多維分析中的 UV 與 PV
1. 概念
1.1 UV 與 PV
對于互聯網產品來說,UV 與 PV 是兩個非常常見的指標,并且通常都是分析的最基礎指標。UV 一般來講,是指使用產品(或產品某個功能)的獨立用戶數。PV 則來源于網站時代,一般指網站(或網站某個頁面)的頁面瀏覽量,在移動互聯網時代,則一般會引申表示使用產品(或產品某個功能)的用戶行為或者用戶操作數量。
PV 和 UV 一般而言是互相影響,一起變化的,對于 PV 和 UV 的變化與數字的解讀,也是一門很深的學問。由于本文主要是介紹在多維分析中 UV 和 PV 的計算規則,所以,對于 PV 和 UV 的具體解讀與分析,不做展開論述。
1.2 多維分析
多維分析是在 BI(Business Intelligence)領域廣泛使用的一種分析技術和分析方法,能夠從不同的角度,靈活動態地進行分析。
多維分析中有“指標”和“維度”兩個基本概念,在這里,我們用一個實際的例子來進行描述。
一個典型的網站,它可能需要從地域、終端、App 版本這三個角度,來考察自己的 PV 和 UV 的情況。那么,在這個場景下,維度有三個,分別是地域、終端和 App 版本;指標則是兩個,分別是 PV 和 UV。所謂的多維分析,就是可以在維度的任意組合情況下,來看對應的指標的數值:可以看北京的,iOS端的,7.1 版 App 的 PV 和 UV;也可以看湖北的安卓端的 PV 和 UV;也可以看 7.2 版 App 的 PV 和 UV。具體設置查詢條件的時候,維度可以是三個,可以是兩個,也可以是一個。從這個例子可以看出,多維分析是非常靈活的,具有很強的分析能力,可以充分滿足分析人員對于產品的各種細粒度的分析需求。
而為了能夠讓多維分析發揮出更大的價值,一般情況下,都是希望多維分析的查詢結果能夠在一分鐘能就得到,從而可以讓使用者不停地調整查詢條件,快速地驗證自己的猜想。
2. “可加”與“不可加”
正如上面提到的,多維分析對于查詢速度非常敏感,業內也有很多專門的存儲和查詢方案。
而在具體的實現中,有一種最為常見的實現手段,就是把各個維度的所有取值組合下的指標全部預先計算并且存儲好,這種一般可以稱作事實表。然后在具體進行多維查詢的時候,再根據維度的選擇,掃描相對應的數據,并聚合得到最終的查詢條件。
此時,會發現一個比較有意思的問題,就是 PV 這類指標,是“可加”的,而 UV 這類指標,則是“不可加”的。例如,我們把昨天三個維度的可能組合下的所有的 PV 和 UV 都計算并且存儲好,如下表所示:
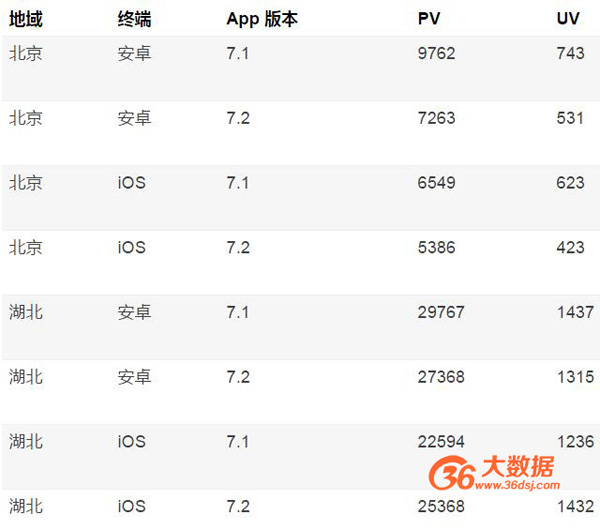
那么,對于 PV 這種指標,是可以通過掃描對應的記錄,然后累加得到最終的結果。例如,我們想分析整個湖北的 PV,則可以把湖北相關的四條記錄中的 PV,累加起來就是整個湖北的 PV 值。
但是,對于 UV 這類指標,卻不能簡單的累加,因為,這個指標并不是在每一個維度上都是正交的。例如,同一個用戶可能先后使用了不同的 App 版本,甚至于有一定幾率使用了不同的終端,所以,UV 并不能簡單地累加,通常情況下,真實的 UV 是比加起來的值更小的。
