Hadoop+Spark 大數據開發項目最佳實踐
一、前言
隨著IT技術的飛速發展,各行各業都已在廣泛嘗試使用大數據技術提供更穩健和優質的服務。目前,醫療IT系統收集了大量***價值的數據,但這些歷史醫療數據并沒有發揮出其應有的價值。為此 ,本文擬利用醫院現有的歷史數據,挖掘出有價值的基于統計學的醫學規則、知識,并 基于這些信息構建專業的臨床知識庫,提供診斷、處方、用藥推薦功能,基于強大的關聯推薦能力,極大地提高醫療服務質量,減輕醫療人員的工作強度。
二、Hadoop&Spark
目前大數據處理領域的框架有很多。
從計算的角度上看,主要有MapReduce框架(屬于Hadoop生態系統)和Spark框架。 其中Spark是近兩年出現的新一代計算框架,基于內存的特性使它在計算效率上大大優于MapReduce框架; 從存儲角度來看,當前主要還是在用Hadoop生態環境中的HDFS框架。 HDFS的一系列特性使得它非常適合大數據環境下的存儲。
1、Hadoop
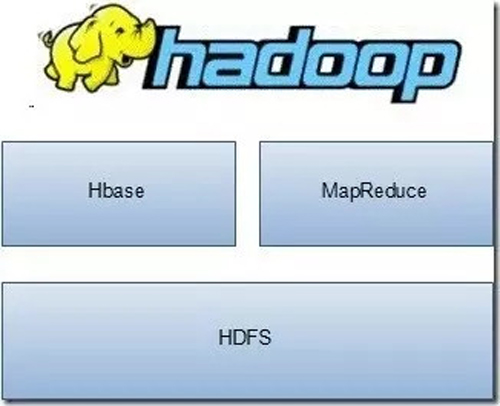
Hadoop不是一個軟件,而是一個分布式系統基礎架構,是由Apache基金會主持開發的一個開源項目。Hadoop可以使用戶在不了解分布式底層實現的情況下,開發分布式程序,從而充分利用電腦集群的威力,實現高速運算和大規模數據存儲。Hadoop主要有HDFS、MapReduce、Hbase等子項目組成。
Hadoop是一個能夠對大量數據進行分布式處理的軟件框架,并且使用可靠、高效、可伸縮的方式進行數據處理。Hadoop假設數據處理和存儲會失敗,因此系統維護多個工作數據副本,確保能夠針對失敗的節點重新分布處理。Hadoop通過并行工作,提高數據處理速度。Hadoop能夠處理PB級數據,這是常規數據服務器所不能實現的。此外,Hadoop依賴于開源社區,任何問題都可以及時得到解決,這也是Hadoop的一大優勢。Hadoop建立在Linux 集群上,因此成本低,并且任何人都可以使用。它主要具有以下優點:
高可靠性。Hadoop系統中數據默認有三個備份,并且Hadoop有系統的數據檢查維護機制,因而提供了高可靠性的數據存儲。
擴展性強。Hadoop在普通PC服務器集群上分配數據,通過并行運算完成計算任務,可以很方便的為集群擴展更多的節點。
高效性。Hadoop能夠在集群的不同節點之間動態的轉移數據。并且保證各個節點的動態平衡,因此處理速度非常快。
高容錯性。Hadoop能夠保存數據的多個副本,這樣就能夠保證失敗時,數據能夠重新分配。
Hadoop總體架構如下圖所示, Hadoop架構中核心的是MapReduce和HDFS兩大組件。
Google曾發表論文《Google File System》,系統闡述了Google的分布式文件系統的設計實現,Apache針對GFS,進行開源開發,發布了Hadoop的分布式文件系統:Hadoop Distributed File System,縮寫為HDFS。MapReduce的核心思想也由Google的一篇論文《MapReduce:Simplified Data Processing on Large Clusters》 提出,簡單解釋MapReduce的核心思想就是:任務分解執行,執行結果匯總。
