基于改進字典的大數據多維分析加速實踐
一、背景
OLAP場景是大數據應用中非常重要的一環,能夠快速、靈活地滿足業務各種分析需求,提供復雜的分析操作和決策支持。B站主流湖倉使用Iceberg存儲,通過建表優化可以實現常規千萬級的指標統計秒級查詢,這樣就能快速搭建可視化報表,但當數據量達到億級、需要交叉分析維度復雜多表情況下,想要支持秒級就變得困難。因此B站數據分析或者數據開發同學為了能有秒級響應的報表,需要通過ETL grouping sets 提前設計要參與多維分析的維度和指標,然后在ADS層離線計算好對應的數據cube。這有點類似Kylin的預計算模式,區別是查詢效率和查詢SQL復雜度要更高,畢竟Kylin底層是KV存儲并且做了SQL解釋器,而原始grouping sets模式得讓下游自己選cube切片。比如Push業務DWB表幾十億數據量,想要快速支持十幾個維度和十幾個指標秒級交叉分析,只能開發提前配置好要參與分析的維度組合,在可視化界面也需要提前說明只支持這幾個維度組合。
OLAP引擎中Kylin 也逐漸被淘汰了,因為只能預計算而不能現算,要滿足新的分析維度視角和指標得重新配置和數據同步成本巨大,當然ETL grouping sets這種更原始的方式成本只會更大,以下列舉了數據平臺ETL任務中用到grouping sets 預計算所使用資源開銷:
ETL種類 | 任務數 | CPU開銷/cpu_vcore_d | 內存開銷/mmr_tb_d |
多維分析任務 | 563(0.7%) | 4448.90(10.8%) | 5.43(33.2%) |
當前多維分析的任務只占總任務數不到1%,卻貢獻了10.8%的CPU日開銷和33.2%的內存日開銷,實屬浪費,下游ADS報表使用極其繁瑣,運維成本較大。
B站當前主流OLAP引擎是ClickHouse,和主流引擎Doris、StarRocks一樣,ClickHouse同樣采用MPP架構和列式存儲格式,可以滿足億級數據量的秒級甚至亞秒級查詢,其專注于OLAP場景優化,但在join操作和讀QPS上不如Doris、StarRocks高效。報表場景下對QPS要求不高,但join能力要能跟上,而小數據量join 性能影響就不大了,為此我們計劃將大表加工成聚合小表,即滿足多維分析場景,也能滿足外部擴展join場景。
為了保證指標和維度一致性,避免重復加工和數據冗余、歧義,我們將這種ClickHouse聚合加速功能集成在指標服務平臺(OneService,OS),由OS統一做加速配置、API注冊、SQL查詢解析。此外,聚合加速的難點在于對去重指標的處理,因此除了涉及聚合數據模型設計、數據同步、OS工程集成,本文還會詳細闡述如何將字符串的去重實體轉化為ClickHouse的去重聚合實體集合 groupBitmap(即RoaringBitmap,RBM),如何生成映射字典去滿足多個RBM能夠快速交并差運算。
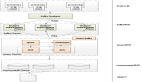
二、總體架構設計圖
 圖片
圖片
三、數據方案設計
3.1 模型設計
多維分析加速的核心是如何設計數據聚合方案,滿足多維快速分析場景。按照指標是否去重,所有的多維聚合分析指標按照其所在數倉模型可以被拆分成兩部分:一、無需去重計算,即所需要的指標直接在需要分析的維度上進行聚合處理,比如max、count、sum等,這類對應數倉模型通常無需關注實體或者實體粒度唯一;二、 需要去重計算,例如UV(Unique Vistor)、PU(Paid User)、RU(Revenue User)、DAU(Daily Active User)等,如果所在模型粒度不是要去重的實體,則必須使用distinct去重運算 。實際數倉模型設計中兩者皆有的情況占大多數,即實體不唯一,而實體產生的業務指標又可累加,因此需要同時設計兩種聚合模式。以播放為例,假如有張播放DWB表,每日1億條記錄,定義如下:
Play_dwb_tbl(
uid bigint comment '用戶ID'
,deviceID string comment '設備ID'
,area_id bigint comment '分區ID'
,area_name string comment '分區名'
,uid_city string comment '用戶自填城市'
,uid_gender string comment '用戶自填性別'
,play_duration bigint commnet '播放時長'
,dt string '統計日期'
)想要統計在不同維度組合的播放時長、播放用戶數、播放設備數。
直接聚合模式,即對無需去重的指標組合其維度生成聚合表。以上面案例舉例,播放時長指標不依賴實體可直接累加,生成如下表:
