Flink實時計算Pv、Uv的幾種方法
本文轉載自微信公眾號「Java大數據與數據倉庫」,作者柯少爺。轉載本文請聯系Java大數據與數據倉庫公眾號。
實時統計pv、uv是再常見不過的大數據統計需求了,前面出過一篇SparkStreaming實時統計pv,uv的案例,這里用Flink實時計算pv,uv。
我們需要統計不同數據類型每天的pv,uv情況,并且有如下要求.
- 每秒鐘要輸出最新的統計結果;
- 程序永遠跑著不會停,所以要定期清理內存里的過時數據;
- 收到的消息里的時間字段并不是按照順序嚴格遞增的,所以要有一定的容錯機制;
- 訪問uv并不一定每秒鐘都會變化,重復輸出對IO是巨大的浪費,所以要在uv變更時在一秒內輸出結果,未變更時不輸出;
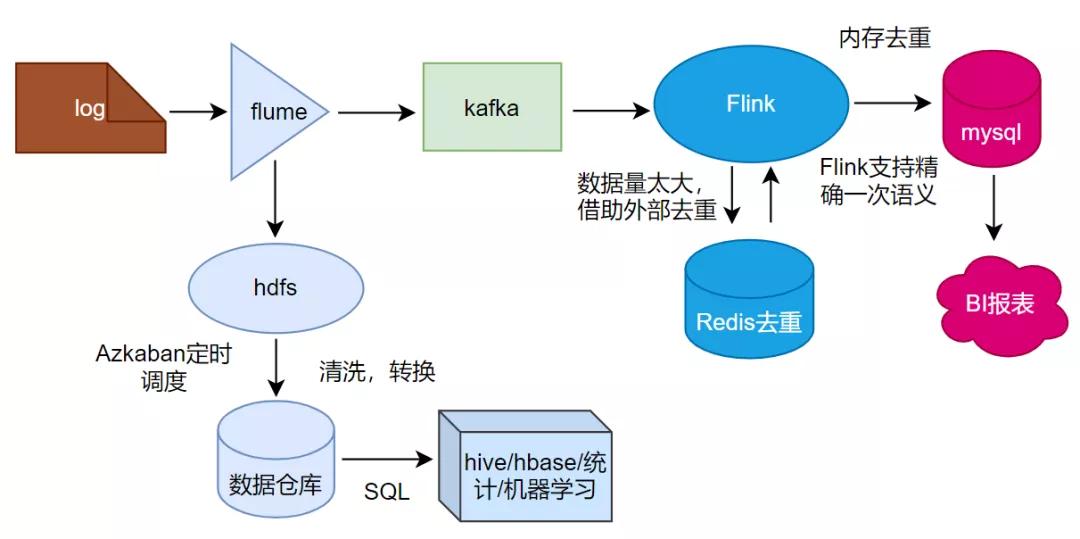
Flink數據流上的類型和操作
DataStream是flink流處理最核心的數據結構,其它的各種流都可以直接或者間接通過DataStream來完成相互轉換,一些常用的流直接的轉換關系如圖:
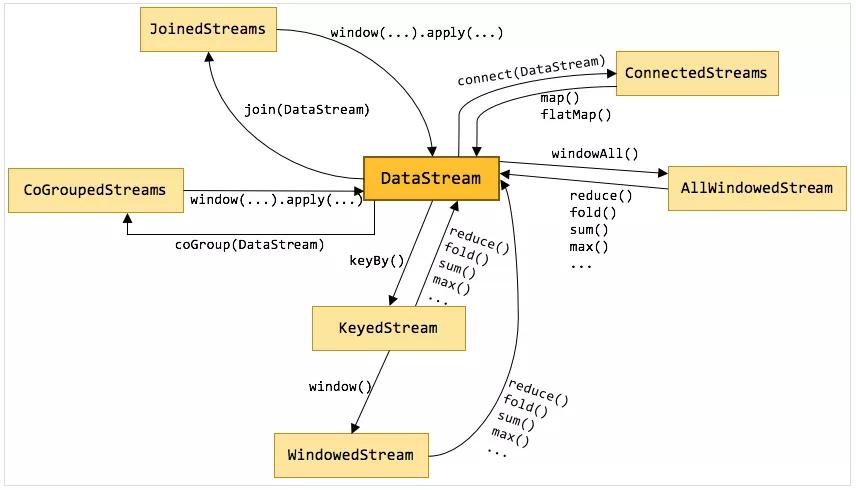
可以看出,DataStream可以與KeyedStream相互轉換,KeyedStream可以轉換為WindowedStream,DataStream不能直接轉換為WindowedStream,WindowedStream可以直接轉換為DataStream。各種流之間雖然不能相互直接轉換,但是都可以通過先轉換為DataStream,再轉換為其它流的方法來實現。
在這個計算pv,uv的需求中就主要用到DataStream、KeyedStream以及WindowedStream這些數據結構。
這里需要用到window和watermark,使用窗口把數據按天分割,使用watermark可以通過“水位”來定期清理窗口外的遲到數據,起到清理內存的作用。
業務代碼
我們的數據是json類型的,含有date,version,guid這3個字段,在實時統計pv,uv這個功能中,其它字段可以直接丟掉,當然了在離線數據倉庫中,所有有含義的業務字段都是要保留到hive當中的。其它相關概念就不說了,會專門介紹,這里直接上代碼吧。
- <?xml version="1.0" encoding="UTF-8"?>
- <project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
- <groupId>com.ddxygq</groupId>
- <artifactId>bigdata</artifactId>
- <version>1.0-SNAPSHOT</version>
- <properties>
- <scala.version>2.11.8</scala.version>
- <flink.version>1.7.0</flink.version>
- <pkg.name>bigdata</pkg.name>
- </properties>
- <dependencies>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-scala_2.11</artifactId>
- <version>{flink.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-scala_2.11</artifactId>
- <version>flink.version</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-java_2.11</artifactId>
- <version>{flink.version}</version>
- </dependency>
- <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka-0.8 -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-kafka-0.10_2.11</artifactId>
- <version>flink.version</version>
- </dependency>
- <build>
- <!--測試代碼和文件-->
- <!--<testSourceDirectory>{basedir}/src/test</testSourceDirectory>-->
- <finalName>basedir/src/test</testSourceDirectory>−−><finalName>{pkg.name}</finalName>
- <sourceDirectory>src/main/java</sourceDirectory>
- <resources>
- <resource>
- <directory>src/main/resources</directory>
- <includes>
- <include>*.properties</include>
- <include>*.xml</include>
- </includes>
- <filtering>false</filtering>
- </resource>
- </resources>
- <plugins>
- <!-- 跳過測試插件-->
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-surefire-plugin</artifactId>
- <configuration>
- <skip>true</skip>
- </configuration>
- </plugin>
- <!--編譯scala插件-->
- <plugin>
- <groupId>org.scala-tools</groupId>
- <artifactId>maven-scala-plugin</artifactId>
- <version>2.15.2</version>
- <executions>
- <execution>
- <goals>
- <goal>compile</goal>
- <goal>testCompile</goal>
- </goals>
- </execution>
- </executions>
- </plugin>
- </plugins>
- </build>
- </project>
主要代碼,主要使用scala開發:
- package com.ddxygq.bigdata.flink.streaming.pvuv
- import java.util.Properties
- import com.alibaba.fastjson.JSON
