對抗黑產,騰訊云安全發動了AI大招

周斌給大家系統介紹了大數據、深度學習、人工智能等前沿技術在騰訊云安全中的應用。
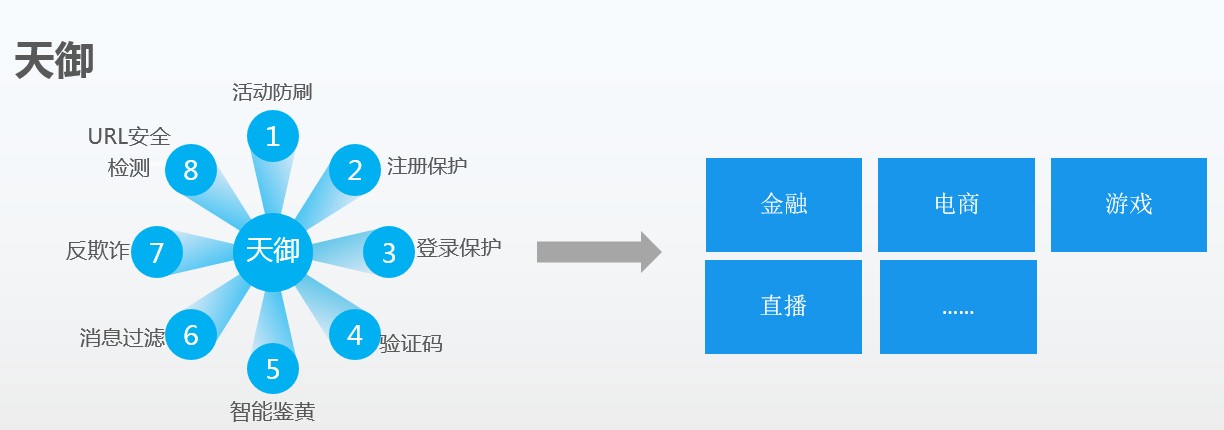
騰訊云的天御業務安全防護系統,正是騰訊云安全在AI實踐上的重要體現。基于騰訊內外部每天PB級數據量的安全大數據,天御的AI引擎能夠整合所有對抗經驗和數據能力,形成多個解決單一安全問題的服務。經過業務中的正向和反向的反饋,天御系統更能夠不斷優化。目前,天御已為開發者提供包括活動防刷、注冊保護、登錄保護、消息過濾、圖片鑒黃、驗證碼、反欺詐等服務,幫助京東、滴滴出行、58同城、斗魚TV等企業保障業務安全。
以下是周斌本次分享的部分節選:
從與黑產的斗爭中,騰訊的安全系統從最初的半自動化策略規則集,到基于大數據畫像的策略引擎,再到基于深度學習的智能對抗引擎,正一步步實現脫胎換骨的變化。這并非簡單的模式變化,它所帶來的將是對系統整體架構的全面變革。
數據+算法,騰訊云形成智能的安全引擎
安全系統的數據分析平臺,我們會分為4個層次進行,首先是接入層,將所有緯度的數據進行集中,包括從基礎網絡到業務特征,像網絡流量、行為、內容等多個緯度,這樣做的原因是所有分類和學習算法,必須要有基礎底層數據,越真實越好,這樣可以保證機器模型可以精確學習。
其次是引擎和數據層,通過底層的模型,對前期采到的數據進行分類、建模、修正,最后作為結果數據輸出到業務場景中。
那么,我們從頭來看,海量數據是AI的基礎。通過業務數據、風險數據、行業協同數據、以及公共數據,我們構建出構建用于風險識別的智能引擎,引擎區分出正常群體和風險群體。而單個個體通過智能引擎后,最終得出是否風險個體的結論。
算法和模型是深度學習的靈魂。機器學習中,不論是否是深層,最常見的形式是監督學習。監督訓練需要依賴于有標簽的數據才能進行訓練。然而有標簽的數據通常是稀缺的,因此對于許多問題,很難獲得足夠多的樣本來訓練一個復雜的模型。對于具有強大表達能力的深度網絡模型,在不充足的數據上進行訓練將會導致過擬合。過擬合簡單點說,是指在訓練集上可以獲得很好的效果,但是在其他數據集上效果就不好甚至非常差。
監督學習的另一個問題是局部最優問題。使用監督學習方法來對淺層網絡(只有一個隱藏層)進行訓練通常能夠使參數收斂到合理的范圍內。但是當用這種方法來訓練深度網絡的時候,并不能取得很好的效果。特別的,使用監督學習方法訓練神經網絡時,通常會涉及到優化問題。
鑒于監督學習存在的這些問題,兩千年中期,使用無監督學習的理念開始興起。無監督學習不依賴有標簽樣本,他可以幫助特定的深度網絡進行“預訓練”。但是這方面的研究還是在進行中。
回到安全上的深度學習模型訓練上,有監督學習能否解決問題?我們的回答是:能!
