彪悍開源的分析數(shù)據(jù)庫-ClickHouse
今天介紹一個(gè)來自俄羅斯的兇猛彪悍的分析數(shù)據(jù)庫:ClickHouse,它是今年6月開源,俄語社區(qū)為主,好酒不怕巷子深。
本文內(nèi)容較長(zhǎng),分為三個(gè)部分:走馬觀花,死而后生,遙指杏花村;第一章,走馬觀花,初步了解一下基本特性;第二章,死而后生,介紹ClickHouse的技術(shù)架構(gòu)演化的今生前世;第三章,遙指杏花村,介紹一些參考資料,包括一些俄文資料。
第一章,走馬觀花
俄羅斯的‘百度’叫做Yandex,覆蓋了俄語搜索超過68%的市場(chǎng),有俄語的地方就有Yandex;有中文的地方,就有百度么?好像不一定 :) 。
Yandex在2016年6月15日開源了一個(gè)數(shù)據(jù)分析的數(shù)據(jù)庫,名字叫做ClickHouse,這對(duì)保守俄羅斯人來說是個(gè)特大事。更讓人驚訝的是,這個(gè)列式存儲(chǔ)數(shù)據(jù)庫的跑分要超過很多流行的商業(yè)MPP數(shù)據(jù)庫軟件,例如Vertica。如果你沒有聽過Vertica,那你一定聽過 Michael Stonebraker,2014年圖靈獎(jiǎng)的獲得者,PostgreSQL和Ingres發(fā)明者(Sybase和SQL Server都是繼承 Ingres而來的), Paradigm4和SciDB的創(chuàng)辦者。Michael Stonebraker于2005年創(chuàng)辦Vertica公司,后來該公司被HP收購(gòu),HP Vertica成為MPP列式存儲(chǔ)商業(yè)數(shù)據(jù)庫的高性能代表,F(xiàn)acebook就購(gòu)買了Vertica數(shù)據(jù)用于用戶行為分析。
簡(jiǎn)單的說,ClickHouse作為分析型數(shù)據(jù)庫,有三大特點(diǎn):一是跑分快, 二是功能多 ,三是文藝范
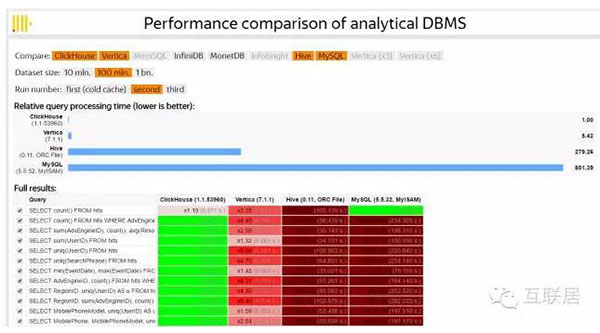
1. 跑分快: ClickHouse跑分是Vertica的5倍快:
ClickHouse性能超過了市面上大部分的列式存儲(chǔ)數(shù)據(jù)庫,相比傳統(tǒng)的數(shù)據(jù)ClickHouse要快100-1000X,ClickHouse還是有非常大的優(yōu)勢(shì):
- 100Million 數(shù)據(jù)集:
ClickHouse比Vertica約快5倍,比Hive快279倍,比My SQL快801倍
- 1Billion 數(shù)據(jù)集:
ClickHouse比Vertica約快5倍,MySQL和Hive已經(jīng)無法完成任務(wù)了
2. 功能多:ClickHouse支持?jǐn)?shù)據(jù)統(tǒng)計(jì)分析各種場(chǎng)景
- 支持類SQL查詢,
- 支持繁多庫函數(shù)(例如IP轉(zhuǎn)化,URL分析等,預(yù)估計(jì)算/HyperLoglog等)
- 支持?jǐn)?shù)組(Array)和嵌套數(shù)據(jù)結(jié)構(gòu)(Nested Data Structure)
- 支持?jǐn)?shù)據(jù)庫異地復(fù)制部署
3.文藝范:目前ClickHouse的限制很多,生來就是為小資服務(wù)的
- 目前只支持Ubuntu系統(tǒng)
- 不提供設(shè)計(jì)和架構(gòu)文檔,設(shè)計(jì)很神秘的樣子,只有開源的C++源碼
- 不理睬Hadoop生態(tài),走自己的路
誰在用ClickHouse?