- import org.apache.flink.runtime.state.filesystem.FsStateBackend
- import org.apache.flink.streaming.api.CheckpointingMode
- import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
- import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
- import org.apache.flink.streaming.api.windowing.time.Time
- import org.apache.flink.streaming.api.windowing.triggers.ContinuousProcessingTimeTrigger
- import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010
- import org.apache.flink.streaming.util.serialization.SimpleStringSchema
- import org.apache.flink.streaming.api.scala.extensions._
- import org.apache.flink.api.scala._
- /**
- * @ Author: keguang
- * @ Date: 2019/3/18 17:34
- * @ version: v1.0.0
- * @ description:
- */
- object PvUvCount {
- def main(args: Array[String]): Unit = {
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- // 容錯
- env.enableCheckpointing(5000)
- env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
- env.setStateBackend(new FsStateBackend("file:///D:/space/IJ/bigdata/src/main/scala/com/ddxygq/bigdata/flink/checkpoint/flink/tagApp"))
- // kafka 配置
- val ZOOKEEPER_HOST = "hadoop01:2181,hadoop02:2181,hadoop03:2181"
- val KAFKA_BROKERS = "hadoop01:9092,hadoop02:9092,hadoop03:9092"
- val TRANSACTION_GROUP = "flink-count"
- val TOPIC_NAME = "flink"
- val kafkaProps = new Properties()
- kafkaProps.setProperty("zookeeper.connect", ZOOKEEPER_HOST)
- kafkaProps.setProperty("bootstrap.servers", KAFKA_BROKERS)
- kafkaProps.setProperty("group.id", TRANSACTION_GROUP)
- // watrmark 允許數據延遲時間
- val MaxOutOfOrderness = 86400 * 1000L
- // 消費kafka數據
- val streamData: DataStream[(String, String, String)] = env.addSource(
- new FlinkKafkaConsumer010[String](TOPIC_NAME, new SimpleStringSchema(), kafkaProps)
- ).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[String](Time.milliseconds(MaxOutOfOrderness)) {
- override def extractTimestamp(element: String): Long = {
- val t = JSON.parseObject(element)
- val time = JSON.parseObject(JSON.parseObject(t.getString("message")).getString("decrypted_data")).getString("time")
- time.toLong
- }
- }).map(x => {
- var date = "error"
- var guid = "error"
- var helperversion = "error"
- try {
- val messageJsonObject = JSON.parseObject(JSON.parseObject(x).getString("message"))
- val datetime = messageJsonObject.getString("time")
- date = datetime.split(" ")(0)
- // hour = datetime.split(" ")(1).substring(0, 2)
- val decrypted_data_string = messageJsonObject.getString("decrypted_data")
- if (!"".equals(decrypted_data_string)) {
- val decrypted_data = JSON.parseObject(decrypted_data_string)
- guid = decrypted_data.getString("guid").trim
- helperversion = decrypted_data.getString("helperversion")
- }
- } catch {
- case e: Exception => {
- println(e)
- }
- }
- (date, helperversion, guid)
- })
- // 這上面是設置watermark并解析json部分
- // 聚合窗口中的數據,可以研究下applyWith這個方法和OnWindowedStream這個類
- val resultStream = streamData.keyBy(x => {
- x._1 + x._2
- }).timeWindow(Time.days(1))
