大數據開發:Spark入門詳解
眾所周知,Spark 它是專門為大規模數據處理而設計的快速通用計算引擎,因此Spark它在數據的挖掘等領域便有著非常廣泛的應用,而從現階段來講的話它也已經形成了一個高速發展并且應用相當廣泛的生態系統了。所以,今天這篇文章便要為大家做一個Spark入門基礎的簡單介紹,滿滿干貨,請不要錯過。
一.關于Spark的概述
我們可以了解到,當前,MapReduce編程模型成為了一種比較主流的分布式編程模型,并且它也極大地方便了編程人員在不會分布式并行編程的情況下,能夠將自己的程序運行在分布式系統上。
但其實從MapReduce來看它也存在了一些缺陷的,比如說它的高延遲以及不支持DAG模型,Reduce的中間數據落地等。因此為了優化改進MapReduce的項目,比如交互查詢引擎Impala、支持內存計算Spark等這些方面。Spark憑借自身先進的設計理念,一躍成為了社區里面的熱門項目。而目前來看Spark相對于MapReduce的一些優勢有:低延遲、支持DAG和分布式內存計算。
二.Spark應用框架
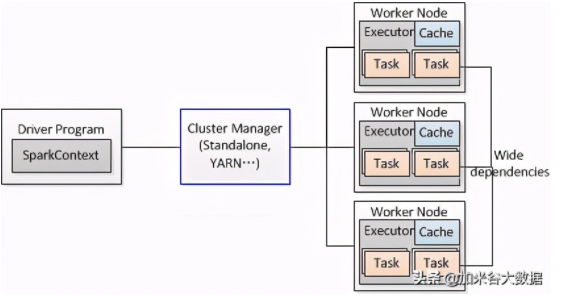
客戶Spark程序(Driver Program)操作Spark集群其實它是通過SparkContext這個對象來進行的,而SparkContext自身作為一個操作和調度的總入口,它在初始化的過程中集群管理器則會進行DAGScheduler作業調度和TaskScheduler任務調度的創建。
而DAGScheduler作業調度模塊則又是依靠于Stage的這個調度模塊來進行的,DAG全稱 Directed Acyclic Graph。簡單的來講的話,它其實就是一個由頂點和有方向性的邊構成的圖,然后他可以其中從任意的一個頂點去出發,但是呢又沒有路徑可以將其帶回到出發的頂點。并且它為每個Spark Job計算具有依賴關系的多個Stage任務階段(通常根據Shuffle來劃分Stage,比如說groupByKey, reduceByKey等涉及到shuffle的transformation就會產生新的stage),然后到后面的時候它又會將每個Stage劃分為具體的一組任務,最后就以TaskSets的形式提交給底層的任務調度模塊來進行一個具體執行。
三.Spark的內置項目
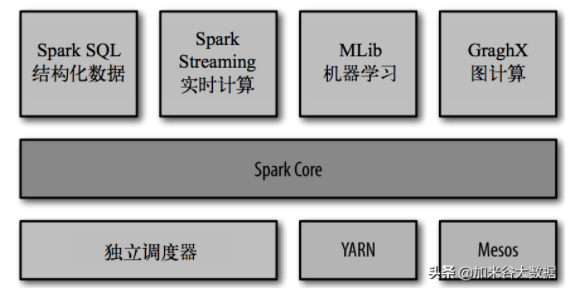
Spark Core: 它實現了的是Spark 中的一個基本功能,其中它是包含了任務的調度、內存的管理、錯誤的恢復、以及與存儲系統 交互等模塊。其中Spark Core 中它還包含了對彈性分布式數據集(resilient distributed dataset,簡稱RDD)的 API 定義。
Spark SQL: 這個是 Spark 所用來進行操作結構化數據的一個程序包。并且它通過了 Spark SQL,我們可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)來查詢數據。而我們可以知道Spark SQL 支持多種數據源,比 如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming: 這個是 Spark 提供的對實時數據進行流式計算的組件。提供了用來操作數據流的 API,并且與 Spark Core 中的 RDD API 高度對應。
Spark MLlib: 提供常見的機器學習(ML)功能的程序庫。包括分類、回歸、聚類、協同過濾等,還提供了模型評估、數據 導入等額外的支持功能。