- 由于項(xiàng)目今年6月才開源,因此外部商業(yè)應(yīng)用并不多件,但是開發(fā)社區(qū)的討論還是保持熱度(主要用俄語)
- Yandex有十幾個(gè)項(xiàng)目在用使用ClickHouse,它們包括:Yandex數(shù)據(jù)分析,電子郵件,廣告數(shù)據(jù)分析,用戶行為分析等等
- 2012年,歐洲核子研究中心使用ClickHouse保存粒子對(duì)撞機(jī)產(chǎn)生的大量實(shí)驗(yàn)數(shù)據(jù),每年的數(shù)據(jù)存儲(chǔ)量都是PB級(jí)別,并支持統(tǒng)計(jì)分析查詢
ClickHouse最大應(yīng)用:
最大的應(yīng)用來自于Yandex的統(tǒng)計(jì)分析服務(wù)Yandex.Metrica,類似于谷歌Analytics(GA),或友盟統(tǒng)計(jì),小米統(tǒng)計(jì),幫助網(wǎng)站或移動(dòng)應(yīng)用進(jìn)行數(shù)據(jù)分析和精細(xì)化運(yùn)營(yíng)工具,據(jù)稱Yandex.Metrica為世界上第二大的網(wǎng)站分析平臺(tái)。ClickHouse在這個(gè)應(yīng)用中,部署了近四百臺(tái)機(jī)器,每天支持200億的事件和歷史總記錄超過13萬億條記錄,這些記錄都存有原始數(shù)據(jù)(非聚合數(shù)據(jù)),隨時(shí)可以使用SQL查詢和分析,生成用戶報(bào)告。
ClickHouse就是快:比Veritca快約5倍
下面是100M數(shù)據(jù)集的跑分結(jié)果:ClickHouse 比Vertia快約5倍,比Hive快279倍,比My SQL 快801倍;雖然對(duì)不同的SQL查詢,結(jié)果不完全一樣,但是基本趨勢(shì)是一致的。ClickHouse跑分有多塊? 舉個(gè)例子:ClickHouse 1秒,Vertica 5.42秒,Hive 279秒;
ClickHouse是什么,適合什么場(chǎng)景?
到底什么是ClickHouse數(shù)據(jù)庫,場(chǎng)景應(yīng)用是什么,參考下面說明:

ClickHouse的不完美:
- 不支持Transaction:想快就別想Transaction
- 聚合結(jié)果必須小于一臺(tái)機(jī)器的內(nèi)存大小:不是大問題
- 缺少完整的Update/Delete操作
- 支持有限操作系統(tǒng)
- 開源社區(qū)剛剛啟動(dòng),主要是俄語為主
ClickHouse和一些技術(shù)的比較
1.商業(yè)OLAP數(shù)據(jù)庫
例如:HP Vertica, Actian the Vector,
區(qū)別:ClickHouse是開源而且免費(fèi)的
2.云解決方案
例如:亞馬遜RedShift和谷歌的BigQuery
區(qū)別:ClickHouse可以使用自己機(jī)器部署,無需為云付費(fèi)
3.Hadoop生態(tài)軟件
例如:Cloudera Impala, Spark SQL, Facebook Presto , Apache Drill
區(qū)別:
-ClickHouse支持實(shí)時(shí)的高并發(fā)系統(tǒng)
-ClckHouse不依賴于Hadoop生態(tài)軟件和基礎(chǔ)
-ClickHouse支持分布式機(jī)房的部署
4.開源OLAP數(shù)據(jù)庫
例如:InfiniDB, MonetDB, LucidDB
區(qū)別:這些項(xiàng)目的應(yīng)用的規(guī)模較小,并沒有應(yīng)用在大型的互聯(lián)網(wǎng)服務(wù)當(dāng)中,相比之下,ClickHouse的成熟度和穩(wěn)定性遠(yuǎn)遠(yuǎn)超過這些軟件。
5.開源分析,非關(guān)系型數(shù)據(jù)庫
例如:Druid , Apache Kylin
區(qū)別:ClickHouse可以支持從原始數(shù)據(jù)的直接查詢,ClickHouse支持類SQL語言,提供了傳統(tǒng)關(guān)系型數(shù)據(jù)的便利。
第二章,死而后生
ClickHouse設(shè)計(jì)之初就是為Yandex.Metrika而生,先一起看看Yandex.Metrika數(shù)據(jù)分析系統(tǒng)的演化過程吧,ClickHouse是第四代的解決方案,經(jīng)過三次死亡后的產(chǎn)物,涅槃重生的巨獸!
