Yelp的實時流技術之三:不止是模式存儲服務的Schematizer
作者:佚名
當你的系統每天要實時從MySQL到Kafka發布幾十億條消息時,你會怎么管理這些數據的模式信息呢?
這是關于Yelp的實時流數據基礎設施系列文章的第三篇。這個系列會深度講解我們如何用“確保只有一次”的方式把MySQL數據庫中的改動實時地以流的方式傳輸出去,我們如何自動跟蹤表模式變化,如何處理和轉換流,以及最終如何把這些數據存儲到Redshift或Salesforce之類的數據倉庫中去。
當你的系統每天要實時從MySQL到Kafka發布幾十億條消息時,你會怎么管理這些數據的模式信息呢?當你的系統要接入幾百個服務時,你就要處理幾千種不同的模式,手工管理是不可行的。必須有自動化的方案來處理從上游數據源到所有下游消費者的模式改變問題。Confluent公司的Schema Registry和Kafka Connect都是不錯的選擇,可惜當我們開始構建Yelp數據管道時它們還沒發布。因此就有了我們的Schematizer。
Schematizer是什么?
Yelp數據管道的一個重要設計就是將所有數據都模式化,也就是說,所有流經數據管道的數據都必須遵守某種預先定義好的模式,而不是格式隨意的。為什么非要強調這一點呢?因為我們想讓所有的數據消費者都可以對他們要獲取的數據格式有預期,因此可以在上游數據生產者決定改變他們發布的數據模式時,不會對下游造成非常大的影響。統一的模式表現也讓Yelp數據管道可以輕松地整合各種使用不同數據格式的系統。
Schematizer是用于跟蹤和管理所有數據管道中用到的模式,并且提供自動化文檔支持等功能的模式存儲服務。我們使用Apache Avro來表達模式。Avro有許多我們在數據管道中需要的功能,尤其是模式演進,它是解耦數據生產者和消費者的關鍵因素之一。每一條流經數據管道的消息都用Avro模式序列化過。為了減小消息體積,我們沒有把全部模式信息都放在消息里,而只是帶上了模式的ID。數據消費者可以用ID來在運行時從Schematizer中獲取模式信息并將消息反序列化。Schematizer是所有預定義的模式信息的唯一可靠來源。
我們用不同方法管理模式。
Schematizer用兩種方法組織和管理模式:從數據生產者的角度和數據消費者的角度。
第一種方法根據數據的產生信息來將模式分組,每個組由名字空間和數據源來定義。生產者在向Schematizer注冊模式時必須提供名字空間和數據源信息。比如一個準備向數據管道發布數據庫數據的服務,它就可以把服務名作為名字空間,把表名作為數據源。
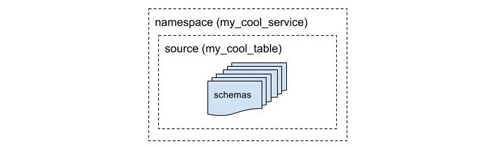
根據名字空間和數據源來將模式分組
第二種方法按數據的目的方信息來分組。比如Redshift集群或者MySQL數據庫都是數據目的方,它們會對應一個或多個數據生產者,每個數據生產者又會關聯一個或多個模式,這就對應著第一種方法中定義的名字空間和數據源。
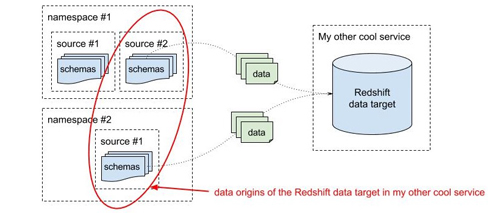
根據單個數據目的方來將模式分組
這兩種方法讓我們可以按不同的需要來檢索和相關的模式。比如,一個程序可能想知道它會向哪些Topic發布數據,另一個服務又想知道它的Redshift集群中的數據都來自哪里。
我們這樣注冊模式。
數據管道要求所有發布到其中的數據都必須用預定義的Avro模式進行模式化和序列化。因此,當一個數據生產者準備向數據管道發布數據時,它要做的第一件事就是向Schematizer注冊模式,最通用的辦法就是直接注冊一個Avro模式。
對于沒有或者無法創建Avro模式的數據生產者,也可以向Schematizer中加入模式轉換器來把非Avro模式轉換成Avro模式。MySQLStreamer就是一個代表,它是一個把MySQL數據庫中的數據發布到數據管道的服務,它只知道MySQL表模式。Schematizer可以把MySQL表模式定義轉換成相應的Avro模式。但如果數據生產者改變了模式定義的話,它必須重新注冊。
上游模式改變會不會影響下游服務?