首先,騰訊經過18年的黑產對抗積累,已積累了大規模的標注數據,平臺每天處理超過35萬億條實時計算、超過300億的IM消息、20億的UGC圖片、沉淀下超過400PB存儲數據!我們有豐富的惡意語料庫、惡意圖片庫可以用來進行模型訓練。但是黑產是在不斷演進的,新的惡意形態出現該怎么辦?我們采取了兩個思路:
第一是在算法上,我們引入多目標優化算法,可以解決樣本不足時的過擬合問題;
第二是在半監督深度學習上的嘗試,不同于人工全量標注樣本,我們只標記關鍵點樣本,再由這些關鍵點樣本進行擴展,最后再拿得到的樣本進行訓練。
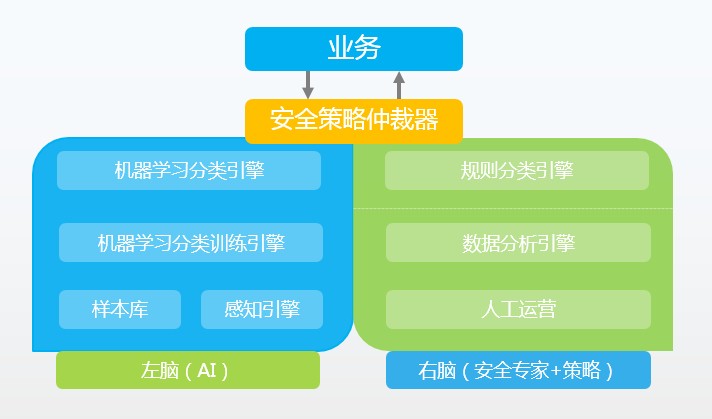
數據+算法,我們形成了智能的安全引擎。左腦進行計算和學習,右腦用專家規則來調整方向。
實際應用中的例子——基于實時挖掘的身份鑒定
眾所周知,互聯網安全產品中,識別是否真人是否本人是一個關鍵的基礎的問題。很多年前就有這樣的一個笑話,你不知道跟你聊天的是只貓還是一只狗。現在我們還得問,你知道跟你聊天的是人還是機器?是人的話是他本人嗎?是不是人?這是識別自然人的范疇。是他本人嗎?是否有帳號盜用或者共用的可能?在活動防刷、金融反欺詐等領域,身份鑒定都是一個繞不開的問題。來看下我們是怎么做的?首先,我們基于大數據,使用多標簽精準刻畫建立用戶畫像。
用戶畫像涉及的維度有風險畫像,包含用戶的惡意指數、活躍指數、負反饋指數等。行為序列,用于刻畫用戶在產品中的行為軌跡。帳號畫像,包含用戶的社交傾向,比如是否熱衷原創、是否樂于分享、是否樂于互動等,帳號畫像還有一個重要的維度是行為軌跡,包含用戶使用產品的區域傾向和時間段傾向。IP畫像,主要包含IP屬性和安全標簽,我們會記錄該IP是否肉雞IP、作弊IP等,另外還有針對設備的畫像等等。
接下來看下我們使用的算法,我們使用的是基于多目標優化的深度學習算法。為什么使用多目標優化?前面我們提到有監督深度學習的兩個問題:過擬合與局部最優。我們希望模型精度足夠高,同時過擬合情況足夠小,傳統的方法是將交叉熵(也就是誤差),和規范化 (這個是用來衡量是否過擬合的一個量化)進行加權,組成一個最終的目標來訓練模型。 多目標優化是同時將誤差和規范化作為目標,也就是模型要求同時達到最優。
這樣可以全面覆蓋搜索空間,最終實現跳出局部最優,避免過擬合。這三張圖顯示了迭代的過程。橫坐標和豎坐標分別表示誤差和規范化,構成了搜索空間。通過個體間的信息交換機制,經過若干輪迭代,算法在搜索空間中越過了很多局部最優,得到了較好的結果。就可以根據需要選擇其中一個模型應用到生產環境中實施打擊。
整個實現過程,我們使用了2TB的畫像數據,涉及到380個細分維度,我們使用的底層分析平臺保證了身份鑒定整個自學習過程以實時的方式實現。安全策略的精準度至少能達到兩個9。
另外一個基于深度學習的應用是色情圖片識別,騰訊的色情圖片識別依托于騰訊優圖的DeepEye主動識別模型,應用在空間、QQ、天御直播鑒黃上,效果在業內處于領先優勢。
因為騰訊有著十余年黑產對抗經驗,有天然的海量大數據,也有著成功應用于的智能對抗方法,我們能很好地識別自然人和黑產用戶,很好地識別垃圾文本、惡意圖片,很好地發現更多的惡意模式,我們將這些成熟的業務安全能力開發出來,為互聯網金融、電商、游戲、直播提供業務安全解決方案,共享我們的黑產對抗成果。
這也是以SaaS化服務模式,將這些數據和能力整合,在騰訊云上向業界開放了反黑產利器——天御。一年來,天御已經幫助我們大量電商企業應對刷單、金融企業應對詐騙、直播客戶鑒黃上發揮了重要作用。今年的一些電商活動中,天御直接攔下了超過80%惡意刷單。