圖像技術在直播中的應用(下)——圖像識別
在《圖像技術在直播中的應用(上)》中,我們簡述了美顏技術1.0的原理與實踐問題。在文章的***,我們提到了美顏2.0最關鍵的技術——人臉識別。這是項復雜但又非常熱門的技術,我們將在這篇文章中聊一聊圖像識別,其原理與具體實踐的一些問題。該分享系列整理自涂圖CTO在架構師沙龍上的演講內容。
一、淺析機器學習與深度學習——如何讓機器看懂世界?
近段時間,機器學習、深度學習的概念非常火,尤其是今年 AlphaGo 擊敗了韓國棋手這件事,引起了世界的轟動。機器學習和深度學習這兩個概念,比較容易混淆,以至于很多媒體在寫報道時,經常把這兩個詞混著用。由于這兩個概念目前最主要應用在圖像領域上,所以我們僅就圖像識別,尤其是人臉識別方面,區分一下這兩個概念。
機器學習的概念提出的比較早,上世紀 90 年代初,人們開始意識到一種可以更有效地構建模式識別算法的方法,那就是用數據(可以通過廉價勞動力采集獲得)去替換專家(具有很多圖像方面知識的人)。而深度學習可以算是機器學習的一個分支,只在近十年內才得到廣泛的關注與發展。
下面說說具體的區別。
首先,機器學習識別物體是基于像素特征的。我們會搜集大量的圖像素材,再選擇一個算法,使用這個算法來解析數據、從中學習,然后對真實世界中的事件做出決策和預測。
而深度學習可以算是機器學習的一個分支,只在近十年內才得到廣泛的關注與發展。它與機器學習不同的,它模擬我們人類自己去識別人臉的思路。比如,神經學家發現了我們人類在認識一個東西、觀察一個東西的時候,邊緣檢測類的神經元先反應比較大,也就是說我們看物體的時候永遠都是先觀察到邊緣。就這樣,經過科學家大量的觀察與實驗,總結出人眼識別的核心模式是基于特殊層級的抓取,從一個簡單的層級到一個復雜的層級,這個層級的轉變是有一個抽象迭代的過程的。深度學習就模擬了我們人類去觀測物體這樣一種方式,首先拿到互聯網上海量的數據,拿到以后才有海量樣本,把海量樣本抓取過來做訓練,抓取到核心的特征,建立一個網絡,因為深度學習就是建立一個多層的神經網絡,肯定有很多層。有些簡單的算法可能只有四五層,但是有些復雜的,像剛才講的谷歌的,里面有一百多層。當然這其中有的層會去做一些數學計算,有的層會做圖像預算,一般隨著層級往下,特征會越來越抽象。
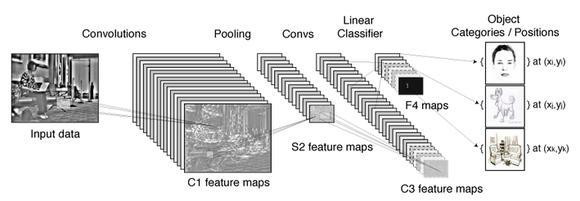
舉例來說,識別一張人臉。如果是在具體環境中的人臉,如果遇到云霧,或者被樹遮擋一部分,人臉就變得模糊,那基于像素的像素特征的機器學習就無法辨認了。它太僵化,太容易受環境條件的干擾。而深度學習則將所有元素都打碎,然后用神經元進行“檢查”:人臉的五官特征、人臉的典型尺寸等等。***,神經網絡會根據各種因素,以及各種元素的權重,給出一個經過深思熟慮的猜測,即這個圖像有多大可能是張人臉。
所以,深度學習比機器學習不管在人臉識別還是各種各樣的識別表現都要好,甚至已經超過人類的識別能力。比如 2015 年谷歌發布了一個 facenet 網絡,做人臉檢測的,號稱用這個網絡可以達到 98% 以上識別率。而我們人類自己去看樣本所達到的正確率,一樣不是***,甚至還沒有現在一些***進的采用深度學習算法的技術準確率高。
在機器學習方面,目前國際上比較主流的基于人臉檢測的計算,一是 HOG 算法,還有其他像 LBF 特征算法。 LBF 是 OpenCV 的,OpenCV 是個非常有名的開源庫,里面有各種各樣的圖象處理相關功能,而且是開源的,但是它在移動平臺上效果很差,沒有辦法達到我們要的效果。這里提到是因為它非常有名,里面包含了各種各樣圖象處理相關的功能,比如說做特殊處理,做人臉識別、物體識別等等。OpenCV 里面就包含了 LBF 算法的實現。
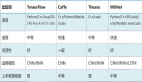
深度學習有不少開源框架,比如 Caffe、TensorFlow。這些框架提供的僅僅是構建深度學習網絡的工具,但是深度神經網絡才是最關鍵的東西。網絡怎么構建?網絡有多種構建方式,比如大家去關注這方面會發現經常看到一些名詞,CNN、RNN,CNN 可能是比較火的,在人臉識別方面是表現非常優越的一個網絡,現在也是比較主流的一個網絡。當然也有很多網絡,RNN 或者是更快的 CNN 網絡等等,在解決某些具體問題的時候,有更加好的表現。