- .trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(1)))
- .applyWith(("", List.empty[Int], Set.empty[Int], 0L, 0L))(
- foldFunction = {
- case ((_, list, set, _, 0), item) => {
- val date = item._1
- val helperversion = item._2
- val guid = item._3
- (date + "_" + helperversion, guid.hashCode +: list, set + guid.hashCode, 0L, 0L)
- }
- }
- , windowFunction = {
- case (key, window, result) => {
- result.map {
- case (leixing, list, set, _, _) => {
- (leixing, list.size, set.size, window.getStart, window.getEnd)
- }
- }
- }
- }
- ).keyBy(0)
- .flatMapWithState[(String, Int, Int, Long, Long),(Int, Int)]{
- case ((key, numpv, numuv, begin, end), curr) =>
- curr match {
- case Some(numCurr) if numCurr == (numuv, numpv) =>
- (Seq.empty, Some((numuv, numpv))) //如果之前已經有相同的數據,則返回空結果
- case _ =>
- (Seq((key, numpv, numuv, begin, end)), Some((numuv, numpv)))
- }
- }
- // 最終結果
- val resultedStream = resultStream.map(x => {
- val keys = x._1.split("_")
- val date = keys(0)
- val helperversion = keys(1)
- (date, helperversion, x._2, x._3)
- })
- resultedStream.print()
- env.execute("PvUvCount")
- }
- }
使用List集合的size保存pv,使用Set集合的size保存uv,從而達到實時統計pv,uv的目的。
這里用了幾個關鍵的函數:
applyWith:里面需要的參數,初始狀態變量,和foldFunction ,windowFunction ;
存在的問題
顯然,當數據量很大的時候,這個List集合和Set集合會很大,并且這里的pv是否可以不用List來存儲,而是通過一個狀態變量,不斷做累加,對應操作就是更新狀態來完成。
改進版
使用了一個計數器來存儲pv的值。
- packagecom.ddxygq.bigdata.flink.streaming.pvuv
- import java.util.Properties
- import com.alibaba.fastjson.JSON
- import org.apache.flink.api.common.accumulators.IntCounter
- import org.apache.flink.runtime.state.filesystem.FsStateBackend
- import org.apache.flink.streaming.api.CheckpointingMode
- import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
- import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
- import org.apache.flink.streaming.api.windowing.time.Time
- import org.apache.flink.streaming.api.windowing.triggers.ContinuousProcessingTimeTrigger
- import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010
- import org.apache.flink.streaming.util.serialization.SimpleStringSchema
- import org.apache.flink.streaming.api.scala.extensions._
- import org.apache.flink.api.scala._
- import org.apache.flink.core.fs.FileSystem
- object PvUv2 {
- def main(args: Array[String]): Unit = {
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- // 容錯
- env.enableCheckpointing(5000)
- env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
- env.setStateBackend(new FsStateBackend("file:///D:/space/IJ/bigdata/src/main/scala/com/ddxygq/bigdata/flink/checkpoint/streaming/counter"))
- // kafka 配置
- val ZOOKEEPER_HOST = "hadoop01:2181,hadoop02:2181,hadoop03:2181"
- val KAFKA_BROKERS = "hadoop01:9092,hadoop02:9092,hadoop03:9092"
- val TRANSACTION_GROUP = "flink-count"
- val TOPIC_NAME = "flink"
- val kafkaProps = new Properties()
- kafkaProps.setProperty("zookeeper.connect", ZOOKEEPER_HOST)
- kafkaProps.setProperty("bootstrap.servers", KAFKA_BROKERS)