第一階段:MyISAM (LSM-Tree) (2008-2011)
Yandex.Metrika產(chǎn)品成立于2008年,最開始使用了MyISAM作為存儲(chǔ)引擎。熟悉MySQL的同學(xué)都知道,這是MySQL的重要存儲(chǔ)引擎之一(另外一個(gè)是InnoDB)。MyISAM中的實(shí)現(xiàn)也是使用LSM-Tree的設(shè)計(jì),基本思路就是將對(duì)數(shù)據(jù)的更改hold在內(nèi)存中,達(dá)到指定的threadhold后將該批更改批量寫入到磁盤,在批量寫入的過程中跟已經(jīng)存在的數(shù)據(jù)做rolling merge。
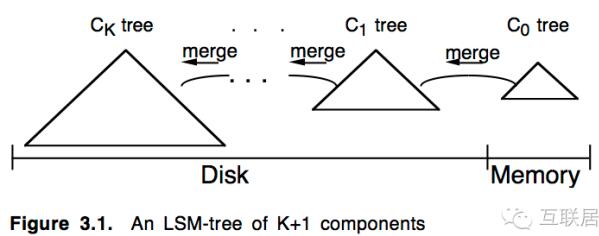
使用MyISAM的方法,剛開始數(shù)據(jù)量不大,訪問請(qǐng)求也不大的時(shí)候,這個(gè)方法非常有效,特別是對(duì)于一些固定的報(bào)告生成,效率非常高,系統(tǒng)能夠保持很好的系統(tǒng)寫能力。
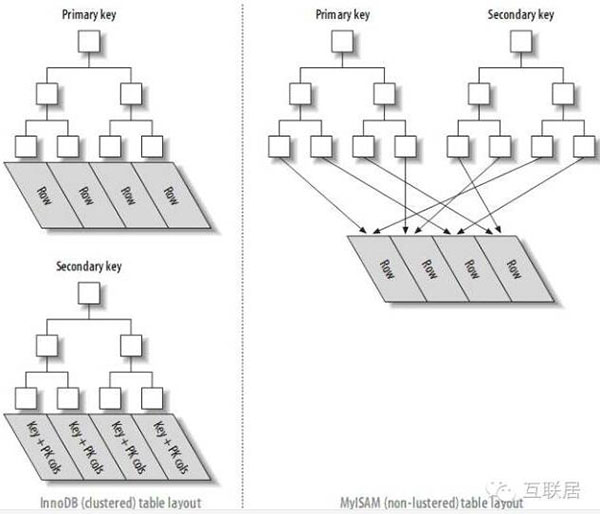
數(shù)據(jù)格式也是傳統(tǒng)的索引結(jié)構(gòu):一個(gè)數(shù)據(jù)文件+一個(gè)索引結(jié)構(gòu); 索引結(jié)構(gòu)是一個(gè)B-Tree結(jié)構(gòu),葉子節(jié)點(diǎn)保持著數(shù)據(jù)文件的OffSet; 通過Index文件找到數(shù)據(jù)范圍,然后進(jìn)行數(shù)據(jù)文件讀取;早期的實(shí)現(xiàn)是將Index文件裝在內(nèi)存中,數(shù)據(jù)文件在磁盤當(dāng)中,或則SSD等。當(dāng)時(shí)7200RPM的硬盤,每秒進(jìn)行100-200次隨機(jī)讀;SSD硬盤可以支持30000次隨機(jī)讀/每秒。
除了考察MyISAM之外,InnoDB也被考察過。MyISAM的索引和數(shù)據(jù)是分開的,并且索引是有壓縮的,這種方式可以提高內(nèi)存的使用率。加載更多索引到內(nèi)存中,而Innodb是索引和數(shù)據(jù)是緊密捆綁的,沒有使用壓縮的情況下,InnoDb的大小會(huì)比MyISAM體積大很多。當(dāng)然,InnoDB支持的Transaction也是非常誘人的。
階段二: Metrage (從2010-現(xiàn)在)
為了解決MyISAM的一些問題,Yandex決定開發(fā)Metrage,核心想法來源于統(tǒng)計(jì)分析數(shù)據(jù)的一些特點(diǎn),統(tǒng)計(jì)分析數(shù)據(jù)的每行數(shù)據(jù)量都不大,因此可以將多行數(shù)據(jù)聚合在一起作為處理單位,加快操作速度和系統(tǒng)的吞吐能力。
它有幾個(gè)特點(diǎn):
- 數(shù)據(jù)通過小批量Batch存儲(chǔ)
- 支持高強(qiáng)度的寫操作(數(shù)千行寫入/每秒)
- 讀數(shù)據(jù)量非常小
- 讀數(shù)據(jù)操作中Primary Key 的數(shù)量有限(<1百萬)
- 每一行的數(shù)據(jù)量很小
整個(gè)結(jié)構(gòu)類似于MyISAM的索引,但是數(shù)據(jù)塊中也聚合了一些小粒度的數(shù)據(jù),索引放在內(nèi)存中,數(shù)據(jù)被整理成塊放在磁盤中,并且進(jìn)行壓縮。
該數(shù)據(jù)結(jié)構(gòu)的優(yōu)點(diǎn):
- 數(shù)據(jù)被壓縮成塊。 由于存儲(chǔ)有序,壓縮足夠強(qiáng)大,其中使用了快速壓縮算法(在2010年使用QuickLZ ,自2011年使用LZ4 )。