2、Spark
Spark是UC Berkeley大學AMP實驗室開源的類似MapReduce的計算框架,它是一個基于內存的集群計算系統,最初的目標是解決MapReduce磁盤讀寫的開銷問題,當前***的版本是1.5.0。Spark—經推出,就以它的高性能和易用性吸引著很多大數據研究人員,在眾多愛好者的努力下,Spark逐漸形成了自己的生態系統( Spark為基礎,上層包括Spark SQL,MLib,Spark Streaming和GraphX),并成為Apache的***項目。
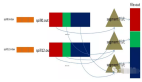
Spark的核心概念是彈性分布式存儲 (Resilient Distributed Datasets, RDD)間,它是Spark對分布式內存進行的抽象,使用者可以像操作本地數據集一樣操作RDD,從而可以將精力集中于業務處理。在Spark程序中,數據的操作都是基于RDD的,例如經典的WordCount程序,其在Spark編程模型下的操作方式如下圖所示:
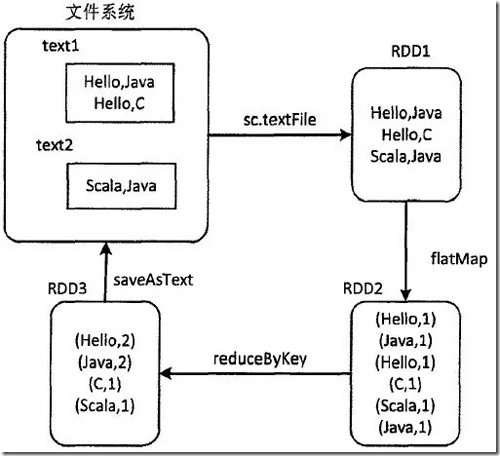
可以看到Spark先從文件系統抽象出RDD1,然后由RDD1經過flatMap算子轉換得到RDD2,RDD2再經過reduceByKey算子得到RDD3,***RDD3中的數據重新寫回文件系統,一切操作都是基于RDD的。
三、思路和架構
經過多方面的思考,最終決定基于Spark技術進行構建和實現醫院臨床知識庫系統,采用MongoDB/Sequoiadb構建大數據倉庫,做為大數據的存儲中心,采用Hadoop+Spark1構建大數據分析平臺,基于AgileEAS.NET SOA中間件構建ETL數據抽取轉換工具(后期部分換用了Pentaho Kettle),基于AgileEAS.NET SOA中間件構建知識庫的服務門戶,通過WCF/WebService與HIS系統進行業務整合集成,使用AgileEAS.NET SOA+FineUI構建基礎字典管理以后分析結構的圖像化展示功能。
最初我們選擇了SequoiaDB做為大數據存儲中心,為此我還特意的為SequoiaDB完成了C#驅動,參考本人為巨杉數據庫(開源NoSQL)寫的C#驅動,支持Linq,全部開源,已提交Github一文,但是一方面熟悉SequoiaDB的技術人員太少了,維護是個問題,***,在差不多8多個月這后我們換用了MongoDB 3.0做為大數據存儲中心。
最初我們選擇了Hadoop2.0+Spark1.3.1版本之上使用scala2.10開發完成了醫院臨床知識庫系統,請參考centos+scala2.11.4+Hadoop2.3+Spark1.3.1環境搭建,但是在后期替換Sequoiadb為MongoDB的同時,我們把計算框架也由Hadoop2.0+Spark1.3.1升級到了Hadoop2.6+Spark1.6.2。
