下載整個web站點或來自web站點的某些資源。Arale還能夠把動態頁面映射成靜態頁面。
五、JSpider
JSpider:是一個完全可配置和定制的Web Spider引擎.你可以利用它來檢查網站的錯誤(內在的服務器錯誤等),網站內外部鏈接檢查,分析網站的結構(可創建一個網站地圖),下載整個Web站點,你還可以寫一個JSpider插件來擴展你所需要的功能。
Spider是一個用Java實現的WebSpider,JSpider的執行格式如下:
jspider [URL] [ConfigName]
URL一定要加上協議名稱,如:http://,否則會報錯。如果省掉ConfigName,則采用默認配置。
JSpider 的行為是由配置文件具體配置的,比如采用什么插件,結果存儲方式等等都在conf\[ConfigName]\目錄下設置。JSpider默認的配置種類 很少,用途也不大。但是JSpider非常容易擴展,可以利用它開發強大的網頁抓取與數據分析工具。要做到這些,需要對JSpider的原理有深入的了 解,然后根據自己的需求開發插件,撰寫配置文件。
Spider是一個高度可配置和和可定制Web爬蟲
LGPL開源許可下開發
100%純Java實現
您可以使用它來:
檢查您網站的錯誤(內部服務器錯誤, …)
傳出或內部鏈接檢查
分析你網站的結構(創建一個sitemap, …)
下載整修網站
通過編寫JSpider插件實現任何功能.
該項目主頁:http://j-spider.sourceforge.net/
六、spindle
spindle是一個構建在Lucene工具包之上的Web索引/搜索工具.它包括一個用于創建索引的HTTP spider和一個用于搜索這些索引的搜索類。spindle項目提供了一組JSP標簽庫使得那些基于JSP的站點不需要開發任何Java類就能夠增加搜索功能。
七、Arachnid
Arachnid是一個基于Java的web spider框架.它包含一個簡單的HTML剖析器能夠分析包含HTML內容的輸入流.通過實現Arachnid的子類就能夠開發一個簡單的Web spiders并能夠在Web站上的每個頁面被解析之后增加幾行代碼調用。 Arachnid的下載包中包含兩個spider應用程序例子用于演示如何使用該框架。
該項目主頁:http://arachnid.sourceforge.net/
八、LARM
LARM能夠為Jakarta Lucene搜索引擎框架的用戶提供一個純Java的搜索解決方案。它包含能夠為文件,數據庫表格建立索引的方法和為Web站點建索引的爬蟲。
該項目主頁:http://larm.sourceforge.net/
九、JoBo
JoBo是一個用于下載整個Web站點的簡單工具。它本質是一個Web Spider。與其它下載工具相比較它的主要優勢是能夠自動填充form(如:自動登錄)和使用cookies來處理session。JoBo還有靈活的下載規則(如:通過網頁的URL,大小,MIME類型等)來限制下載。
十、snoics-reptile
1、snoics-reptile是什么?
是用純Java開發的,用來進行網站鏡像抓取的工具,可以使用配制文件中提供的URL入口,把這個網站所有的能用瀏覽器通過GET的方式獲取到的資源全部抓取到本地,包括網頁和各種類型的文件,如:圖片、flash、mp3、zip、rar、exe等文件。可以將整個網站完整地下傳至硬盤內,并能保持原有的網站結構精確不變。只需要把抓取下來的網站放到web服務器(如:Apache)中,就可以實現完整的網站鏡像。
2、現在已經有了其他的類似的軟件,為什么還要開發snoics-reptile?
因為有些在抓取的過程中經常會出現錯誤的文件,而且對很多使用javascript控制的URL沒有辦法正確的解析,而snoics-reptile通過對外提供接口和配置文件的形式,對特殊的URL,可以通過自由的擴展對外提供的接口,并通過配置文件注入的方式,基本上能實現對所有的網頁都正確的解析和抓取。
該項目主頁:http://www.blogjava.net/snoics
十一、Web-Harvest
Web-Harvest是一個Java開源Web數據抽取工具。它能夠收集指定的Web頁面并從這些頁面中提取有用的數據。Web-Harvest主要是運用了像XSLT,XQuery,正則表達式等這些技術來實現對text/xml的操作。
Web-Harvest 是一個用Java 寫的開源的Web 數據提取工具。它提供了一種從所需的頁面上提取有用數據的方法。為了達到這個目的,你可能需要用到如XSLT,XQuery,和正則表達式等操作text/xml 的相關技術。Web-Harvest 主要著眼于目前仍占大多數的基于HMLT/XML 的頁面內容。另一方面,它也能通過寫自己的Java 方法來輕易擴展其提取能力。
Web-Harvest 的主要目的是加強現有數據提取技術的應用。它的目標不是創造一種新方法,而是提供一種更好地使用和組合現有方法的方式。它提供了一個處理器集用于處理數據和控制流程,每一個處理器被看作是一個函數,它擁有參數和執行后同樣有結果返回。而且處理是被組合成一個管道的形式,這樣使得它們可以以鏈式的形式來執行,此外為了更易于數據操作和重用,Web-Harvest 還提供了變量上下方用于存儲已經聲明的變量。