- 采用稀疏索引: 稀疏索引 - 主鍵值排序后放置于若干個(gè)組中,可以節(jié)省大量索引空間。 這個(gè)索引始終放在內(nèi)存中。
Metrage在數(shù)據(jù)量最大的時(shí)候,39*2臺(tái)服務(wù)器中存儲(chǔ)了大約3萬億行數(shù)據(jù),每天機(jī)器處理大約為1千億的數(shù)據(jù)。
這個(gè)系統(tǒng)有個(gè)缺點(diǎn),數(shù)據(jù)查詢只能進(jìn)行基于固定的查詢模式(否則性能將受到很大影響),因此在設(shè)計(jì)數(shù)據(jù)Schema的時(shí)候,需要考慮數(shù)據(jù)查詢的性能問題,缺少足夠的靈活型。因此這個(gè)項(xiàng)目使用了5年后,統(tǒng)計(jì)分析的數(shù)據(jù)都開始遷移到其他的平臺(tái)系統(tǒng)中了(那時(shí)候LevelDB,還沒有出現(xiàn),否則可以使用LevelDB作為Mertage的核心模塊)。
階段三 OLAPServer (2009-2013)
隨著Yandex.Metrike的數(shù)據(jù)量越來越大,數(shù)據(jù)查詢的速度越來越慢,查詢相應(yīng)事件長(zhǎng),系統(tǒng)的CPU和IO資源占用大,因此公司內(nèi)部嘗試了不同的解決方案,其中一個(gè)原型方案是OLAPServer。 設(shè)計(jì)思路就是根據(jù)“星型結(jié)構(gòu)”設(shè)計(jì)一些維度和事實(shí)列,通過預(yù)先部分聚合數(shù)據(jù)加快訪問的速度,這一套技術(shù)用于支持各種報(bào)告的生成。
基本的場(chǎng)景如下:
- 支持一個(gè)Fact表,包括維度列(Dimension)和指標(biāo)列(Metrics),維度有上百個(gè)
- 讀取大量行的數(shù)據(jù),但是一次查詢往往只關(guān)注某些列
- 寫多讀少的場(chǎng)景,報(bào)表查詢請(qǐng)求量并不大
- 大部分簡(jiǎn)單查詢不超過50毫秒響應(yīng)時(shí)間
- 列的值數(shù)據(jù)量非常小,通常為整數(shù)或者不超過60字節(jié)的URL
- 它需要高帶寬,同時(shí)處理單個(gè)請(qǐng)求(高達(dá)十億每秒的行的單個(gè)服務(wù)器上)
- 查詢結(jié)果的數(shù)據(jù)量非常小,通常是數(shù)據(jù)聚合的結(jié)果
- 無需支持事務(wù),數(shù)據(jù)更新極少,通知只有添加操作
這些場(chǎng)景下,使用列式數(shù)據(jù)庫是非常有效的,從兩個(gè)方面可以理解
1. 磁盤I/O的優(yōu)化
- 作為列式存儲(chǔ),查詢只需要訪問所關(guān)心的列數(shù)據(jù)
- 列數(shù)據(jù)放在一起,數(shù)據(jù)格式類似,非常容易壓縮,因此減少I/O數(shù)據(jù)量
- 輸入輸出的減少,內(nèi)存可以騰出更多地方作為Cache
2. CPU
由于數(shù)量行數(shù)特別大,數(shù)據(jù)的解壓縮和計(jì)算將耗費(fèi)非常多的CPU資源,為了提高CPU的效率,行業(yè)中通常是將數(shù)據(jù)轉(zhuǎn)換成Vector的計(jì)算。例如行業(yè)比較流行的VectorWise方法。
下面是VectorWise的高層架構(gòu)示意圖,其基本想法就是將壓縮的列數(shù)據(jù)整理成現(xiàn)代CPU容易處理的Vector模式,利用現(xiàn)代CPU的多線程,SIMD(Single Instruction,Multiple Data),每次處理都是一批Vector數(shù)據(jù),極大的提高了處理效率。