所有數據管道服務都不能回避的共同痛點就是該如何應對上游模式改變。通常這都需要許多在上游生產者和下游消費者之間的溝通和協調工作。Yelp也不能免俗。我們也有批量任務和系統,它們要處理別的批量任務和系統產生的數據。每一次上游的模式改變都是非常痛苦的,它可能導致下游服務崩潰,整個處理過程都是非常耗費人力的。
我們通過模式兼容性來解決這個問題。在模式注冊過程中,Schematizer會根據模式兼容性來決定Topic和新模式之間的對應關系。只有兼容的模式才能延用舊的Topic。如果有不兼容模式注冊上來,Schematizer會用相同的名字空間和數據源來為新模式注冊一個新的Topic。那Schematizer又怎么確定兼容性呢?答案就是Avro解釋規則(Avro resolution rules)。Avro解釋規則保證在相同的Topic中,用新版模式打包的消息可以按舊版模式解包,反之亦然。
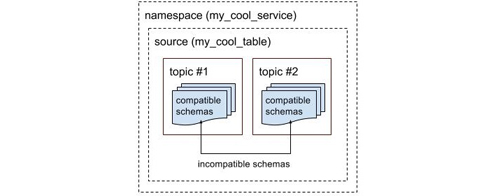
不兼容的模式會分配不同的Topic
目前Yelp數據管道中大部分數據都產生自MySQLStreamer。比如我們想為某業務表增加一個字段,MySQLStreamer就會向Schematizer注冊新模式。因為按照Avro解釋規則這樣的改動是兼容的,所以Schematizer會創建新Avro模式,并把這個名字空間和數據源對應的舊的Topic分配給它。可如果是想把某字段從int改成varchar,那這就是一個不兼容的改動了,Schematizer會為新模式創建一個新Topic。
保證了在Topic內部的模式兼容性,下游數據消費者就可以放心的用舊模式去處理這個Topic中的任何數據,不必擔心數據模式變化會引起自身的崩潰等任何問題。他們也可以根據自己的需要在合適的時候連上新Topic。這就讓整個系統自動化程度更高,在模式改變時減少人工介入。
除了Avro解釋規則,我們也在Schematizer中定義了一些自己的規則來支持一些數據管道功能。模式的主鍵字段被用于在數據管道中做日志壓縮。因為對同一個Topic來說做日志壓縮的主鍵必須保持一致,所以任何對主鍵的改動都被認為是不兼容的,會導致Schematizer為新模式創建一個新Topic。而且,當人工不可讀(non-PII,Personally Identifiable Information)的模式開始包含人工可讀字段時,這樣的改動也被認為是不兼容的。人工不可讀的數據和人工可讀的數據必然分開存儲,這樣就簡化了人工可讀數據的安全實現,避免了下游消費者不小心讀到一些他們本來沒有權限讀的數據。
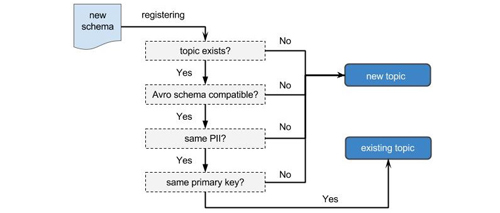
決定是否需要新Topic的邏輯流程
值得一提的是模式注冊過程是冪等的。如果把相同的模式注冊多次,那只有第一次會產生一個新模式,后面的都直接返回已注冊的模式。這就讓應用程序和服務可以非常容易地初始化它們的Avro模式。許多應用程序和服務都是把Avro模式定義在文件中或代碼中的,但它們沒辦法寫死模式ID,因為模式ID是由Schematizer管控的。所以應用程序可以調用模式注冊接口來直接注冊模式,如果已經存在就把模式信息取回來了,如果不存在就直接注冊,一舉兩得。
將模式改變事件處理全部流水線化。
為了讓數據管道可以完全以流水線的方式處理模式改變事件,Schematizer會根據當前模式和新模式的信息來為下游系統生成模式遷移計劃。目前Schematizer只能為Redshift表生成模式遷移計劃。對于把數據從數據管道中應用到Redshift集群的下游系統來說,在模式發生改變時它可以直接獲取模式遷移計劃并且執行,而且自動獲取新的模式信息,不需要任何人工介入。這個功能是很容易擴展的,而且模式遷移計劃生成器也是很容易替換的,所以將來我們會增加更多的模式遷移計劃生成器來支持更多的模式類型,或者改用更好的算法來生成遷移計劃。
Schematizer知道所有數據生產者和消費者的信息。
除了管理注冊的模式,Schematizer還會跟進所有數據生產者和消費者的信息,包括哪個團隊哪個服務負責生產或消費什么數據,發布數據的頻率如何,等等。在需要人工介入時我們就可以用這些信息來有效地找到相應團隊并與他們溝通協商。而且這些信息也可以幫助我們監控和找出那些過期了的模式和Topic,從而可以將它們做廢或刪除。這樣,就可以在新模式注冊上來時簡化兼容性驗證工作。Schematizer可以跳過那些廢棄的模式,只檢查新模式與Topic內剩下的有效的模式的兼容性就可以了。