集群管理器: Spark 設計不僅可以高效地在一個計算節點到數千個計算節點之間伸縮計 算。為了實現這樣的要求,并且同時能夠獲得一個最大的靈活性,Spark 支持便會在各種集群管理器(cluster manager)上運行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自帶的一個簡易調度器,它也叫作獨立調度器。
三.Spark生態圈介紹
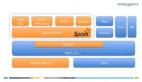
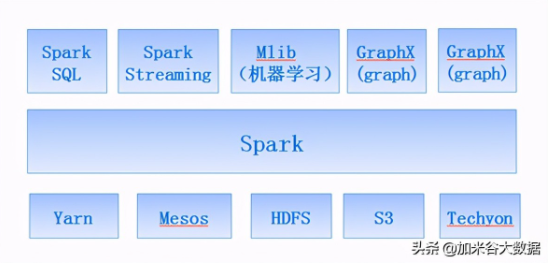
Spark力圖整合機器學習(MLib)、圖算法(GraphX)、流式計算(Spark Streaming)和數據倉庫(Spark SQL)等領域,通過計算引擎Spark,彈性分布式數據集(RDD),架構出一個新的大數據應用平臺。
Spark生態圈以HDFS、S3、Techyon為底層存儲引擎,以Yarn、Mesos和Standlone作為資源調度引擎;使用Spark,可以實現MapReduce應用;基于Spark,Spark SQL可以實現即席查詢,Spark Streaming可以處理實時應用,MLib可以實現機器學習算法,GraphX可以實現圖計算,SparkR可以實現復雜數學計算。
四.Spark的優點
①減少磁盤I/O:隨著實時大數據應用越來越多,Hadoop作為離線的高吞吐、低響應框架已不能滿足這類需求。HadoopMapReduce的map端將中間輸出和結果存儲在磁盤中,reduce端又需要從磁盤讀寫中間結果,勢必造成磁盤IO成為瓶頸。Spark允許將map端的中間輸出和結果存儲在內存中,reduce端在拉取中間結果時避免了大量的磁盤I/O。Hadoop Yarn中的ApplicationMaster申請到Container后,具體的任務需要利用NodeManager從HDFS的不同節點下載任務所需的資源(如Jar包),這也增加了磁盤I/O。Spark將應用程序上傳的資源文件緩沖到Driver本地文件服務的內存中,當Executor執行任務時直接從Driver的內存中讀取,也節省了大量的磁盤I/O。
②增加并行度:由于將中間結果寫到磁盤與從磁盤讀取中間結果屬于不同的環節,Hadoop將它們簡單的通過串行執行銜接起來。Spark把不同的環節抽象為Stage,允許多個Stage既可以串行執行,又可以并行執行。
③避免重新計算:當Stage中某個分區的Task執行失敗后,會重新對此Stage調度,但在重新調度的時候會過濾已經執行成功的分區任務,所以不會造成重復計算和資源浪費。
④可選的Shuffle排序:HadoopMapReduce在Shuffle之前有著固定的排序操作,而Spark則可以根據不同場景選擇在map端排序或者reduce端排序。
⑤靈活的內存管理策略:Spark將內存分為堆上的存儲內存、堆外的存儲內存、堆上的執行內存、堆外的執行內存4個部分。Spark既提供了執行內存和存儲內存之間是固定邊界的實現,又提供了執行內存和存儲內存之間是“軟”邊界的實現。Spark默認使用“軟”邊界的實現,執行內存或存儲內存中的任意一方在資源不足時都可以借用另一方的內存,最大限度的提高資源的利用率,減少對資源的浪費。Spark由于對內存使用的偏好,內存資源的多寡和使用率就顯得尤為重要,為此Spark的內存管理器提供的Tungsten實現了一種與操作系統的內存Page非常相似的數據結構,用于直接操作操作系統內存,節省了創建的Java對象在堆中占用的內存,使得Spark對內存的使用效率更加接近硬件。Spark會給每個Task分配一個配套的任務內存管理器,對Task粒度的內存進行管理。Task的內存可以被多個內部的消費者消費,任務內存管理器對每個消費者進行Task內存的分配與管理,因此Spark對內存有著更細粒度的管理。
以上本篇內容便是對Spark的一些基礎入門的介紹,后續還將對Spark做一些后續的介紹,以便能更加深入的對Spark做一個了解。