市場(chǎng)有非常多的的列式分析型數(shù)據(jù)庫,例如HP Vertica, ParAccel Actian the Matrix, Google PowerDrill , Amazon的RedShift , MetaMarkets Druid等等,這些產(chǎn)品有很多不同的優(yōu)化實(shí)踐,有些是專于數(shù)據(jù)壓縮,有些是專于數(shù)據(jù)聚合,有些是專于擴(kuò)展性等。
OLAPServer在具體實(shí)現(xiàn)過程中,實(shí)際上采用的是比較保守的方法,實(shí)現(xiàn)的功能也比較有限,但是完全滿足當(dāng)時(shí)分析報(bào)表的支持。例如,OLAPServer數(shù)據(jù)類型只支持1-8字節(jié)的數(shù)據(jù)類型,查詢只支持固定的模式:
Select keys ,aggregate(columns) from table where condition1 and condition2 .... Group by keys order by columns 。
盡管功能有限,OLAPServer還是滿足了當(dāng)時(shí)的分析報(bào)表功能,并且性能非常出色。由于設(shè)計(jì)之處的限制比較多,因此后期的改進(jìn)過程中成本非常高,例如為了增加更長(zhǎng)URL的數(shù)據(jù)類型,系統(tǒng)改動(dòng)非常大。在2013年,OLAPServer存儲(chǔ)了7280億行數(shù)據(jù),目前這些數(shù)據(jù)都遷移到ClickHouse了。
第四階段 ClickHouse(2011-現(xiàn)在)
使用OLAPServer,我們能夠可以實(shí)時(shí)看到一些預(yù)先聚合的數(shù)據(jù),但是對(duì)于一些聚合前的詳細(xì)數(shù)據(jù)是無法查詢的,隨著業(yè)務(wù)的深入發(fā)展,精細(xì)化運(yùn)營(yíng)對(duì)于統(tǒng)計(jì)服務(wù)提出了更高的要求,后期有大量需求是關(guān)于直接查詢聚合前的數(shù)據(jù)。
總體來說,雖然數(shù)據(jù)聚合帶來一些好處,但是也存在以下一些問題。
- 對(duì)于基數(shù)大的列,聚合的意義不大,例如URL等
- 過多的維度組合會(huì)導(dǎo)致組合爆炸
- 用戶常常只關(guān)心聚合后的數(shù)據(jù)中的非常一一小部分?jǐn)?shù)據(jù),因此大量聚合預(yù)計(jì)算是得不償失的。
- 聚合后的數(shù)據(jù),數(shù)據(jù)修改會(huì)非常困難,很難保證存儲(chǔ)的邏輯完整性
如果不預(yù)先聚合數(shù)據(jù),如何保證響應(yīng)時(shí)間是一個(gè)大挑戰(zhàn)。這意味著,數(shù)據(jù)庫需要支持秒級(jí)處理數(shù)十億的行。
近年來,市面上也出現(xiàn)很多列式存儲(chǔ)的開源DBMS,包括Cloudera Impala, Spark SQL, Presto, Apache Drill,這些系統(tǒng)雖然都能完成查詢的功能,但是速度卻無法滿足數(shù)據(jù)統(tǒng)計(jì)分析的需求,即使聚合后的性能能夠滿足,但也缺少靈活度。
因此,Yandex開發(fā)了自己的列式分析數(shù)據(jù)庫 ClickHouse,初期主要是滿足Yandex.Metrike的統(tǒng)計(jì)分析需求,主角要上場(chǎng)了。
ClickHouse實(shí)際上來源于內(nèi)部的幾個(gè)項(xiàng)目的整合,項(xiàng)目起源起源于2011年左,