- kafkaProps.setProperty("group.id", TRANSACTION_GROUP)
- // watrmark 允許數據延遲時間
- val MaxOutOfOrderness = 86400 * 1000L
- val streamData: DataStream[(String, String, String)] = env.addSource(
- new FlinkKafkaConsumer010[String](TOPIC_NAME, new SimpleStringSchema(), kafkaProps)
- ).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[String](Time.milliseconds(MaxOutOfOrderness)) {
- override def extractTimestamp(element: String): Long = {
- val t = JSON.parseObject(element)
- val time = JSON.parseObject(JSON.parseObject(t.getString("message")).getString("decrypted_data")).getString("time")
- time.toLong
- }
- }).map(x => {
- var date = "error"
- var guid = "error"
- var helperversion = "error"
- try {
- val messageJsonObject = JSON.parseObject(JSON.parseObject(x).getString("message"))
- val datetime = messageJsonObject.getString("time")
- date = datetime.split(" ")(0)
- // hour = datetime.split(" ")(1).substring(0, 2)
- val decrypted_data_string = messageJsonObject.getString("decrypted_data")
- if (!"".equals(decrypted_data_string)) {
- val decrypted_data = JSON.parseObject(decrypted_data_string)
- guid = decrypted_data.getString("guid").trim
- helperversion = decrypted_data.getString("helperversion")
- }
- } catch {
- case e: Exception => {
- println(e)
- }
- }
- (date, helperversion, guid)
- })
- val resultStream = streamData.keyBy(x => {
- x._1 + x._2
- }).timeWindow(Time.days(1))
- .trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(1)))
- .applyWith(("", new IntCounter(), Set.empty[Int], 0L, 0L))(
- foldFunction = {
- case ((_, cou, set, _, 0), item) => {
- val date = item._1
- val helperversion = item._2
- val guid = item._3
- cou.add(1)
- (date + "_" + helperversion, cou, set + guid.hashCode, 0L, 0L)
- }
- }
- , windowFunction = {
- case (key, window, result) => {
- result.map {
- case (leixing, cou, set, _, _) => {
- (leixing, cou.getLocalValue, set.size, window.getStart, window.getEnd)
- }
- }
- }
- }
- ).keyBy(0)
- .flatMapWithState[(String, Int, Int, Long, Long),(Int, Int)]{
- case ((key, numpv, numuv, begin, end), curr) =>
- curr match {
- case Some(numCurr) if numCurr == (numuv, numpv) =>
- (Seq.empty, Some((numuv, numpv))) //如果之前已經有相同的數據,則返回空結果
- case _ =>
- (Seq((key, numpv, numuv, begin, end)), Some((numuv, numpv)))
- }
- }
- // 最終結果
- val resultedStream = resultStream.map(x => {
- val keys = x._1.split("_")
- val date = keys(0)
- val helperversion = keys(1)
- (date, helperversion, x._2, x._3)
- })
- val resultPath = "D:\\space\\IJ\\bigdata\\src\\main\\scala\\com\\ddxygq\\bigdata\\flink\\streaming\\pvuv\\result"
- resultedStream.writeAsText(resultPath, FileSystem.WriteMode.OVERWRITE)
- env.execute("PvUvCount")
- }
- }
改進
其實這里還是需要set保存uv,難免對內存有壓力,如果我們的集群不大,為了節省開支,我們可以使用外部媒介,如hbase的rowkey唯一性、redis的set數據結構,都是可以達到實時、快速去重的目的。
參考資料
https://flink.sojb.cn/dev/event_time.htm
lhttp://wuchong.me/blog/2016/05/20/flink-internals-streams-and-operations-on-streams
https://segmentfault.com/a/1190000006235690