Play_dwb_tbl_aggr_directly(
area_id bigint comment '分區ID'
,area_name string comment '分區名'
,uid_city string comment '用戶自填城市'
,uid_gender string comment '用戶自填性別'
,paly_duration bigint commnet '播放時長'
,dt string '統計日期'
)結果每日大概1萬條記錄,將這1萬條記錄導入到OLAP引擎可以快速滿足任意多維分析需求。這種模式比較簡單和傳統,本文重點講另一種模式。
去重聚合模式,即對需要去重的指標生成聚合表。以上面案例舉例,播放用戶數、播放設備數就是分別對用戶和設備兩種不同實體的聚合。分析其ER關系可知,性別、城市由uid唯一映射,但同一個設備可能有多個uid,因此不能被設備ID唯一映射;分區ID和分區名屬于聯合維度,一一對應不可分割。根據ER關系劃分維度組合,相同維度分析不同指標底層的實現復雜度相差極大。對于播放設備數,uid和分區是其必要維度,uid雖然是實體不需要參與分析,但其關聯維度需要放入,最終全維度放入聚合維度池;對于播放用戶數,由于存在實體的唯一映射,可以劃分3個維度組合(dt、uid_city)、 (dt、uid_gender)、 (dt、area_id、area_name) 放入聚合維度池,可以利用三個維度對應實體集合交并實現多維分析(這里實體集合的生成涉及字典服務,后文會詳解),相對于全維度組合其組合枚舉值大大減少。去重聚合模式的維度劃分邏輯如下圖所示:
 圖片
圖片
對于entityM,根據ER關系中有多少個唯一映射就可以拆多少個維度集合,剩下不能再唯一映射的維度當成實體關聯維度打包成一個維度集合。
通過以上實例分析,不管哪種聚合模式都可能存在維度組合爆炸情況,極端情況其聚合模型的記錄數和原模型一致,就沒有聚合加速的優勢。實際情況下我們的聚合模型是要面向可視化報表、面向實際業務分析場景,不可能需要到實體粒度的維度組合展現,因此在生產聚合模型的時候系統會自動檢查參與分析的維度組合數量是不是超標。此外還有一些其他規則,比如日期維度需要強制選擇,去重實體在字典服務中存在映射字典等等。整體數據流程見下圖:
 圖片
圖片
接下來重點講下去重聚合模式(RBM aggr)在ClickHouse中的的設計、同步實現和查詢。
3.2 Schema設計
 圖片
圖片
dim_name和dim_value包含多種維度組合,分別代表維度名和維度值。實際查詢中必用ind_name,dim_name大部分場景都會使用, 因此設計成LowCardinality(String)意味著它可以有效地壓縮重復字符串值,從而減少存儲空間的使用,其使用的字典編碼還可以提高查詢的性能。在統計每日的去重實體數時不需要ind_name,這也是很頻繁的場景,因此我們還添加了Projection操作預計算:
PROJECTION projection_logdate (
SELECT dt, ind_name, groupBitmapOrState(ind_rbm) ,count(1)
GROUP BY dt, ind_name
)這樣就沒必要掃描所有dim_name去重復統計(每個dim_name算出的來的去重實體數必然一樣),另外在執行'!='操作的時,完全可以拿這個預計算結果和右邊的維度值對應的ind_rbm做差集馬上可以得到結果,性能和算'='一樣。此外dim_value添加布隆過濾索引,針對多維篩選可以加速分析。
3.3 數據同步
 圖片
圖片
完整的數據同步圖如上圖所示。dwb_tbl為待同步的原始數據模型,sync_tbl為待同步到ClickHouse的數據模型,和目標表的Schema一樣,整個過程核心包含三個步驟,以下詳述S1, S2, S3三個步驟的內容。
S1:產出預加工模型,其結構如下:
Temp_1(
dt string comment '日期'
,ind_name string comment '指標名'
,ind_value string comment '實體值'
,dims_map map<string,string> comment '{dim_name:dim_value}'
)目標是將不同的原數據模型加工成統一模型表以適配后續流程。用戶選擇要分析的維度和指標,而這些維度和指標在OS上可以二次定義或者衍生,OS自動生成產出這些維度和指標的SQL,之后統一封裝成預加工模型。這里ind_value為要去重指標的實體值,這個實體值不管是數值還是字符串,統一存儲為字符串格式。dims_map聚合了后續需要的dim_name和dim_value,目的是保證ind_value粒度,后續轉化字典的時候不需要重復請求,降低計算成本。
