消息的存儲-RocketMQ知識體系之三
RocketMQ存儲概要設計
RocketMQ主要存儲的文件包括commitlog文件、consumeQueue文件、IndexFile文件。
CommitLog是消息存儲文件,所有消息主題的消息都存儲在CommitLog文件中;該文件默認最大為1GB,超過1GB后會輪到下一個CommitLog文件。通過CommitLog,RocketMQ將所有消息存儲在一起,以順序IO的方式寫入磁盤,充分利用了磁盤順序寫減少了IO爭用提高數據存儲的性能。
RocketMQ的Broker機器磁盤上的文件存儲結構

【CommitLog】
消息在CommitLog中的存儲格式如下:
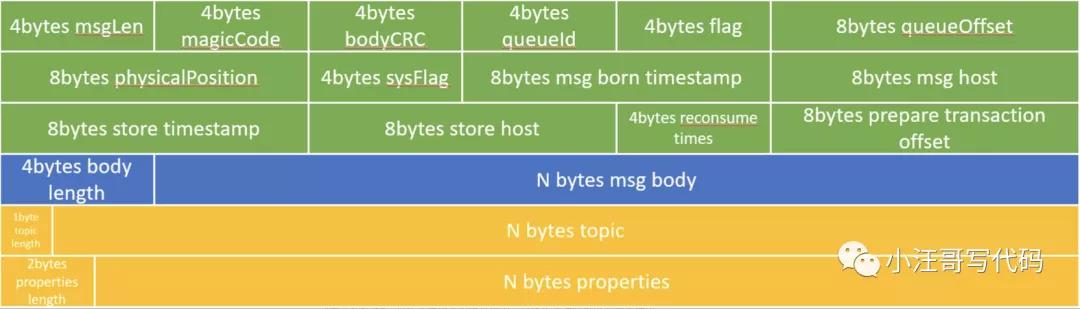
存儲所有消息內容,寫滿一個文件后生成新的 commitlog 文件。所有 topic 的數據存儲在一起,邏輯視圖如下:

CommitLog代碼
- private static final Logger log = LoggerFactory.getLogger(LoggerName.STORE_LOGGER_NAME);
- /**
- * MAGIC_CODE - MESSAGE
- * Message's MAGIC CODE daa320a7
- * 標記某一段為消息,即:[msgId, MESSAGE_MAGIC_CODE, 消息]
- */
- public final static int MESSAGE_MAGIC_CODE = 0xAABBCCDD ^ 1880681586 + 8;
- /**
- * MAGIC_CODE - BLANK
- * End of file empty MAGIC CODE cbd43194
- * 標記某一段為空白,即:[msgId, BLANK_MAGIC_CODE, 空白]
- * 當CommitLog無法容納消息時,使用該類型結尾
- */
- private final static int BLANK_MAGIC_CODE = 0xBBCCDDEE ^ 1880681586 + 8;
- /**
- * 映射文件隊列
- */
- private final MappedFileQueue mappedFileQueue;
- /**
- * 消息存儲
- */
- private final DefaultMessageStore defaultMessageStore;
- /**
- * flush commitLog 線程服務
- */
- private final FlushCommitLogService flushCommitLogService;
- /**
- * If TransientStorePool enabled, we must flush message to FileChannel at fixed periods
- * commit commitLog 線程服務
- */
- private final FlushCommitLogService commitLogService;
- /**
- * 寫入消息到Buffer Callback
- */
- private final AppendMessageCallback appendMessageCallback;
- /**
- * topic消息隊列 與 offset 的Map
- */
- private HashMap<String/* topic-queue_id */, Long/* offset */> topicQueueTable = new HashMap<>(1024);
- /**
- * TODO
- */
- private volatile long confirmOffset = -1L;
- /**
- * 當前獲取lock時間。
- * 如果當前解鎖,則為0
- */
- private volatile long beginTimeInLock = 0;
- /**
- * true: Can lock, false : in lock.