所有數據生產者和消費者在啟動時都必須提供這些信息。最初我們只想著把它們保存在Schematizer里就好了,但事實上這些信息對探索性的分析和預警都是非常有用的,最終我們決定把它們寫到數據管道系統之外的單獨的Kafka Topic中。這樣數據就可以被Redshift和Splunk處理,也可以導入Schematizer和通過前端Web界面展示出來。我們用的是Yelp自行研發的通過Clog寫入數據的異步、非阻塞式Kafka生產者,這樣就不會影響生產者正常地發布數據。另外,這樣也可以避免環形依賴,有時候正常的生產者要用相同的信息去注冊多次。
該用哪個Kafka Topic呢?Schematizer會處理好這些細節。
與一般意義上的Kafka生產者不同,數據管道的數據生產者不需要事先知道它們應該把數據發送到哪個Kafka Topic中。因為Schematizer規定了注冊上來的模式和Topic之間的對應關系,所以數據生產者只要提供自己序列化數據所使用的模式信息,就可以從Schematizer那里得到正確的Topic信息并發布數據了。將Topic信息抽象出去可以讓接口更簡單易用。
對數據消費者也是類似的機制。盡管也可以給它們定下一些具體的Topic去消費,但更常見的用例是讓Schematizer根據數據消費者感興趣的組的信息來提供正確的Topic。在本文前面章節介紹了各種不同的分組機制。數據消費都可以或者指定名字空間和數據源,或者指定數據目的方,Schematizer就會找出那個組內的相應Topic。這種機制對于數據消費者感興趣的一組Topic可能由于模式的不兼容改變而變來變去的場景尤其有效。它讓數據消費者不必再跟蹤組內的每一個Topic。
模式很好,文檔更好!
模式把數據格式化了,但對于想了解數據確切意義的人來說提供的信息可能又不夠。我們注意到使用數據的人通常不是生產數據的人,因此他們不知道去哪里找到有用的信息來讓他們理解他們要用的數據。因為Schematizer負責管理數據管道中的所有模式,所以把數據的描述信息也保存在它這里就很合適。
知識挖掘器Watson隆重出場。
Schematizer要求模式的注冊方隨著模式一起提供文檔,然后Schematizer會提取文檔信息并保存起來。為了讓Yelp公司內的各個團隊可以獲得模式和數據文檔,我們開發了Watson,一個全公司員工都可以用來挖掘數據內容的Webapp。Watson實際上是Schematizer的一個可視化前端,它通過Schematizer的幾個RESTful API來獲取數據。
Watson提供了關于數據管道狀態的有價值信息:現有的名字空間、數據源及相關的Avro模式信息。最重要的是,Watson為查看Schematizer管理的所有數據源和模式信息提供了簡單的方法。
文檔并不是天上掉下來的。
目前流經我們數據管道的數據主要都來自于數據庫。我們用SQLAlchemy模型來為這些數據的數據源和模式整理文檔。在Yelp,SQLAlchemy用來描述我們數據庫中的所有模型。除了docstring之外,SQLAlchemy還允許用戶為模型的字段增加額外信息。因此,它自然成了我們保存文檔的首選之處,記錄各個數據模型和字段的目的和意義。
SQLAlchemy還引入了一個屬主字段來記錄每個模型的維護者和專家。我們認為生成數據的人是提供文檔的最佳人選。另外,這種方法也會鼓勵大家時刻保持真實數據模型與描述的同步。
- class BizModel(Base):
- __yelp_owner__ = Ownership(
- teams=[TEAM_OWNERS['biz_team'],
- members=[],
- contacts=[]
- )
- __table_name__ = 'my_biz_table'
- __doc__ = 'Business information.'
- id = Column(Integer, primary_key=True, doc=r"""ID of the business.""")
- name = Column(String(64), doc=r"""Name of the business.""")