S2:獲取映射字典,即將ind_value轉化為預設的稠密字典值,實現字符轉數字。通過OS拿到指標實體所用的字典,這里優先會請求已有的離線映射字典表(若未就緒自動取最新分區數據),如果獲取不到再請求字典服務申請新的字典,新的記錄后續會離線存放到映射字典表中,避免后續再重復請求,降低字典服務壓力,讓億級別數據量能分鐘級生成字典。
S3:產出要同步到ClickHouse的數據模型。由于目標表是分布式CK聚合表,這里需要根據實體的字典值映射到要寫入的shard,按照指標名+維度+shard粒度對這些字典值進行RBM聚合操作。
3.4 數據查詢
查詢場景有很多,這里主要說明下多維分析在已知篩選條件下的查詢實現。以上述播放數據為例,對應ClickHouse本地表為Play_ck_tbl_local,分布式表為Play_ck_tbl,分別查詢某日的上海用戶在分區ID為1下的播放指標:
-- example1.查詢播放用戶數
select
sum(`播放用戶數`)
from cluster('XXX', view(
select
bitmapAndCardinality(a.ind_rbm, b.ind_rbm) AS `播放用戶數`
from(
select
ind_rbm
from Play_ck_tbl_local
where dt='XX' and ind_name='播放用戶數' and dim_name='uid_city' and dim_value[1]='上海'
)a join (
select
ind_rbm
from Play_ck_tbl_local
where dt='XX' and ind_name='播放用戶數' and dim_name='area_id' and dim_value[1]='1'
)b on 1=1
)tmp
-- example2.查詢播放設備數
select
bitmapCardinality(groupBitmapOrState(ind_rbm)) `播放設備數`
from Play_ck_tbl
where dt='XX' and ind_name='播放設備數' and dim_name = 'area_id,area_name,uid_city,uid_gender'
and dim_value[1]='1' and dim_value[3]='上海'兩個指標維度一樣,但查詢邏輯有很大不同。播放用戶數指標對應多個維度集合存儲,需要將涉及到的維度集取出后做關聯取交集運算,由于本地表是按照實體字典做了分shard處理,因此只要實現本地Colocate Join邏輯后求和即可得到結果。播放設備數指標只有一個維度集合,這個維度集合包含了想要參與多維分析的所有維度值組合,因此只要限制維度值數組指定位置取值為篩選條件即可。
需要注意的是前面限制維度基數的原因在這里可以體現。如果有多個維度集合需要join運算,要求每個維度集合不能太多,我們利用的是ClickHouse小數據量join能力,如果太大會帶來性能損耗,無法滿足秒級查詢要求。
四、字典服務方案的優化演進
4.1 基于Snowflake算法的字典服務
Snowflake是Twitter開源的一種分布式ID生成算法。基于64位數實現,下圖為Snowflake算法的ID構成圖:
 圖片
圖片
- 第1位置為0。第2-42位是相對時間戳,通過當前時間戳減去一個固定的歷史時間戳生成。第43-52位是機器號workerID,每個Server的機器ID不同。第53-64位是自增ID。通過時間+機器號+自增ID的組合來實現完全分布式的ID下發
- Leaf提供了Java版本的實現,同時對Zookeeper生成機器號做了弱依賴處理,即使Zookeeper有問題,也不會影響服務。Leaf在第一次從Zookeeper拿取workerID后,會在本機文件系統上緩存一個workerID文件。即使ZooKeeper出現問題,同時恰好機器也在重啟,也能保證服務的正常運行。這樣做到了對第三方組件的弱依賴,一定程度上提高了SLA。
4.2 用離散數據構建Bitmap的問題
基于snowflake算法生成的字典值在連續數值空間上的分布是相對離散的,所以基于snowflake字典構建的bitmap中的數據也是比較離散的。ClickHouse使用RoaringBitmap存儲bitmap數據,而由于RoaringBitmap的結構設計,使其并不適合用于存儲和計算由離散數據構建而成的bitmap。下面我們從RoaringBitmap的結構原理出發,闡述離散數據分布下bitmap存儲和計算所面臨的問題。
一個32位RoaringBitmap的內部結構如下圖:
 圖片
圖片
