使用 Teachable Machine 構建圖像識別模型
Teachable Machine 是由 Google 開發的一款基于網頁的工具,允許任何人在不需要深入了解編程或機器學習的情況下創建機器學習模型。它的設計易于使用且用戶友好,適合初學者、教育工作者,甚至是想要探索人工智能概念的孩子們。

Teachable Machine 支持的模型
Teachable Machine 支持以下機器學習模型:
- 圖像分類 — 識別圖像中的物體
- 音頻分類 — 識別聲音、語音或其他音頻輸入
- 姿態分類 — 識別人體姿態或動作
要訓練模型,您需要為 Teachable Machine 提供自己的數據集,例如圖像或錄音。基于這些數據,Teachable Machine 會自動訓練模型。
模型訓練完成后,您可以直接在 Teachable Machine 的網頁界面中進行測試。此外,您還可以選擇下載訓練好的模型,并將其集成到自己的應用程序中以供編程使用。訓練好的模型可以用于各種類型的應用程序,包括:
- 網頁應用程序(通過 TensorFlow.js)
- 基于 Python 的桌面應用程序(通過 TensorFlow)
- 移動應用程序(通過 TensorFlow Lite)
開始使用
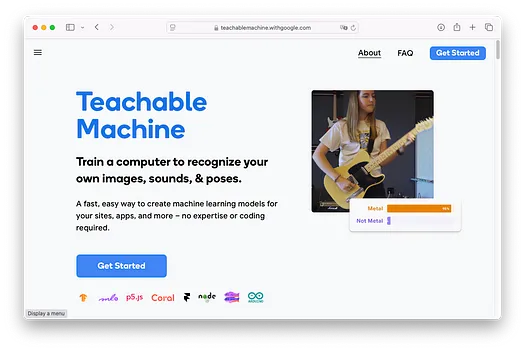
要開始使用 Teachable Machine,請訪問 https://teachablemachine.withgoogle.com/。您將看到以下界面:
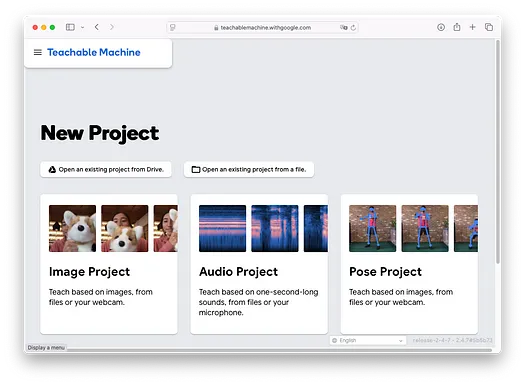
點擊Get Started按鈕,您將看到以下屏幕:
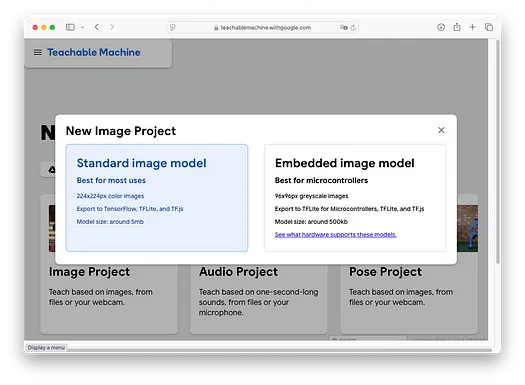
在本文中,我將使用 Teachable Machine 訓練一個模型來識別水果。具體來說,我的模型將幫助我們區分香蕉和草莓。選擇Image Project,您將看到以下界面:
選擇Standard image model項目,您將看到以下屏幕:
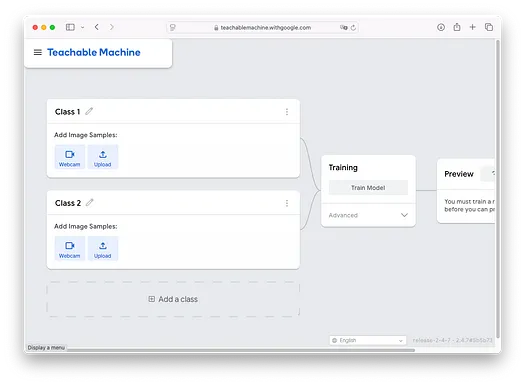
定義類別
在任何分類任務中,第一步是定義您想要識別的類別。在本例中,我們將專注于區分香蕉和草莓的圖像,創建兩個類別:**Banana** 和 **Strawberry**。要設置此內容,只需雙擊默認標簽“Class 1”和“Class 2”,并將它們重命名為您的類別:

請注意,您可以通過點擊屏幕底部的 **Add a class** 按鈕來創建更多類別:

為每個類別上傳圖像
定義類別后,下一步是為每個類別添加圖像。您可以直接使用網絡攝像頭拍攝圖像,或者為了方便起見,上傳現有的圖像。
點擊Upload按鈕:
您可以將幾張圖像拖放到下面的框中:
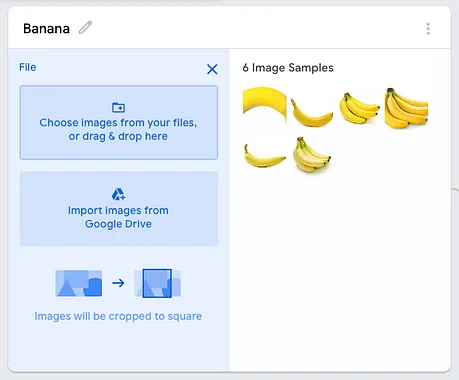
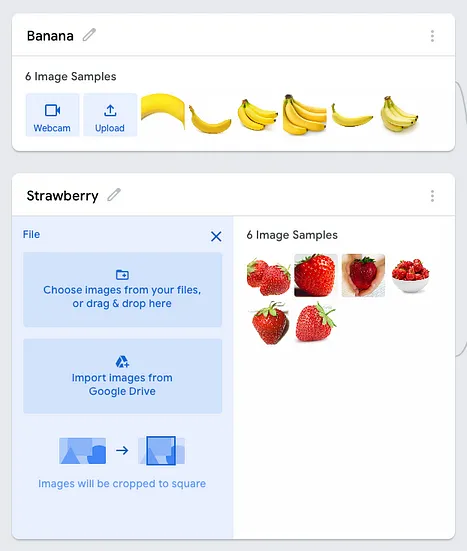
在我的示例中,我已經將一系列圖像拖放到兩個類別中:
訓練模型
為每個類別添加圖像后,就可以開始訓練模型了。點擊 **Train Model** 按鈕:
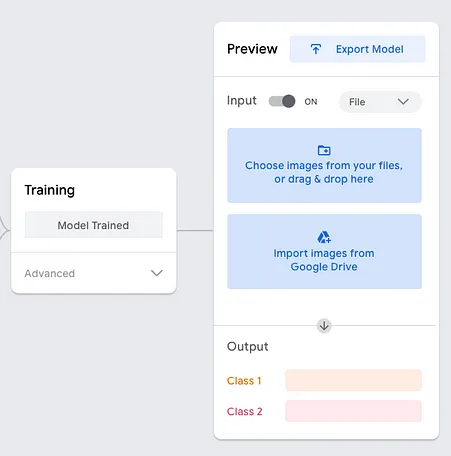
模型訓練完成后,您應該能夠看到類似以下內容:
測試模型
打開Input選項,您應該能夠通過直接將圖像拖放到下面的框中來測試模型:
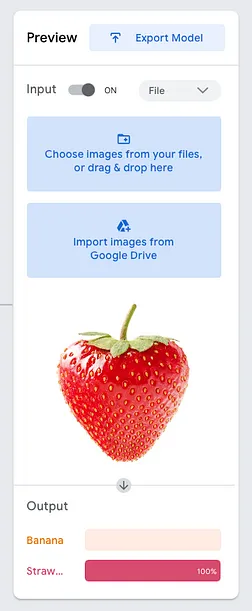