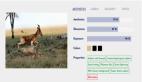
二、圖像識別的一些具體實現——以智能鑒黃為例
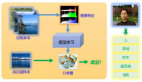
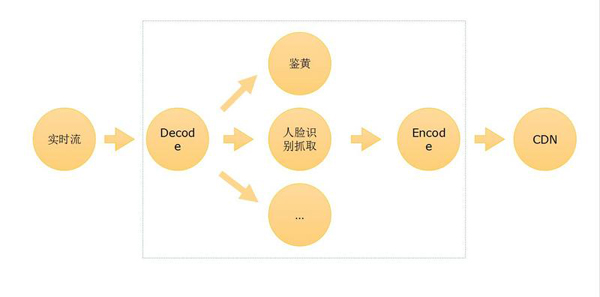
當們我們具備了相關的深度學習技術后,就可以在服務端上構建應用了。比如做智能鑒黃,一路視頻流輸入,解碼以后拿到每一幀,識別出有問題的部分,對它進行處理;比如打上馬賽克,或者把內容保存下來,然后發送通知給后臺,告訴后臺這里有一張疑似有不可描述的東西出現了等等,之后再編碼,輸出到其它地方,比如再分發到 CDN 等等。這些過程如果用人工識別成本非常高,要發展肯定要通過技術手段去解決。
***說下手機端上的經驗:涂圖的產品在人臉檢測性能方面的測試指標。比如 iOS 和安卓平臺上面我們做的測試,在 iPhone 6 上,40 特征點抓取需要 40 毫秒,相當于一秒內可以處理 25 幀。當然實際上并不需要這么多的次數,人眼觀察事物,因為有視覺暫留效應,一般來說 12 幀是個分界線,小于 12 幀就能感覺到畫面卡頓,但是只要大于 12 幀,看起來就是連續的。所以我們一般限制在十七八次的檢測,在 iOS 上夠用了。安卓方面,相對于 iOS 平臺的表現確實要差一些,不論是 API 的封裝,還是整個硬件的搭配,可能同樣一個 GPU 型號,用在安卓的設備上就沒法達到跟 iOS 同樣的表現,iOS 平臺確實在各方面上要做得比安卓好一點。小米5是比較新的設備了,40 特征點抓取需要大概 60毫秒。
三、技術的發展瓶頸——***還是拼硬件
雖然在手機端上,比如 iOS 9,已經推出了深度學習 API,iOS 10 又對其進行了升級,提供了更多的功能;但是一般來說我們是在 PC 上面開發、訓練的,直到把代碼都做好,再放在手機設備上運行。因為就像剛才提到的,機器學習、深度學習的開發中非常關鍵的環節是訓練。
訓練是什么意思?
比如我取 1 萬張圖片把人臉都標識出來,把 1 萬張樣本處理之后得到經驗,到底人臉有什么特征,比如涉及 150 個參數,得出一個函數,調整后得到一個函數模型,這樣的模型再去訓練、測試,***得到一個比較好的模型。接下來再找很多測試數據,比如 1 萬張測試數據,來檢測這個模型,如果表現很好,那這個數據模型網絡是可靠的,***用在實際中。
但是這個訓練的過程非常耗時間。我們運行一個訓練,CPU 可能需要二三十個小時。這還是簡單的模型,一些復雜的模型,比如谷歌開放的 125 層神經網絡,如果用 CPU 來跑可能要三四天,相當于這么久以后才能得到一個模型,你才知道這個模型是好是壞。如果你發現不行,又改了一個小參數,結果還要繼續三四天時間。所以解決的辦法只有一條,就是升級硬件。比如 GPU 取代 CPU 完成運算。
這里列了一個細的指標,比如有些算法需要在 RGB 空間里做檢測,有沒有不可描述的內容在里面。如果我們用 GTX 980 Ti 來運行,可以小于 20 毫秒一幀,用 i7 的 CPU 運行,檢測出來則是 800 秒,跟 GPU 跑完全不可比。但問題是,專門做訓練的 GPU 設備非常貴,七八千塊錢的 GPU 在機器訓練里面都不算好的,而且為了在復雜的場景中不耽誤時間,比如像 AlphaGo 做訓練一樣,只能用海量的設備來彌補,這個成本可想而知。所以才說只有有一定實力的公司才能擔負的起做深度學習。
現在國際上一些主流的大公司,比如微軟,很多服務包括云服務等等,用的是 FPGA 方案。百度也在做基于運算單元的芯片,中科院也在做相關的研究。所以深度學習一路發展下來,實際上一直都卡在計算上,計算能力遠遠跟不上我們軟件的要求,***就又變成了比拼硬件的時代。但其實這個問題并不是近期才有的;早在人工智能出現的早期,神經網絡的概念就已經存在了,但神經網絡對于“智能”的貢獻微乎其微,主要問題就出在運算能力不足上。所以現在大家可以預見,量子計算一旦成為可能,人工智能的時代才算真正要到來了。