Hadoop與 Spark - 選擇正確的大數據框架
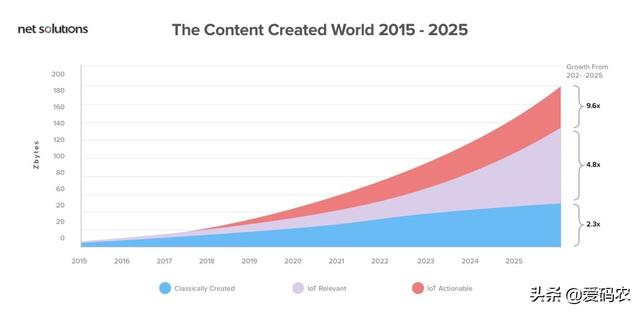
我們被各方的數據所包圍。隨著數據每兩年增加一倍,數字世界正在快速追逐物理世界。據估計,到2020年,數字宇宙將達到44個zettabytes - 與宇宙中的恒星一樣多的數字位。
數據正在增加,我們不會很快擺脫它。為了消化所有這些數據,市場上有越來越多的分布式系統。在這些系統中,Hadoop和Spark經常作為直接競爭對手相互競爭。
在決定這兩個框架中哪一個適合您時,根據幾個基本參數對它們進行比較非常重要。
性能
Spark非常閃電,并且發現它的性能優于Hadoop框架。它在內存中的運行速度提高了100倍,在磁盤上運行速度提高了 10倍。此外,我們發現,它使用10倍的機器,比使用Hadoop快3倍的數據排序100 TB。
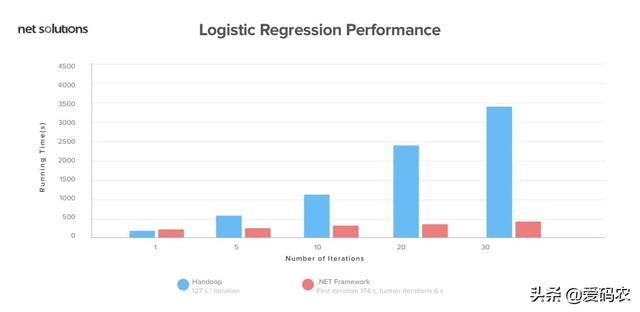
Spark是如此之快,因為它處理內存中的所有內容。得益于Spark的內存處理,它可以為來自營銷活動,物聯網傳感器,機器學習和社交媒體網站的數據提供實時分析。
但是,如果Spark和其他共享服務在YARN上運行,則其性能可能會降低。這可能導致RAM開銷內存泄漏。另一方面,Hadoop輕松處理這個問題。如果用戶傾向于批量處理,Hadoop比Spark更有效。
Hadoop和Spark都有不同的處理方式。因此,它完全取決于項目的需求,是否在Hadoop和Spark性能戰中繼續使用Hadoop或Spark。
Facebook及其與Spark框架的過渡之旅
Facebook上的數據每過一秒就會增加。為了處理這些數據并使用它來做出明智的決定,Facebook使用分析。為此,它使用了許多平臺,如下所示:
- Hive平臺執行Facebook的一些批量分析。
- 用于自定義MapReduce實現的Corona平臺。
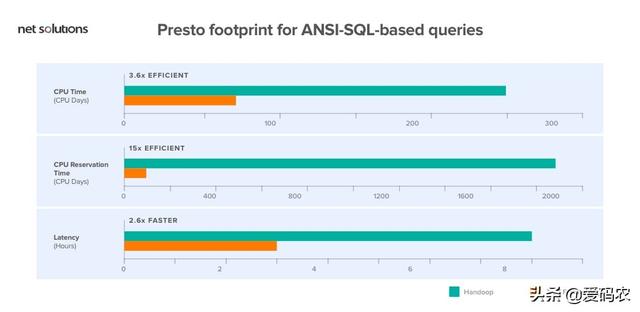
- 基于ANSI-SQL的查詢的Presto足跡。
上面討論的Hive平臺在計算上是“資源密集型的”。所以,維持這是一個巨大的挑戰。因此,Facebook決定切換到Apache Spark框架來管理他們的數據。今天,Facebook已經通過集成Spark為實體排名系統部署了一條更快的可管理管道。
安全
Spark的安全性仍在不斷發展,因為它目前只支持通過共享密鑰進行身份驗證(密碼身份驗證)。甚至Apache Spark的官方網站聲稱,“存在許多不同類型的安全問題。Spark并不一定能防范所有事情。“
另一方面,Hadoop具有以下安全功能:Hadoop身份驗證,Hadoop授權,Hadoop審計和Hadoop加密。所有這些都與Knox Gateway和Sentry等Hadoop安全項目集成在一起。
一句話:在Hadoop vs Spark Security的戰斗中,Spark比Hadoop安全一點。但是,在將Spark與Hadoop集成時,Spark可以使用Hadoop的安全功能。
成本
首先,Hadoop和Spark都是開源框架,因此免費提供。兩者都使用商用服務器,在云上運行,似乎有一些類似的硬件要求:
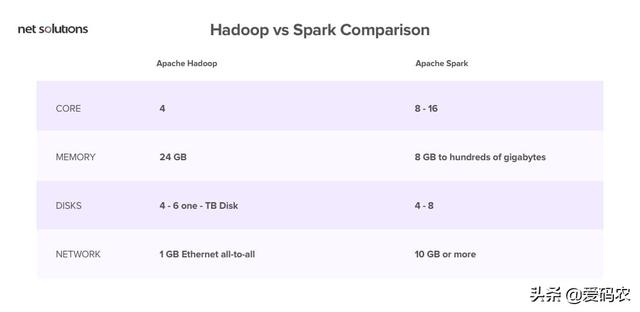
那么,如何根據成本對它們進行評估呢?