在上面的示例中,模型以 100% 的置信度檢測到圖像是草莓。您還可以使用網絡攝像頭測試模型。例如,在下圖中,我使用手機顯示了一串香蕉的圖片,模型準確地預測為“Banana”:

導出模型
雖然在網頁上直接測試模型很方便,但將其集成到自己的應用程序中則更具吸引力。幸運的是,您可以將訓練好的模型導出為獨立文件,從而在應用程序中以編程方式使用它。要導出模型,請點擊Export Model按鈕:

模型可以導出為:
- TensorFlow.js(用于網頁應用程序)
- TensorFlow(用于基于 Python 的應用程序)
- TensorFlow Lite(用于移動應用程序)
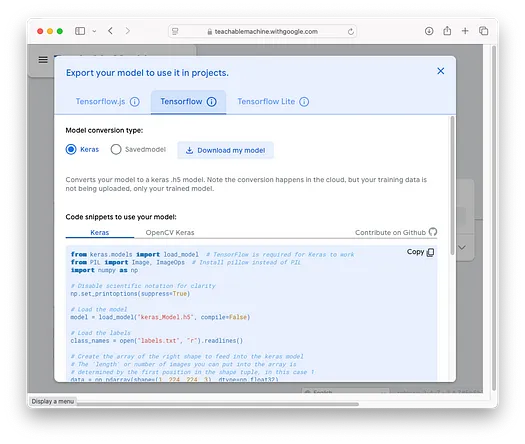
選擇您想要的模型類型,然后點擊 **Download my model** 按鈕。在本例中,我將下載 TensorFlow 模型。一個名為 `converted_keras.zip` 的文件將被下載。解壓縮該文件,您將看到其中包含兩個文件:
- keras_model.h5 — 訓練好的模型
- labels.txt — 包含類別列表的文件,例如 Banana 和 Strawberry
Teachable Machine 還提供了如何使用訓練好的模型進行編程的示例代碼。我們將在下一節中介紹這一點。
使用 Python 使用導出的模型
訓練好的模型導出并下載后,現在是時候看看如何在 Python 應用程序中使用它了。在嘗試之前,請注意以下幾點:
- Teachable Machine 生成的示例代碼基于較舊版本的 TensorFlow。因此,您需要確保您的機器使用較舊版本的 TensorFlow。
- 由于使用了較舊版本的 TensorFlow,您還需要將 Python 的版本限制為較早的版本。
嘗試示例代碼的最佳方法是創建一個虛擬環境。您可以通過運行以下命令來創建名為 `tf_old` 的虛擬環境,使用 Python 3.11 并安裝必要的 Anaconda 包:
$ conda create -n tf_old python=3.11 anaconda虛擬環境創建完成后,激活它并啟動 Jupyter Notebook:
$ conda activate tf_old
$ jupyter notebookJupyter Notebook 啟動后,您可以創建一個新的筆記本并開始編寫代碼。確保 `keras_model.h5` 和 `labels.txt` 文件與您的 Jupyter Notebook 位于同一文件夾中。
首先,如前所述,您需要安裝較舊版本的 TensorFlow。在我的測試中,TensorFlow 2.13.0 版本與 Python 3.11 中的示例代碼兼容。為此,請使用以下命令安裝 TensorFlow 和 Pillow 包:
!pip install tensorflow==2.13.0
!pip install pillow現在,您可以使用以下代碼片段加載訓練好的模型并加載名為 `fruit1.jpg` 的測試圖像:
from keras.models import load_model # TensorFlow 是 Keras 工作的基礎
from PIL import Image, ImageOps # 安裝 pillow 而不是 PIL
import numpy as np
# 禁用科學計數法以提高可讀性
np.set_printoptions(suppress=True)
# 加載模型
model = load_model("keras_Model.h5", compile=False)