首先以數字的高16位來確定分桶,然后低16存儲到對應container中。
根據存儲數據的數量和分布情況,會使用不同種類的container來使計算更加高效。
- Array Container:桶內數據小于4096個,計算效率低
- Bitmap Container:桶內數據大于4096個,計算效率高
- Run Container:對連續數字使用RLE編碼來壓縮空間,最省空間
針對64位的bitmap,則是先將64位整型的高32位分桶,低32位則使用RoaringBitmap32表示。
通過上述對RoaringBitmap結構的分析,我們可以看出,存入bitmap的數據連續性越高,則bitmap的存儲空間就越小,計算效率也越高。
基于Snowflake算法生成的字典值連續性低,高位稠密,低位稀疏,導致生成的roaring bitmap中包含大量的array container,從而導致bitmap計算消耗大量內存資源,且計算效率非常低。
4.3 ClickHouse稠密字典編碼服務體系
為了解決RoaringBitmap因數據連續性低而導致存儲計算效率低的問題,我們圍繞ClickHouse建設了一套稠密字典編碼服務體系。
術語說明:
- 正向查詢:用原始key值查詢對應的字典值value。
- 反向查詢:用字典值value查詢對應的原始key。
4.3.1 架構設計圖
 圖片
圖片
4.3.2 功能模塊簡介
稠密字典編碼服務體系包括以下幾個模塊:
- ClickHouse字典編碼模塊:在ClickHouse內部新增BidirectionalDictionary功能支持,同時支持了各種dictionary functions,從支持數據在寫入過程中在ClickHouse內部完成字典編碼與轉換,最終生成連續字典值的bitmap數據。
- Dict Service:提供字典管理(新建,刪除等),字典keyToValue,valueToKey查詢代理,查詢緩存,批量查詢等功能。既可供ClickHouse內部生成字典值bitmap數據使用,也可通過Dict Client, Dict UDF供外部數據同步組件用于生成bitmap數據后導入ClickHouse。
- Dict Client:Dict Service的客戶端,用于連接Dict Service完成字典正向查詢/更新和字典反向查詢,同時提供查詢緩存,批量查詢等功能。
- Dict UDF:為數據同步組件提供Spark UDF/UDAF用于字典值轉換及bitmap數據生成,以便在ClickHouse之外預先生成字典編碼的bitmap數據。
- Distribute KV:基于RocksDB的分布式KV存儲,用于存儲正反向字典數據,同時提供全局自增器生成自增的字典值。
4.3.3 Dict Service實現方案詳述
Dict Service維護了所有的字典元數據,客戶端連接Dict Service做字典正向和反向查詢。Dict Service的運行實例是無狀態無鎖的,所以Dict Service可以做分布式可擴展部署,狀態同步完全依靠分布式KV存儲進行,通過各種容錯機制保證字典數據的正確性。
字典正向查詢與更新流程圖:
 圖片
圖片
字典正向查詢與更新流程步驟說明:
- 輸入的keys,首先會查詢正向字典,如果能夠全部命中,則向客戶端返回values。
- 對于未命中的keys,首先將其進行排序去重,然后使用全局自增器分配映射值。
- 將完成映射的values → keys批量寫入反向字典。
- 使用CAS操作,將keys → values寫入正向字典,若發生CAS沖突,則將該key的value替換為old value。
- 向客戶端返回values。
- 回收掉由于CAS沖突而未使用到的values,用于下次分配。
對于字典值,我們在KV存儲中采用大端方式表示,這樣可以使得反向查詢效率更高,原因如下:
Dict Service應用于bitmap計算場景,用戶在反向查詢時,從bitmap讀取數值序列并請求Dict Service做批量查詢,取出的查詢目標數值序列是有序的,而使用大端方式存儲字典值能夠保證字典值在KV存儲中也是按照數值順序排序的,這樣查詢目標數值序列和存儲的字典值序列就都是按同樣順序排好序的,這對于使用LSM結構的RocksDB而言查詢會更加高效。
4.4 bitmap計算的優化效果
基于B站真實用戶行為數據,我們分別基于Snowflake算法字典服務和ClickHouse稠密字典編碼服務對用戶設備id做字典編碼后,對比了兩者在bitmap計算場景下的性能差異:

說明:測試數據為用戶行為表連續七天某一時間段的所有數據,用戶設備id基數約為1000萬。
五、工程應用接入
5.1 前置工作
邏輯模型定義