考慮到Spark都部署在Linux的情況,對于Spark分析的結果輸出存儲在MySQL5.6數據庫之中,系統所使用的各種字典信息也存儲在MySQL之中。
Spark數據分析部分的代碼使用IntelliJ IDEA 14.1.4工具進行編寫,其他部分的代碼使用VS2010進行編寫。
1、總體架構
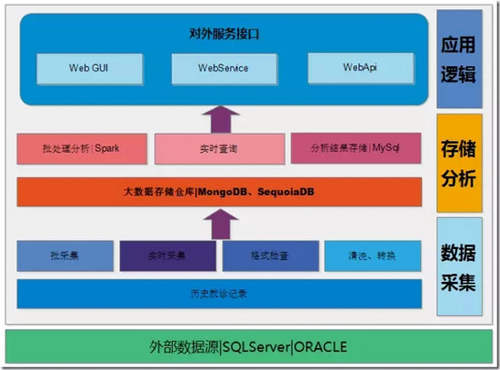
整個系統由數據采集層、存儲分析層和應用邏輯層三大部分以及本系統所選所以來的外部數據源。
本系統的外部數據源目前主要是醫院信息系統所產生的臨床數據,目前主要集中在HIS系統之中,后期將采依賴于EMR、LIS、PACS系統。
數據采集層 主要負責從臨床業務系統采集海量歷史臨床數據同,歷史記錄采集方式分為批采集和實時采集,在數據采集過程之中對原始數據進行格工檢查,并對原始數據進行清洗和轉換,并將處理后的數據存儲在大數據倉庫之中。
存儲分析層 主要負責數據存儲以及數據分析兩大部分業務,經過清洗轉換的合理有效數據被存儲在大數據集群之中,使用JSON格式,大數據存儲引用使用SequoiaDB數據庫,數據分析部分由Hadoop/Spark集群來完成,大數據存儲經由Spark導入并進行分析,分析結果寫入臨床知識數據庫,臨床知識數據庫使用MySQL數據庫進行存儲。
應用邏輯層 主要負責人機交互以及分析結構回饋臨床系統的渠道,通過WebUI的方式向臨床醫生、業務管理人員提供列表式、圖像化的知識展示,也為臨床系統的業務輔助、推薦功能提供調用的集成API,目前API主要通過WebService、WebAPI兩種方式提供。
2、總體流程
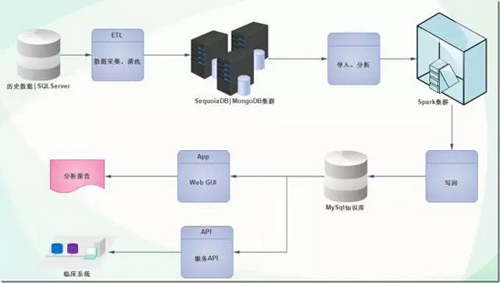
整個系統經由數據源數據采集,寫入大數據存儲SequoiaDB集群,然后由Spark進行分析計算,分析生成的臨床知識寫入MySQL知識庫,經由WebUI以及標準的API交由臨床使用。
3、數據導入流程
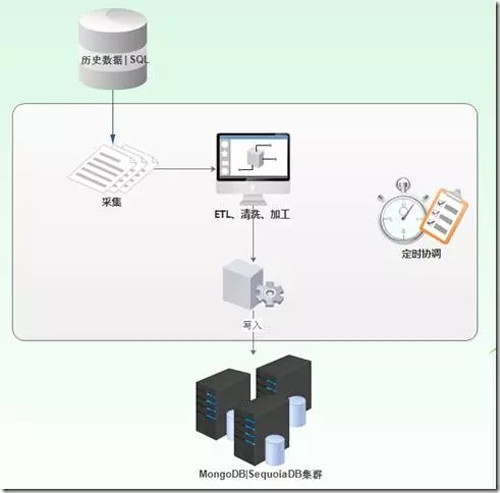
歷史數據的采集導入使用初期使用AgileEAS.NET SOA 的計劃任務配何C#腳本進行實現,由計劃任務進行協調定時執行,具體的數據導入代碼根據不同的臨床業務系統不同進行腳本代碼的調整,也可以使用Pentaho Kettle進行實現,通過Pentaho Kettle可配置的實現數據的導入。
4、物理結構設計
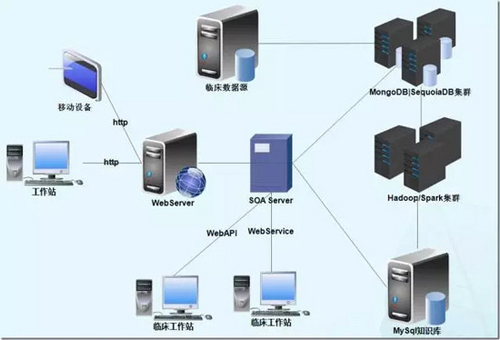
臨床數據源為本系統進行分析的數據來源,源自于臨床HIS、EMR,目前醫院的HIS使用SQL Server 2008 R2數據庫,EMR使用ORACLE 11G數據庫,運行于Windows2008操作系統之上。
SequoiaDB集群為大數據存儲數制庫集群,目前使用SequoiaDB v2.0,運行于Centos6.5操作系統之上,根據業務來規模使用2-16節點集群,其用于存儲經過清洗轉換處理的海量歷史臨床數據,供Spark集群進行分析,以及供應SOA服務器進行歷史數據查詢和歷史相關推薦使用。