# 加載標簽
class_names = open("labels.txt", "r").readlines()
# 創建形狀正確的數組以輸入到 Keras 模型中
# 數組中可以放入的圖像數量由形狀元組中的第一個位置決定,本例中為 1
data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
# 將此路徑替換為您的圖像路徑
image = Image.open("fruit1.jpg").convert("RGB")
# 將圖像調整為至少 224x224,然后從中心裁剪
size = (224, 224)
image = ImageOps.fit(image, size, Image.Resampling.LANCZOS)
# 將圖像轉換為 numpy 數組
image_array = np.asarray(image)
# 歸一化圖像
normalized_image_array = (image_array.astype(np.float32) / 127.5) - 1
# 將圖像加載到數組中
data[0] = normalized_image_array
# 模型預測
prediction = model.predict(data)
index = np.argmax(prediction)
class_name = class_names[index]
confidence_score = prediction[0][index]
# 打印預測結果和置信度分數
print("Class:", class_name[2:], end="")
print("Confidence Score:", confidence_score)`fruit1.jpg` 的輸出如下:

1/1 [==============================] - 0s 485ms/step
Class: Strawberry
Confidence Score: 0.9998473如果您遇到以下錯誤:
TypeError: Error when deserializing class 'DepthwiseConv2D' using config={'name': 'expanded_conv_depthwise', 'trainable': True, 'dtype': 'float32', 'kernel_size': [3, 3], 'strides': [1, 1], 'padding': 'same', 'data_format': 'channels_last', 'dilation_rate': [1, 1], 'groups': 1, 'activation': 'linear', 'use_bias': False, 'bias_initializer': {'class_name': 'Zeros', 'config': {}}, 'bias_regularizer': None, 'activity_regularizer': None, 'bias_constraint': None, 'depth_multiplier': 1, 'depthwise_initializer': {'class_name': 'VarianceScaling', 'config': {'scale': 1, 'mode': 'fan_avg', 'distribution': 'uniform', 'seed': None}}, 'depthwise_regularizer': None, 'depthwise_constraint': None}.