請注意,Spark利用大量RAM來運行內存中的所有內容。鑒于RAM的價格高于硬盤,這可能會影響成本。
另一方面,Hadoop受磁盤限制。因此,您購買昂貴RAM的成本得以節省。但是,Hadoop需要更多系統來分發磁盤I / O.
因此,在比較Spark和Hadoop框架的成本參數時,組織將不得不考慮他們的要求。
如果需求傾向于處理大量的大型歷史數據,Hadoop是繼續選擇的選擇,因為硬盤空間的價格遠低于內存空間。
另一方面,當我們處理實時數據選項時,Spark可以具有成本效益,因為它使用較少的硬件以更快的速度執行相同的任務。
結論:在Hadoop與Spark成本之爭中,Hadoop肯定會降低成本,但當組織必須處理較少量的實時數據時,Spark才具有成本效益。
便于使用
Spark框架的最大USP之一是其易用性。Spark為Scala Java,Python和Spark SQL(也稱為Shark)提供了用戶友好且舒適的API。
Spark的簡單構建塊使編寫用戶定義的函數變得容易。此外,由于Spark允許批處理和機器學習,因此簡化數據處理的基礎設施變得容易。它甚至包括一個交互模式,用于運行具有即時反饋的命令。
Hadoop是用Java編寫的,并且在為沒有交互模式編寫程序的困難鋪平道路方面聲名狼借。雖然Pig(附加工具)使編程更容易,但是需要一些時間來學習語法。
結論:在'易用性'Hadoop vs Spark之戰中,他們都有自己的方式讓自己對用戶友好。但是,如果我們必須選擇一個,Spark更容易編程并包含交互模式。
Apache Hadoop和Spark有可能建立協同關系嗎?
是的,這是非常可能的,我們推薦它。讓我們深入了解它們如何協同工作。
Apache Hadoop生態系統包括HDFS,Apache Query和HIVE。讓我們看看Apache Spark如何利用它們。
Apache Spark和HDFS的融合
Apache Spark的目的是處理數據。但是,為了處理數據,引擎需要從存儲器輸入數據。為此,Spark使用HDFS。(這不是唯一的選擇,但是最受歡迎的選擇,因為Apache是兩者背后的大腦)。
Apache Hive和Apache Spark的混合體
Apache Spark和Apache Hive高度兼容,它們可以解決許多業務問題。
例如,假設企業正在分析消費者行為。現在,為此,該公司將需要從各種來源收集數據,如社交媒體,評論,點擊流數據,客戶移動應用程序等等。
組織可以利用HDFS存儲數據,Apache hive作為HDFS和Spark之間的橋梁。
優步及其合并方法
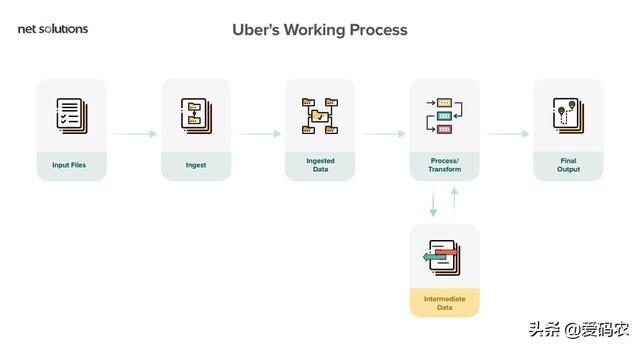
優步使用Spark和Hadoop
為了處理消費者數據,優步使用了Spark和Hadoop的組合。它使用實時交通情況在特定時間和地點提供駕駛員。為了實現這一目標,優步使用HDFS將原始數據上傳到Hive和Spark,以處理數十億個事件。
雖然Spark快速且易于使用,但Hadoop具有強大的安全性,龐大的存儲容量和低成本的批處理功能。選擇一個中的一個完全取決于您的項目的要求。兩者的結合將產生一種無敵的組合。
混合Spark的一些屬性和一些Hadoop來提出一個全新的框架:Spoop。