- * 添加消息 螺旋鎖(通過while循環實現)
- */
- private AtomicBoolean putMessageSpinLock = new AtomicBoolean(true);
- /**
- * 添加消息重入鎖
- */
- private ReentrantLock putMessageNormalLock = new ReentrantLock(); // Non fair Sync
【ConsumeQueue】
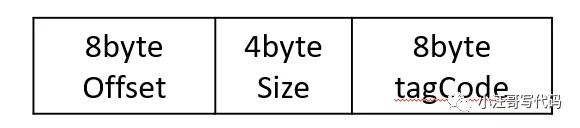
ConsumeQueue是消息消費隊列文件,消息達到commitlog文件后將被異步轉發到消息消費隊列,供消息消費者消費;一個ConsumeQueue表示一個topic的一個queue,類似于kafka的一個partition,但是rocketmq在消息存儲上與kafka有著非常大的不同,RocketMQ的ConsumeQueue中不存儲具體的消息,具體的消息由CommitLog存儲,ConsumeQueue中只存儲路由到該queue中的消息在CommitLog中的offset,消息的大小以及消息所屬的tag的hash(tagCode),一共只占20個字節,整個數據包如下:
ConsumeQueue代碼
- public static final int CQ_STORE_UNIT_SIZE = 20;
- private static final Logger log = LoggerFactory.getLogger(LoggerName.STORE_LOGGER_NAME);
- private static final Logger LOG_ERROR = LoggerFactory.getLogger(LoggerName.STORE_ERROR_LOGGER_NAME);
- private final DefaultMessageStore defaultMessageStore;
- /**
- * 映射文件隊列
- */
- private final MappedFileQueue mappedFileQueue;
- /**
- * Topic
- */
- private final String topic;
- /**
- * 隊列編號
- */
- private final int queueId;
- /**
- * 消息位置信息ByteBuffer
- */
- private final ByteBuffer byteBufferIndex;
- /**
- * 文件存儲地址
- */
- private final String storePath;
- /**
- * 每個映射文件大小
- */
- private final int mappedFileSize;
- /**
- * 最大重放消息commitLog存儲位置
- */
- private long maxPhysicOffset = -1;
- private volatile long minLogicOffset = 0;
Consume Queue文件組織,如圖所示:

Consume Queue文件組織示意圖
- 根據topic和queueId來組織文件,圖中TopicA有兩個隊列0,1,那么TopicA和QueueId=0組成一個ConsumeQueue,TopicA和QueueId=1組成另一個ConsumeQueue。
- 按照消費端的GroupName來分組重試隊列,如果消費端消費失敗,消息將被發往重試隊列中,比如圖中的%RETRY%ConsumerGroupA。
- 按照消費端的GroupName來分組死信隊列,如果消費端消費失敗,并重試指定次數后,仍然失敗,則發往死信隊列,比如圖中的%DLQ%ConsumerGroupA。
死信隊列(Dead Letter Queue)一般用于存放由于某種原因無法傳遞的消息,比如處理失敗或者已經過期的消息。