Hadoop/Spark集群為本系統的分析計算核心節點,用于對SequoiaDB集群之中的歷史數據進行分析,生成輔助臨床醫生使用的醫學知識,本集群根據業務來規模使用2-16節點集群,使用Centos6.5操作系統,安裝JAVA1.7.79運行環境、scala2.11.4語言,使用Hadoop2.3,Spark1.3.1分析框架。
MySQL知識庫為本系統的知識庫存儲數據庫,Hadoop/Spark集群所生產的分析結構寫入本數據庫,經由SOA服務器和Web服務處理供臨床系統集成使用和WebGUI展現,目前使用MySQL5.6版本,安裝于Windows2008/Centos6操作系統之上。
SOA Server為本系統的對外接口應用服務器,向臨床業務系統和Web Server提供業務運算邏輯,以及向臨床業務系統提供服務API,目前運行于Windows2008操作系統,部署有.NET Framework 4.0環境,運行AgileEAS.NET SOA 中間件的SOA服務,由AgileEAS.NET SOA 中間件SOA服務向外部系統提供標準的WebService以及WebAPI。
Web Server為系統提供基于標準的B/S瀏覽器用戶接口,供業務人員通過B/S網頁對系統進行管理,查詢使用知識庫之中的醫學知識,目前運行于Windows2008操作系統,部署有.NET Framework 4.0環境,運行于IIS7.0之中。
臨床工作站系統運行HIS、EMR系統,兩系統均使用C#語言SOA架構思路進行開發,與本系統集成改造后,使用標準WebService接口本系統,使用本系統所提供的API為臨床提供診療輔助。
四、環境、安裝、坑
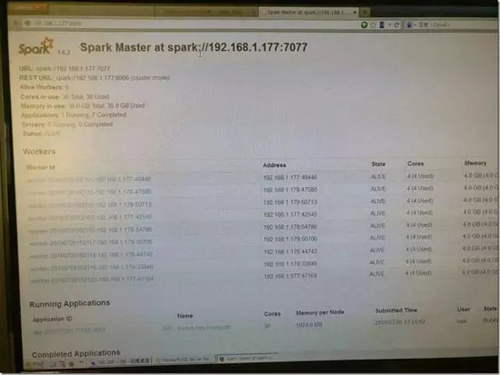
目前系統跑在虛擬化環境之中,其中三臺Centos6組成大數據存儲、計算集群,每臺分配16CPU(核)16G內存2T硬盤,3臺共48核48G,這三臺機器每臺都安裝了Java1.8.25+scala2.10+Hadoop2.6,Spark1.62,MongoDB3.0組合3節點的集群,Spark采用Standalone Cluster模式,單一master節點,為每臺機器分配其中12核12G用于Worker,其余CPU內存留給MongoDB集群使用,運行截圖如下:
一臺Win2008做為SOA|應用服務器,分配32核64G內存,部署了MySQL5.6,IIS,AgileEAS.NET SOA 服務,整個系統的SOA服務和Web管理界面由本服務器進行承載,一方面提供Web方式的管理和查詢,另一方面以webservice、webAPI為臨床系統提供服務。
具體環境的安裝過程由于篇幅的原因在此就不在一一細說,我將會單獨寫一篇文章為大家進行詳細的介紹。