一個簡單的包含文檔和屬主信息的SQLAlchemy模型
可是開發者在做SQLAlchemy模型的時候并不總是會記得提供文檔信息。為了防止這樣的事情發生,我們開發了自動校驗功能來強制要求所有模型都必須完整地提供了屬性描述和文檔,這是絕不會退讓的硬性標準。每當有新模型要加入時,如果要求的文檔信息不完備,或者沒有屬主信息,校驗就會失敗。這些自動校驗功能幫助我們朝著100%文檔覆蓋率的目標邁進了一大步。
為Watson提取高質量文檔。
當數據模型有了文檔之后,我們就可以把它導入Schematizer并最終通過Watson展現出去。在深入具體提取流程之前,我們先介紹一下這個過程中的另一個重要模塊:特定應用轉換器(Application Specific Transformer),簡寫為AST。與名字含義一樣,AST從一個或多個數據管道Topic中輸入消息流,用轉換邏輯處理消息模式和數據包,再把轉換后的消息輸出到另外的數據管道Topic中。提供具體轉換處理的轉換模塊是可以串連起來的,因此可以組合多個模塊來做非常細致的轉換工作。
我們用AST中的許多個轉換模塊來依據SQLAlchemy模型生成更易理解的數據。因為模塊是可以串連的,現在我們只是簡單的創建一個從SQLAlchemy模型中提取文檔和屬主信息的轉換模塊,并把它加入 到已有的轉換鏈中。這樣,所有模型的文檔和屬主信息就通過現有管道自動提取并導入Schematizer了。實現過程相當簡單,并無縫接入管道,所以可以非常有效地生成高質量文檔。
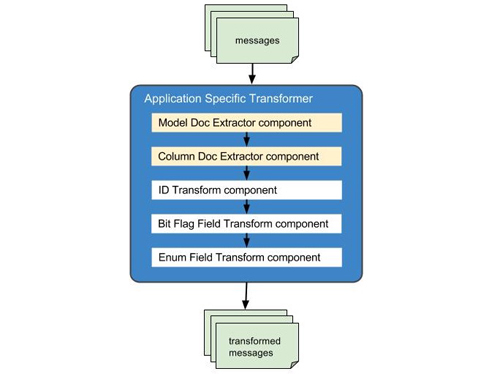
AST中的轉換模塊
如上所述,AST中現在已經有了一些為用戶生成更有意義的信息的轉換模塊。位標志轉換模塊會解釋一個整型字段的不同數據位的具體含義。相似地,Enum字段轉換模塊也會把Enum值轉換成可讀的文字表述。這些轉換模塊帶來的另一個好處是它們同時也產生了自解釋和自生成文檔的模式,因此也產生了更好的文檔。
合作、貢獻與檢索
開發者的文檔并不是我們要講述的最后一項內容。Watson也提供了功能讓終端用戶可以一起努力,為使Yelp的數據更具可讀性而貢獻自己的力量。
第一個功能就是打標簽。Watson允許用戶為任意數據源打標簽分類。一個數據源可能是個MySQL數據庫表,也可能是個數據模型。比如,一個業務數據源可以打上“Business Information”的標簽,而一個用戶信息數據源可以打上“User Information”標簽。終端用戶可以把相關的數據源都打上相同的標簽,這樣以對自己最有意義的方式把它們組織在一起。打標簽可以讓我們更深入的理解我們的各個數據源之間是如何彼此關聯的。

打上了“Business Info”標簽的業務數據源
Watson提供的另一個功能是添加注釋。終端用戶,尤其是非技術人員,可以通過這種方法來為一個數據源或字段提供他們自己的文檔。比如業務分析師常常就會對使用數據有非常寶貴的見解,他們可以通過注釋來分享各種疑難雜癥、邊界用例和時效性很強的信息。
終端用戶對于Watson的最大的需求就是檢索。我們在Watson中實現了簡單的檢索引擎,讓用戶可以檢索數據的模式、Topic、數據模型描述等各方面信息。在檢索后臺我們沒有用Elasticsearch,而是選擇了Whoosh Python包,因為它可以幫助我們快速完成開發。就我們目前的檢索量來說Whoosh的性能足以應付。隨著數據規模增大,我們將來會考慮換用其它更易擴展的引擎。
結論
Schematizer是Yelp數據管道的一個重要組成部分。它的模式注冊操作是數據管道的許多重要功能的基礎,包括在上游數據生產者更改模式時減輕對下游消費者程序和服務的影響等。Schematizer也管理了數據發布的Topic分配,讓用戶不必再關心具體使用哪個Topic等這樣的細節。最后,它要求所有寫入數據管道的數據都必須有文檔,這促進了全公司內的知識分享。Watson的加入更是使得Yelp公司內的所有員工都可以方便地得到最及時的信息。
責任編輯:武曉燕
來源:
網絡大數據