用戶期望對于已有的明細表進行物化加速, 首先需預先定義好數據模型, 包括模型中包含的指標維度, 其中
- 指標定義: 對某實體進行去重計數來計算指標, 則較為適用于rbm加速方案。反之則使用原有的聚合計算加速方式即可, 如sum, max, min, count等計算指標等。
- 如對[播放記錄表]中設備與用戶進行去重計數計算, 可產出[播放設備數]及[播放用戶數]指標。
 圖片
圖片
- 實體定義: 一般來說會對, 例如: 設備id, 用戶id等一系列id類信息進行去重計數, 此類信息字段即為計算實體, 并會在后續流程中, 通過字典服務將實體轉換為稠密的bitmap結構(rbm)。
- 維度定義: 在模型中定義, 按某些維度對相關指標進行分析。簡單理解就是需要對于哪些維度進行分組聚合(group by)。
- 主鍵維定義: 對于需要計算的實體字段, 必須是模型定義中的[主鍵]或[與某些維度組合后為主鍵]進行rbm數據生產, 否則會出現指標計算出現誤差。
- 此處設計是基于上文[數據設計]部分所闡述的[維度組合]方案的一種讓步, 考慮到用戶對于維度組合的理解成本過高, 且產品交互設計復雜, 進行了一定的取舍。通過主鍵維定義的方式解決計算誤差問題, 雖會犧牲一定的查詢性能與更多的數據存儲, 但對于用戶來說設置主鍵維更好理解, 操作也更便捷。未來支持維度組設置, 也可依據一定的策略規則自動識別維度組, 減少用戶配置成本。
- 用戶開啟rbm加速開關, 并設置合理的主鍵信息, 即可使用rbm的加速特性
 圖片
圖片
主鍵維定義case
假設我們有如下數據, 其中buvid在pid維度下唯一, 并對 pid, is_new 2個維度字段產出dau指標(對buvid進行去重計數計算)

當我們要分析, pid = 'android' and is_new = 'n' 維度下的dau時
- 常規sql分析方式:
select pid, is_new, count(distinct buvid) as dau
from tbl where pid = 'android' and is_new = 'n'- 產出結果為 dau=1, 其中命中此條件的buvid為'b'
- 未定義主鍵維方式:
- 對 pid = 'android' 與 is_new = 'n' 的2個rbm交集計算后得出的rbm為 [a=1, b=1]
- 產出的結果為 dau=2, 可見這個結果是錯誤的
- 定義主鍵維方式:
- 定位到 [pid, is_new] = [android, n] 的rbm為 [a=0, b=1]
- 產出的結果為 dau=1, 符合預期
示例:
假設我們已經定義好一個模型
 圖片
圖片
5.2 數據加速
在進行完模型定義后, 就可對其數據進行加速處理, 我們選擇將加速數據寫入olap引擎clickhouse中。
去重計數指標
首先對于需要去重計數的指標, 通過以上模型定義, 系統自動翻譯出如下SQL, 提供至[數據同步]S1部分闡述的任務。
其中需要查詢出每個實體命中各維度的維度值有哪些。
SELECT
log_date AS log_date,
CASE WHEN grouping(`dau`) = 0 THEN 'dau' END AS ind_name, -- 指標名
CASE WHEN grouping(`dau`) = 0 THEN `dau` END AS ind_value, -- 指標對應實體值,如此例中的buvid
map_group(dim_map) AS dims_map -- 分組聚合所有map中的元素,即為實體命中各維度的維度值
FROM
(
SELECT
log_date AS log_date,
COALESCE(CAST(dau AS string), '') AS dau,
map(
'pid',
COALESCE(CAST(pid AS string), ''), -- 實體命中的pid
'pid,device_brand', -- 主鍵維列表 拼接 單個非主鍵維
CONCAT_WS(',',
COALESCE(CAST(pid AS string), ''), -- 實體命中的pid
COALESCE(CAST(device_brand AS string), '') -- 實體命中的設備品牌
),
... -- 主鍵維列表 拼接 其余單個非主鍵維
) AS dim_map
FROM
( ... ) l1 -- 模型定義標準化
) l2
GROUP BY
log_date,
dau
GROUPING SETS((log_date, `dau`)) -- 按不同指標計算grouping setsSQL查詢出的結果樣例如下, 其中ind_name表示指標名, ind_value是產出此指標的某個實體, dims_map則是該實體命中各維度的維度值。