因而,對于 UV 這類不可累加的指標,需要使用其它的計算方案。
3. UV 計算的常見方案
UV 類型的指標,有三種常見的計算方案,我們在這里分別進行介紹。
3.1 估算方案
所謂的估算方案,就是在上面的表格的基礎上,不再額外記錄更多細節,而是通過估算的方式來給出一個接近真實值的 UV 結果,常見的算法有很多,例如 HyperLogLog 等。
由于畢竟是估算,最終估算的結果有可能與真實值有較大差異,因此只有一些統計平臺可能會采用,而如我們 Sensors Analytics 之類的以精細化分析為核心的分析系統并不會采用,因此在這里不做更多描述。
3.2 擴充事實表,以存代算
所謂以存代算,就是在預先計算事實表的時候,將所有需要聚合的結果,都算好。
依然以上面的例子來說明,如果我們想以存代算,預先做完聚合,類似于 Hive 所提供的group by with cube操作。在擴充完畢后,之前那個表的結果就應該是:
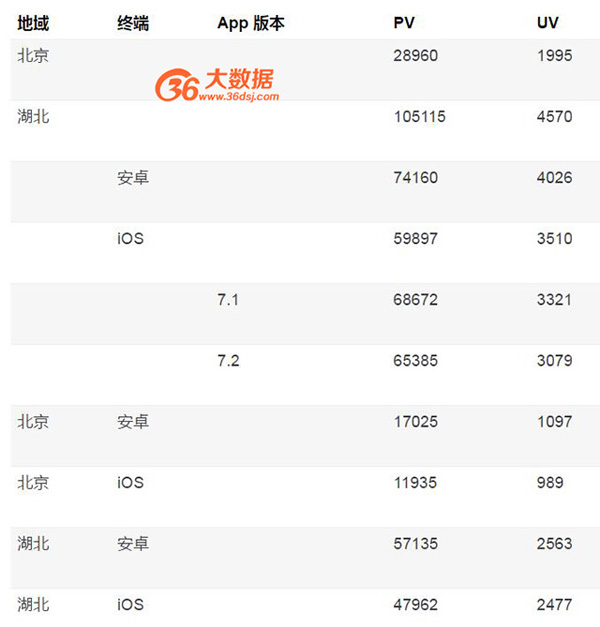
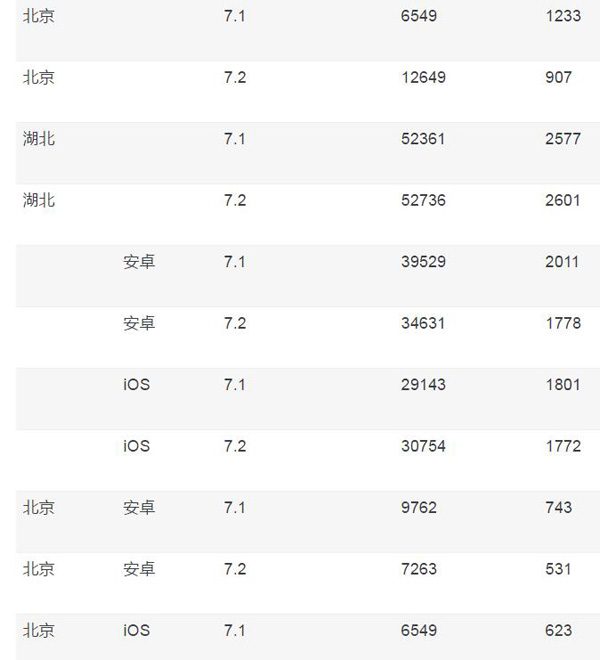
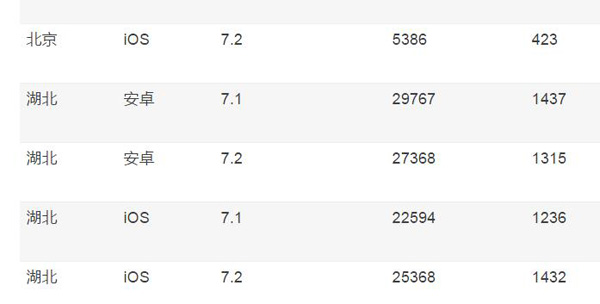
從這個表我們可以看出,假設一共三個維度,每個維度有兩個取值,則之前的事實表一共是 2*2*2=8 條記錄,而現在,則擴充到了 3*3*3-1=26 條記錄,整個規模擴充了很多,會帶來更多的存儲和預計算的代價。
3.3 從最細粒度數據上掃描
之前提出的擴充事實表的方式,的確可以解決多維分析中指標聚合的問題,除此之外,還有一種方案,則是在事實表上,將用戶ID也做為一個維度,來進行保存,此時就不需要保存 UV 了,如下表所示:
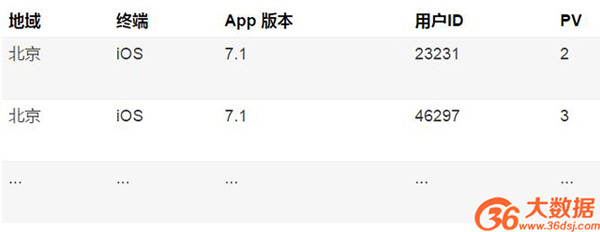
甚至更進一步,我們將 PV 數值也進一步展開,對于用戶的每一個行為,都保留一條數據,如下表:
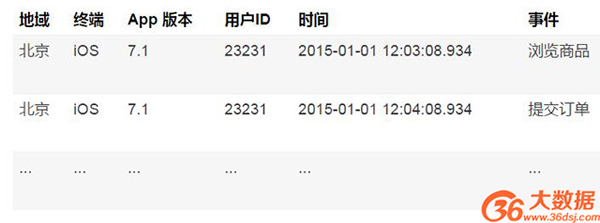
雖然這樣一來,需要保存的數據規模有了數量級上的擴充,并且所有的聚合計算都需要在多維分析查詢的時候再掃描數據并進行聚合,存儲和計算代價都提高了很多,看似是一種很無所謂的舉措。
但是,相比較之前的方案,它卻有一個***的好處,也即是因為有了最細粒度的用戶行為數據,才有可能計算事件級別的漏斗、留存、回訪等,才有可能在這些數據的基礎之上,進一步做用戶畫像、個性化推薦等等。而這也正是目前 Sensors Analytics 所采用的數據存儲方案,也正因為采用了這種存儲方案,我們才能夠將自己成為精細化用戶行為分析系統,才能夠滿足使用者的最細粒度數據分析和獲取的需求。
在這樣一個數據存儲方案的基礎上,為了提高數據查詢的效能,一般的優化思路有采用列存儲加壓縮的方式減少從磁盤中掃描的數據量,采用分布式的方案提高并發掃描的性能,采用應用層緩存來減少不同查詢的公共掃描數據的量等等,這方面的內容我們會在后面的文章里面做進一步的探討,盡請期待