用好OnionScan,自己動手制作暗網爬蟲

喜大普奔!OnionScan0.2終于發布啦!在新版OnionScan中,最引人注目的一個新功能就是“custom crawls”(自定義爬取)。我們將會通過這篇文章來教會大家如何去使用這個強大的功能。【 OnionScan 0.2下載地址 】

可能對暗網比較了解的同學都知道OnionScan是個什么東西吧?OnionScan是一款非常棒的工具,你可以用它來掃描暗網中的隱藏服務,并收集一些潛在的泄漏數據。除此之外,OnionScan也可以幫助你搜索出各種匿名服務的標識,例如比特幣錢包地址、PGP密鑰、以及電子郵件地址等等。
但是,暗網中的很多服務數據都是以非標準的數據格式發布的,不同的服務很可能使用的是不同的數據格式,這也就使得我們很難用軟件工具來對這些數據進行自動化處理。
不過別擔心,OnionScan可以幫助我們解決這個難題。OnionScan允許我們自定義各個網站之間的關系,然后我們可以將這些關系導入至OnionScan的關聯引擎(Correlation Engine)之中。接下來,系統會像處理其他標識符那樣來幫助我們對這些關系進行關聯和分類。
接下來,我們以暗網市場Hansa來作為講解實例。當我們在收集該市場中的數據時,我們首先要收集的往往是市場中處于在售狀態的商品名稱和商品類別,有時我們可能還需要收集這些商品的供應商信息。實際上,我們可以直接訪問產品的/listing頁面來獲取所有的這些信息。
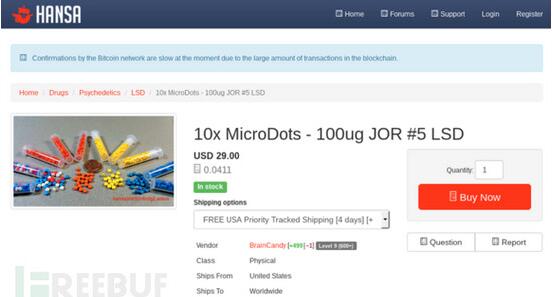
但是,我們現在要自己動手制作一個暗網爬蟲。我們將使用這個爬蟲來爬取并導出我們所需的數據,然后再對這些數據進行處理,***再將其轉換成我們可以進行自動化分析的數據格式。在OnionScan0.2的幫助下,我們只需要定義一個簡單的配置文件就可以輕松實現這些操作了。相關代碼如下所示:
- {
- "onion":"hansamkt2rr6nfg3.onion",
- "base":"/",
- "exclude":["/forums","/support","/login","/register","?showFilters=true","/img","/inc", "/css", "/link", "/dashboard","/feedback", "/terms", "/message"],
- "relationships":[{"name":"Listing",
- "triggeridentifierregex":"/listing/([0-9]*)/",
- "extrarelationships":[
- {
- "name":"Title",
- "type":"listing-title",
- "regex":"
- (.*)
- " }, { "name":"Vendor", "type":"username", "regex":" " }, { "name":"Price", "type":"price", "regex":" (USD[^<]*) " }, { "name":"Category", "type":"category", "regex":"
- ([^<]*)
- ", "rollup": true } ] } ] }
上面這段代碼可能看起來非常的復雜,不過別擔心,接下來我們會給大家一一進行講解。
代碼開頭的“onion”參數定義的是我們所要掃描的暗網服務(”onion”:”hansamkt2rr6nfg3.onion”)。“base”參數定義的是我們要從網站的哪個路徑開始執行掃描,在這里我們準備從網站的根目錄開始掃描(”base”:”/”)。與普通網站一樣,大多數暗網服務同樣只在網站子目錄中才會保存有效數據,例如剛才的“listing”目錄。在這種情況下,我們就可以使用“base”參數來告訴OnionScan從網站的哪一部分開始執行掃描,這樣可以為我們節省大量的時間。
“exclude”參數可以讓OnionScan排除某些類型的掃描對象,例如“/forums”、“/support”、“/login”、以及“/register”。通常情況下,這些鏈接我們***不要去碰,因為它們有可能會進行某些我們不希望發生的行為。
接下來就是“relationships”參數了,這個參數中定義的邏輯才是這個爬蟲最核心的部分。
我們的邏輯關系主要是由“name”和“triggeridentifierregex”這兩個參數定義的。其中的正則表達式主要應用于目標網站的URL地址,當正則表達式匹配到關系中的剩余規則時,就會觸發相應的操作。在這個例子中,我們在OnionScan中定義了正則表達式“/listing/([0-9]*)/”,它將會觸發URL地址中的Listing關系。需要注意的是,OnionScan還會根據URL地址中的“([0-9]*)”來識別資源之間的關系。
每一個關系都有一個“extrarelationships”參數,這個參數中定義的關系是OnionScan在進行搜索操作時需要用到的。
比如說,在我們的配置文件中,我們定義了四個額外的關系,即“Title”、“Vendor”、 “Price”和“Category”。每一個額外定義的關系都需要定義“name”和“type”參數,OnionScan的關聯引擎將需要使用到這部分數據。除此之外,我們還要在關系中定義一個正則表達式,即“regex”參數,我們可以通過這個正則表達式來提取目標頁面中的數據關系。
在Hansa市場這個例子中可以看到,我們可以通過正則表達式“”來從產品的/listing頁面中提取出廠商信息。類似地,我們也可以通過這種方法提取出產品的標題、價格、以及分類目錄。
“rollup”參數是OnionScan中的一個指令,這個指令可以讓OnionScan對我們所搜索到的產品分類數量進行數據統計,并以可視化的形式輸出統計結果。
現在,我們已經通過配置文件來告訴OnionScan應該從Hansa市場中提取哪些數據了,但是OnionScan應該如何使用這個配置文件呢?
接下來,先將我們剛才定義好的配置文件放到“service-configs”文件夾中,然后通過下列命令來讓OnionScan對市場執行掃描操作:
- ./onionscan -scans web --depth 1 --crawlconfigdir./service-configs/ --webport 8080 --verbose hansamkt2rr6nfg3.onion
搜索結果如下圖所示:
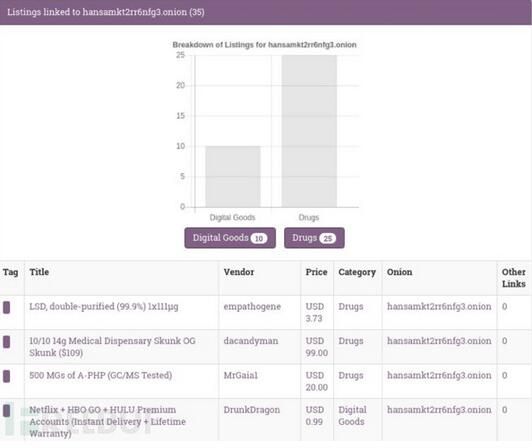
從上面這張圖片中可以看到,我們只需要定義一個簡單的配置文件,OnionScan就可以幫我們完成剩下的操作。我們之所以可以獲取到這張統計表格,是因為我們之前將“rollup”參數設為了“true”,所以OnionScan才會給我們提供這樣一份可視化的統計數據。