 圖片
圖片
例如: 第一行中的buvid命中的pid=1124, device_brand=official, is_new_user=0。
又因主鍵維定義, 實際會將device_brand, is_new_user維度分別與pid主鍵維進行組合處理, log_date本身是單獨的分區字段, 則無需再進行組合。
[數據同步]任務獲取到數據后, 即會進行實體字段轉換并將數據寫入ck聚合表中, 具體結構見上文[Schema 設計], 此處不再贅述。
ck聚合表數據樣例如下, 通過bitmapCardinality函數可計算出rbm的基數值, 業務含義上即為該維度下DAU指標。后續進行多維分析時, 針對rbm進行交并計算即可得到期望值。
 圖片
圖片
非去重計數指標
本樣例中即為vv指標, 通過模型定義中的維度, 簡單分組聚合計算加速即可, SQL樣例如下:
SELECT
log_date, pid, device_brand, is_new_user, -- 分析維度
SUM(vv) AS vv -- sum計算指標
FROM
( ... ) l1 -- 模型定義標準化
GROUP BY
log_date, pid, device_brand, is_new_user -- 分析維度物化模型
數據服務對于邏輯模型加速后的數據, 會對應生成物化模型的定義信息。rbm加速與聚合加速會分別創建2個物化模型定義, 兩者包含的維度一致, 而指標不同。定義對比如下:
邏輯模型 | 聚合物化模型 | rbm物化模型 | |
維度 | pid, device_brand, is_new_user | ||
指標 | dau, vv - 包含所有指標 | vv - 包含非去重計數指標 | dau - 僅包含去重 |
 圖片
圖片
5.3 查詢分析
基于以上物化加速后的數據, 數據服務即可通過物化模型定義, 翻譯出對應的查詢SQL。其中應用了[星座模型]的查詢特性, 將2個物化模型, 分別作為2個事實表模型對待, 進行處理。復用了OneService原有的多模型查詢能力。
SQL對比
rbm物化表對于查詢SQL的翻譯與普通數據表存在差異, 以下對比了2種不同SQL的處理特點:
 圖片
圖片
以下以最復雜的 [主鍵維+多維非主鍵維分析dau與vv指標] 查詢模式舉例:
維度過濾 log_date = '20240609' and pid = 13 and is_new_user = 1
SELECT
xxx, -- 分析維度
0 AS vv, sum(dau) AS dau -- rbm物化模型不產出vv指標,產出去重計數指標dau,此處應用ck的shard特性,對多shard間的rbm基數進行sum計算
FROM
cluster('xxx', view( -- ck多shard查詢優化
SELECT
cast(device_brand AS String) AS device_brand, xxx, -- 由于rbm物化表中維度值均為string類型,需將其轉換回原始類型
ind_name AS ind_name, sum(bitmapAndCardinality(device_brand_tbl.ind_rbm, is_new_user_tbl.ind_rbm)) AS ind_rbm, -- ck特性,先統一取交計算好各非主鍵維下rbm,提升查詢性能
if(ind_name = 'dau', ind_rbm, 0) AS dau, if(ind_name = 'xxx', ind_rbm, 0) AS xxx -- 若有,可計算其他去重計數指標
FROM
( SELECT
dim_value[2] AS device_brand, dim_value[1] AS pid, -- 對應dim_name='pid,device_brand'順序,數組第二位為device_brand,數組第一位為pid
ind_name AS ind_name, groupBitmapOrState(ind_rbm) AS ind_rbm -- 同維度rbm進行并集計算
FROM rbm_physics_tbl_local -- 查詢rbm_physics_tbl分shard后的local表,性能優化
WHERE (ind_name in ('dau')) -- 指標選擇
AND (log_date = '20240609') AND (dim_name = 'pid,device_brand') AND (dim_value[1] = '13') -- 維度過濾,此處等價于log_date=20240609 and pid=13