web-harvest 啟動,可以直接雙擊jar包運行,不過該方法不能指定web-harvest java虛擬機的大小。第二種方法,在cmd下切到web-harvest的目錄下,敲入命令“java -jar -Xms400m webharvest_all_2.jar” 即可啟動并設置起java虛擬機大小為400M。
該項目主頁:http://web-harvest.sourceforge.net
十二、ItSucks
ItSucks是一個Java Web爬蟲開源項目。可靈活定制,支持通過下載模板和正則表達式來定義下載規則。提供一個控制臺和Swing GUI操作界面。
功能特性:
- 多線程
- 正則表達式
- 保存/載入的下載工作
- 在線幫助
- HTTP/HTTPS 支持
- HTTP 代理 支持
- HTTP身份驗證
- Cookie 支持
- 可配置的User Agent
- 連接限制
- 配置HTTP響應代碼的行為
- 帶寬限制
- Gzip壓縮
該項目主頁:http://itsucks.sourceforge.net/
十三、Smart and Simple Web Crawler
Smart and Simple Web Crawler是一個Web爬蟲框架。集成Lucene支持。該爬蟲可以從單個鏈接或一個鏈接數組開始,提供兩種遍歷模式:最大迭代和最大深度。可以設置 過濾器限制爬回來的鏈接,默認提供三個過濾器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,這三個過濾器可用AND、OR和NOT聯合。在解析過程或頁面加載前后都可以加監聽器。
十四、Crawler4j
crawler4j是Java實現的開源網絡爬蟲。提供了簡單易用的接口,可以在幾分鐘內創建一個多線程網絡爬蟲。
crawler4j的使用主要分為兩個步驟:
實現一個繼承自WebCrawler的爬蟲類;
通過CrawlController調用實現的爬蟲類。
WebCrawler是一個抽象類,繼承它必須實現兩個方法:shouldVisit和visit。其中:
shouldVisit是判斷當前的URL是否已經應該被爬取(訪問);
visit則是爬取該URL所指向的頁面的數據,其傳入的參數即是對該web頁面全部數據的封裝對象Page。
另外,WebCrawler還有其它一些方法可供覆蓋,其方法的命名規則類似于Android的命名規則。如getMyLocalData方法可以返回WebCrawler中的數據;onBeforeExit方法會在該WebCrawler運行結束前被調用,可以執行一些資源釋放之類的工作。
許可
Copyright (c) 2010-2015 Yasser Ganjisaffar
根據 Apache License 2.0 發布
開源地址: https://github.com/yasserg/crawler4j
十五、Ex-Crawler
Ex-Crawler 是一個網頁爬蟲,采用 Java 開發,該項目分成兩部分,一個是守護進程,另外一個是靈活可配置的 Web 爬蟲。使用數據庫存儲網頁信息。
Ex-Crawler分成三部分(Crawler Daemon,Gui Client和Web搜索引擎),這三部分組合起來將成為一個靈活和強大的爬蟲和搜索引擎。其中Web搜索引擎部分采用PHP開發,并包含一個內容管理系統CMS用于維護搜索引擎。
該項目主頁:http://ex-crawler.sourceforge.net/joomla/
十六、Crawler
Crawler是一個簡單的Web爬蟲。它讓你不用編寫枯燥,容易出錯的代碼,而只專注于所需要抓取網站的結構。此外它還非常易于使用。
該項目主頁:http://projetos.vidageek.net/crawler/crawler/
十七、Encog
Encog是一個高級神經網絡和機器人/爬蟲開發類庫。Encog提供的這兩種功能可以單獨分開使用來創建神經網絡或HTTP機器人程序,同時Encog還支持將這兩種高級功能聯合起來使用。Encog支持創建前饋神經網絡、Hopfield神經網絡、自組織圖。
Encog提供高級HTTP機器人/爬蟲編程功能。支持將多線程爬蟲產生的內容存在內存或數據庫中。支持HTM解析和高級表單與Cookie處理。
Encog是一種先進的機器學習框架,它支持多種先進的算法,以及支持類正常化和處理數據。機器學習算法,如支持向量機,人工神經網絡,遺傳編程,貝葉斯網絡,隱馬爾可夫模型,遺傳編程和遺傳算法的支持。大多數Encog培訓algoritms是多線程的,很好地擴展到多核硬件。Encog還可以使用一個GPU,以進一步加快處理時間。一個基于GUI的工作臺也提供幫助模型和火車機器學習算法。自2008年以來Encog一直在積極發展.
Encog 支持多種語言,包括C# Java 和C
在GitHub上有各種語言版本的源代碼。
http://www.heatonresearch.com/encog
十八、Crawljax
Crawljax是一個開源Java工具用于Ajax Web應用程序的自動化抓取和測試。Crawljax能夠抓取/爬行任何基于Ajax的Web應用程序通過觸發事件和在表單中填充數據。
收錄時間:2011-05-18 09:50:32
該項目主頁:http://crawljax.com/



