***次使用Spark,又沒有多少資料可參考,所以在開發過程之中遇到不少的坑,特別是初期的時間,搭建環境就費了一周,寫代碼過程之中坑也是一直發現一直填坑,有點坑也填不了,直好換思路繞了,記得在Spark sql的udf自定義函數上,并不是所有函數都有坑,偶爾自己寫的udf函數怎么都是過不去,找不到原因,看Spark的源代碼也沒看出個所以然,***不得改寫代碼,換思路搞。
感覺特別有愛的就是scala語言了, 我覺得使用.net 4.0(C#)的朋友們,特別是用熟Linq的兄弟們,scala語言太方便了,我感覺他基本上就是和linq一樣方便,更沒有節操的是,在函數之中可以定義類,不過,真的是很方便,我不是很喜歡Java,但是我喜歡scala。
五、效果展示
1、門診診斷排名
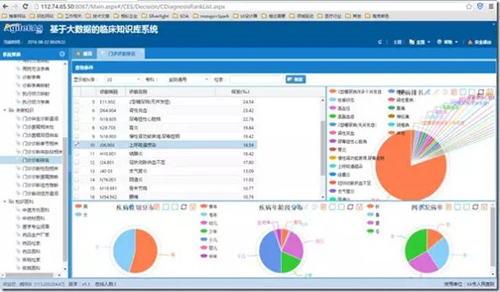
門診診斷排名是門診診斷知識的圖形化界面展示顯示,用于展示全院或者指定專科的TopN位常用診斷,也為每一個診斷與性別、年齡等人群相關性以及與節氣相關性圖表展示。
2、門診伴生診斷查詢
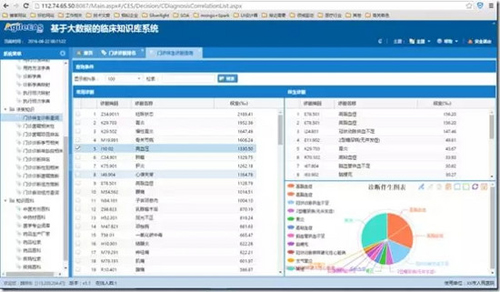
門診伴生診斷排名是門診診斷并發癥的知識展示界面,用于展示得某一種疾病另其他疾病的可能性。
3、門診自動組方查詢

門診自動組方查詢,用于展示臨床最常用的用藥、治療自動組方知識,即比如最常用的0.9%氯化鈉注射液100ml配注射用頭孢硫咪1g,常適用于扁桃體發炎、喘息性之氣管炎、上呼吸道感染等疾病,給以靜脈點滴方式每日一次使用。
4、門診診斷組方推斷
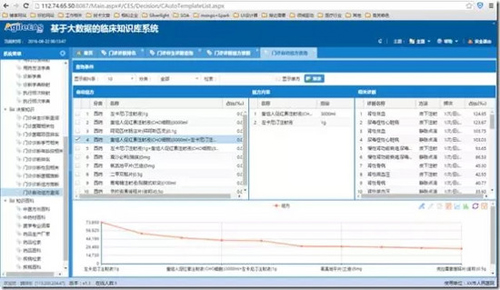
門診診斷組方推斷,用于展示臨床疾病診斷與常用藥品、治療給合方案的相關性關聯,即如上圖展示上呼吸道感染常使用氨酚麻美干混懸劑1包、四季抗病毒合劑、0.9%氯化鈉注射液100ml+注射用頭孢硫咪1g、滅菌注射用水2ml+注射用重組人干擾素a1b 10ug等這樣的組合治療方案。
5、醫療臨床系統整合
為了實現來源于臨床系統,并且服務于臨床系統的總體系統,我們聯動了本院的HIS系統之中的門診醫生站,與本系統進行基于WebService的整合,如下圖所示的整合界面:
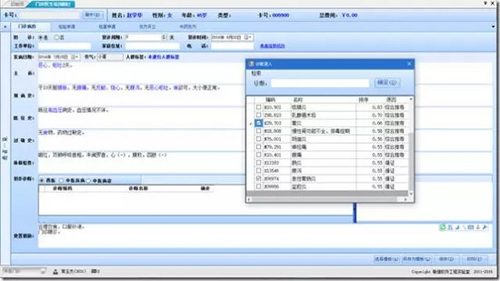
臨床醫生在完成基本的門診病歷之后,系統會自動為其體檢待選的門診疾病診斷,80%-90%的情況可以直接選擇,在少數情況下沒有推薦合適的時候大夫才會錄入,省去大夫錄入診斷的麻煩,也減少因大夫錄入的不規范而導致的數據的混亂。

在臨床醫生寫完門診病歷,進行開立檢驗、檢查、用藥、治療的時間,系統會根據當有的診斷信息推薦合適的治療方案選擇,臨床醫生只需求在右邊的推薦組方上雙擊即可實現快速的處方開方,大大的方便的臨床醫生的工作。
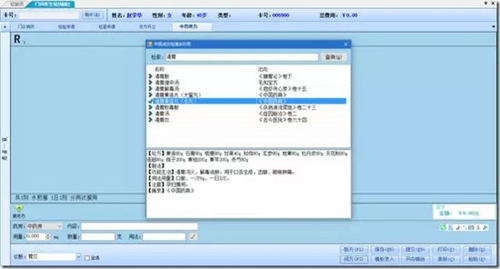
針對中醫院,系統集成了3W多個經典成方,根據歷史數據與成方字典的組合分析對比,極大的方便中醫大夫日常工作:

六、實現細節、后續文章
對于大數據技術,以及大數據技術在醫療化信息行業的實踐,以及實現之中的思路和細節,不是短短這么一點篇幅就能介紹完成的,此文也是在我實現需求,實踐之后所寫,所以總覺得東西都比較簡單,我只期望本文能達到拋轉引用的作用,能對同行做相關工作的朋友們有所參考,思路可以得到借鑒,然本文也實在沒有講清楚所有的細節。