GROUP BY ind_name, dim_value[2], dim_value[1] -- 等價于ind_name, device_brand, pid -- 多維分組
) AS device_brand_tbl -- 定義device_brand維度邏輯視圖
-- pid與is_new_user維度對應邏輯視圖
INNER JOIN ( xxx ) AS is_new_user_tbl ON is_new_user_tbl.ind_name = device_brand_tbl.ind_name -- 多邏輯視圖必須按ind_name條件join,否則會出現笛卡爾積
AND is_new_user_tbl.pid = device_brand_tbl.pid -- 多邏輯視圖公共維join條件
-- 若有其他非主鍵維邏輯視圖,以相同規則進行join
INNER JOIN ( xxx ) ON xxx
GROUP BY device_brand, is_new_user, pid, ind_name -- 按分析維+ind_name分組
)) v
GROUP BY device_brand, is_new_user, pid -- 多維分組sql邏輯說明:
1.最內層處理
a. 維度過濾需要通過對dim_value數組進行轉換, 保證語義與普通where過濾一致, 并對映射后的分析維+指標名進行分組, 聚合同維度下rbm進行并集計算
b. 對于非主鍵維, 需定義不同子查詢, 同時進行inner join操作, join鍵為指標名+分析維度中的公共維, 需要分析N個非主鍵維就需要join N-1次。若分析維度中僅包含主鍵維, 則無需進行join操作, 定位到dim_name='主鍵維'即可
c. 由于經過了底層一系列的join操作, 若分析維度或過濾條件設置不當, 可能造成join后維度基數爆炸, 會引起較為嚴重的影響, 具體在后文[穩定性保障]部分進行說明
2.第二層處理
a. 由于rbm加速物化表中的維度值均是以string類型進行存儲, 而轉換前的原表字段有對應的實際類型, 在join邏輯后需要進行反轉
b. 在此層, 利用ck特性, 先統一取交計算好各非主鍵維下rbm基數和, 可有效提升查詢性能。若直接獲取rbm基數進行指標轉換, 也可達成相同效果, 但查詢耗時會隨著非主鍵維數量, 乘倍上升
3.第三層處理
a. 利用ck分片特性, 進行local本地計算rbm基數合后, 再對各分片基數求和, 最終產出對應指標值
4.跨模型指標處理-可選
a. 應用[星座模型]查詢實現, 分別將 [聚合物化模型]中非rbm加速的普通計算指標vv 與 [rbm物化模型]中rbm加速的去重計數指標dau, 通過union方式聚合到相同維度下, 最終返回完整結果集
性能對比
以下統計的響應時間不包含數據傳輸的io耗時

維度基數對于性能的影響
如下可觀察到, 耗時隨維度基數增加而線性增加
 圖片
圖片
 圖片
圖片
穩定性保障
加速保障: 對維度基數過大的數據進行加速, 會生成非常多的rbm結構數據。不僅加速過程中需要消耗平臺極多的資源, 加速時間很長, 同時查詢時的性能提升也極為有限。此類情況在用戶配置加速時, 會進行數據探查校驗, 并在準入階段進行攔截。
查詢保障: 為保障對rbm加速數據查詢的穩定性, 避免單次查詢中涉及交并計算的rbm過多, 加載大量數據至內存引起集群穩定性下降。我們在實際查詢數據前, 先對數據進行了一次基數探查, 對于基數大于某閾值的查詢, 直接進行攔截阻斷, 避免對集群造成過多壓力, 此類查詢本身消耗資源較多, 且多數情況也無法在要求的時間內響應數據。基數探查是通過count計算出部分維度組合的數量, 查詢性能較好, 一般在1s內能響應, 實際數據查詢通常是秒級返回, 1s內的耗時損耗還是在接受范圍內, 且用戶體感也不十分明顯, 是必要的前置校驗保障。
六、未來展望
工程化支持[維度組合]方式加速rbm結構, 將能定位唯一粒度實體維度組合以最小組合方式建立, 可有效減少rbm結構數據的數量。節省存儲的同時, 也提升查詢性能。
目前bitmap數據主要是在離線鏈路生成完后寫入clickhouse,后續將基于ClickHouse 字典服務構建bitmap數據生成與更新的實時鏈路,提升整體產品的實時分析場景能力。
引用
- Roaring Bitmaps: Implementation of an Optimized Software Library(https://arxiv.org/pdf/1709.07821)
- WeOLAP 亞秒級實時數倉 —— BitBooster 10倍查詢優化實踐(https://mp.weixin.qq.com/s/tJQoNRZ5UDJ_IASZLlhB4Q)