Exception encountered: Unrecognized keyword arguments passed to DepthwiseConv2D: {'groups': 1}這很可能意味著您正在使用較新版本的 TensorFlow,該版本與示例代碼不兼容。
構建網頁前端
與其每次測試新圖像時都修改代碼,不如通過使用 Gradio 包裝代碼來簡化流程。Gradio 提供了一個直觀的基于網頁的界面,允許用戶上傳圖像并查看預測結果,而無需修改底層代碼。首先,安裝 Gradio 包:
!pip install gradio以下代碼片段使用 Gradio 創建了一個網頁前端,允許用戶上傳圖像并實時從訓練好的模型中獲取預測結果。該界面使用戶能夠輕松地與模型交互,而無需手動修改或運行代碼:
import gradio as gr
from keras.models import load_model # TensorFlow 是 Keras 工作的基礎
from PIL import Image, ImageOps # 安裝 pillow 而不是 PIL
import numpy as np
# 加載模型
model = load_model("keras_Model.h5", compile=False)
# 加載標簽
class_names = open("labels.txt", "r").readlines()
# 定義預測函數
def classify_image(image):
# 將圖像調整為 224x224 并歸一化
size = (224, 224)
image = ImageOps.fit(image, size, Image.Resampling.LANCZOS).convert("RGB")
image_array = np.asarray(image)
normalized_image_array = (image_array.astype(np.float32) / 127.5) - 1
data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
data[0] = normalized_image_array
# 使用模型進行預測
prediction = model.predict(data)
index = np.argmax(prediction)
class_name = class_names[index].strip() # 去除任何尾隨空格或換行符
confidence_score = prediction[0][index]
return f"{class_name}, Confidence Score: {float(confidence_score)}"
# 創建 Gradio 界面
interface = gr.Interface(
fn = classify_image,
inputs = gr.Image(type="pil"), # 接受圖像作為輸入
outputs = [
gr.Label(label="Prediction"), # 類別名稱和置信度分數作為標簽輸出
],
title = "Image Classifier",
description = "上傳圖像,模型將將其分類為預定義的類別之一。"
)
# 啟動 Gradio 應用程序
interface.launch()運行代碼后,您將看到以下界面:
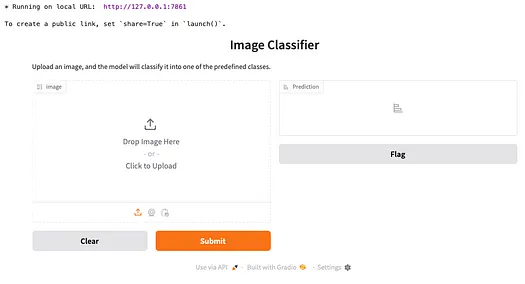
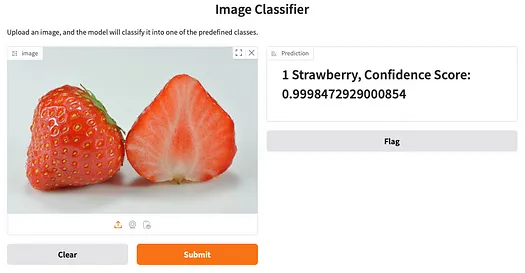
將草莓圖像拖放到左側的框中,然后點擊 **Submit** 按鈕。您將在右側看到結果:
總結
在本文中,我探索了 Teachable Machine,這是 Google 提供的一款基于網頁的工具,使用戶無需編程技能即可創建機器學習模型。我介紹了該工具,并解釋了如何為區分香蕉和草莓圖像等任務定義類別。我演示了如何為這些類別添加圖像、測試模型并將其導出以集成到自定義應用程序中。此外,我還展示了如何使用 Gradio 創建一個簡單的網頁界面,允許使用導出的模型進行實時預測。