到2013年的時(shí)候,ClickHouse的性能就和Vertica大致相同;2015年12月,ClickHouse的數(shù)量已經(jīng)達(dá)到11萬億行,數(shù)據(jù)表有200多列,主集群的服務(wù)器數(shù)量也從初期的60臺(tái)到394臺(tái);
整個(gè)系統(tǒng)的部署是支持水平擴(kuò)展的,并且支持多機(jī)房部署和備份。雖然它是能夠在大型集群操作,它可以被安裝在同一服務(wù)器上,甚至在虛擬機(jī)上。
在最新的性能評(píng)測(cè)中,ClickHouse比Vertica快約5倍。現(xiàn)在Yandex公司內(nèi)部有十幾個(gè)應(yīng)用系統(tǒng)在使用ClickHouse,場(chǎng)景包括數(shù)據(jù)存儲(chǔ),查詢分析,報(bào)表制作等。
ClickHouse的藍(lán)圖
關(guān)于ClickHouse的下一步發(fā)展,公司并沒有給出太多規(guī)劃,因?yàn)槎鄶?shù)信息還是屬于不公開狀態(tài),但是從一些公開的信息,我們可以了解到,ClickHouse會(huì)向兩個(gè)方向發(fā)展。
1 云計(jì)算數(shù)據(jù)庫:
Yandex希望通過ClickHouse促進(jìn)公司云計(jì)算數(shù)據(jù)庫的發(fā)展,包括用戶可以通過云服務(wù)的方式,使用ClickHouse,開源是走向市場(chǎng)的第一步。
2. 加強(qiáng)SQL兼容性。
為了支持更多的企業(yè)用戶,目前的查詢雖然采用非常近似的SQL語言,但是還有很多地方需要改進(jìn),包括和一些商業(yè)軟件(例如Tableau,Pentaho)的集成無縫使用。
第三部分:遙指杏花村
這一部分包括了一些ClickHouse的一些基本信息,幫助大家進(jìn)入ClickHouse的世界。為了深度了解ClickHouse社區(qū),不僅僅需要翻墻,也需要谷歌或者必應(yīng)的翻譯器,俄文翻譯的效果不錯(cuò)。
1主頁: https://clickhouse.yandex
2.代碼: https://github.com/yandex/ClickHouse
3參考文章:
Yandex.Metrike的架構(gòu)演化:
https://habrahabr.ru/company/yandex/blog/273305/(俄文)很棒的文章
MPP數(shù)據(jù)庫基礎(chǔ)架構(gòu):
http://vldb.org/pvldb/vol5/p1790_andrewlamb_vldb2012.pdf
http://www.cs.yale.edu/homes/dna/talks/Column_Store_Tutorial_VLDB09.pdf
4關(guān)于Yandex的
Yandex的(納斯達(dá)克股票代碼:YNDX)是互聯(lián)網(wǎng)公司在俄羅斯主導(dǎo),經(jīng)營(yíng)該國(guó)最流行的搜索引擎和訪問量最大的網(wǎng)站。Yandex的還經(jīng)營(yíng)在烏克蘭,哈薩克斯坦,白俄羅斯和土耳其。Yandex的的使命是回答任何互聯(lián)網(wǎng)用戶的任何問題(Answer any question Internet users may have)。
最近在學(xué)習(xí)一些ClickHouse的源代碼,還沒有理清楚頭緒,下次搞清楚邏輯后再和大家介紹一下,這里先紙上談兵,點(diǎn)到為止了。
【本文為51CTO專欄作者“歐陽辰”的原創(chuàng)稿件,轉(zhuǎn)載請(qǐng)聯(lián)系作者本人獲取授權(quán)】