【IndexFile】
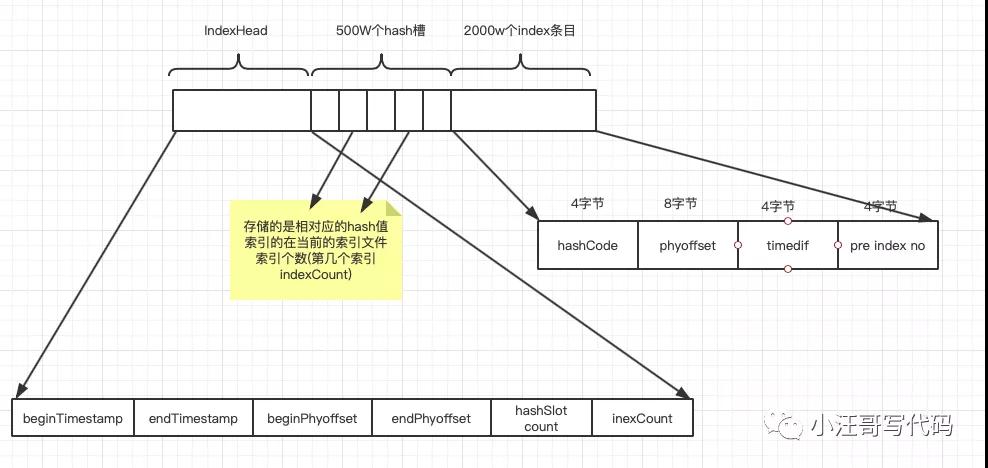
IndexFile是消息索引文件,主要存儲的是key和offset的對應關系。
IndexFile(索引文件)提供了一種可以通過key或時間區間來查詢消息的方法。
文件名fileName是以創建時的時間戳命名的,固定的單個IndexFile文件大小約為400M,一個IndexFile可以保存 2000W個索引,IndexFile的底層存儲設計為在文件系統中實現HashMap結構,故rocketmq的索引文件其底層實現為hash索引。
- private static final Logger log = LoggerFactory.getLogger(LoggerName.STORE_LOGGER_NAME);
- private static int hashSlotSize = 4;
- private static int indexSize = 20;
- private static int invalidIndex = 0;
- private final int hashSlotNum;
- private final int indexNum;
- private final MappedFile mappedFile;
- private final FileChannel fileChannel;
- private final MappedByteBuffer mappedByteBuffer;
- private final IndexHeader indexHeader;
IndexFile的存儲結構:
從上面的分析可以看出,RocketMQ采用的是混合型的存儲結構,即為Broker單個實例下所有的隊列共用一個日志數據文件(即為CommitLog)來存儲。RocketMQ的混合型存儲結構(多個Topic的消息實體內容都存儲于一個CommitLog中)針對Producer和Consumer分別采用了數據和索引部分相分離的存儲結構,Producer發送消息至Broker端,然后Broker端使用同步或者異步的方式對消息刷盤持久化,保存至CommitLog中。
只要消息被刷盤持久化至磁盤文件CommitLog中,那么Producer發送的消息就不會丟失。
正因為如此,Consumer也就肯定有機會去消費這條消息。當無法拉取到消息后,可以等下一次消息拉取,同時服務端也支持長輪詢模式,如果一個消息拉取請求未拉取到消息,Broker允許等待30s的時間,只要這段時間內有新消息到達,將直接返回給消費端。這里,RocketMQ的具體做法是,使用Broker端的后臺服務線程—ReputMessageService不停地分發請求并異步構建ConsumeQueue(邏輯消費隊列)和IndexFile(索引文件)數據。
【全局的角度來看消息的存儲】
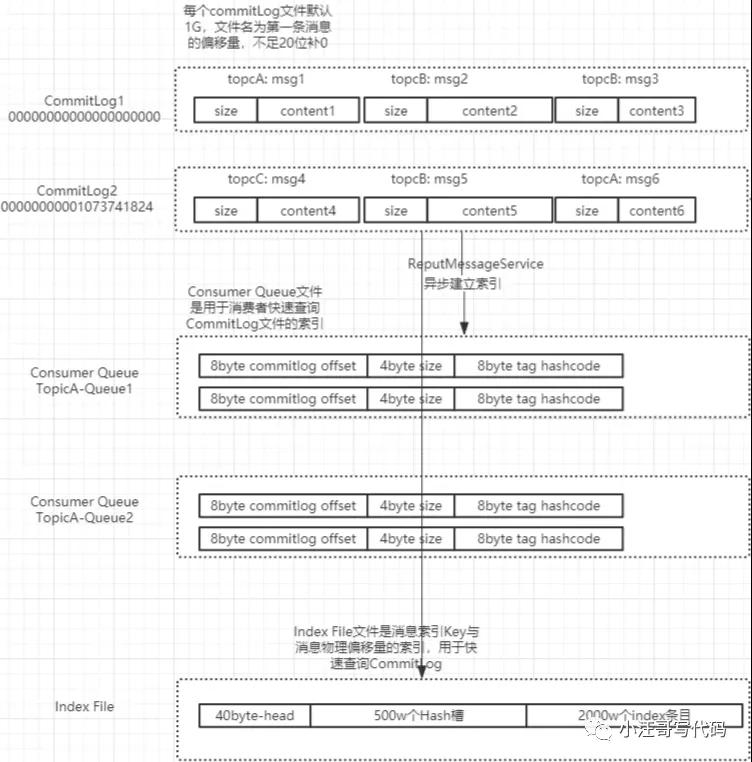
【消息存儲流程】
Broker端收到消息后,將消息原始信息保存在CommitLog文件對應的MappedFile中,然后異步刷新到磁盤
ReputMessageServie線程異步的將CommitLog中MappedFile中的消息保存到ConsumerQueue和IndexFile中
ConsumerQueue和IndexFile只是原始文件的索引信息
內存映射和數據刷盤
【內存映射流程】
- 內存映射文件MappedFile通過AllocateMappedFileService創建
- MappedFile的創建是典型的生產者-消費者模型
- MappedFileQueue調用getLastMappedFile獲取MappedFile時,將請求放入隊列中
- AllocateMappedFileService線程持續監聽隊列,隊列有請求時,創建出MappedFile對象
- 最后將MappedFile對象預熱,底層調用force方法和mlock方法。
【刷盤機制】
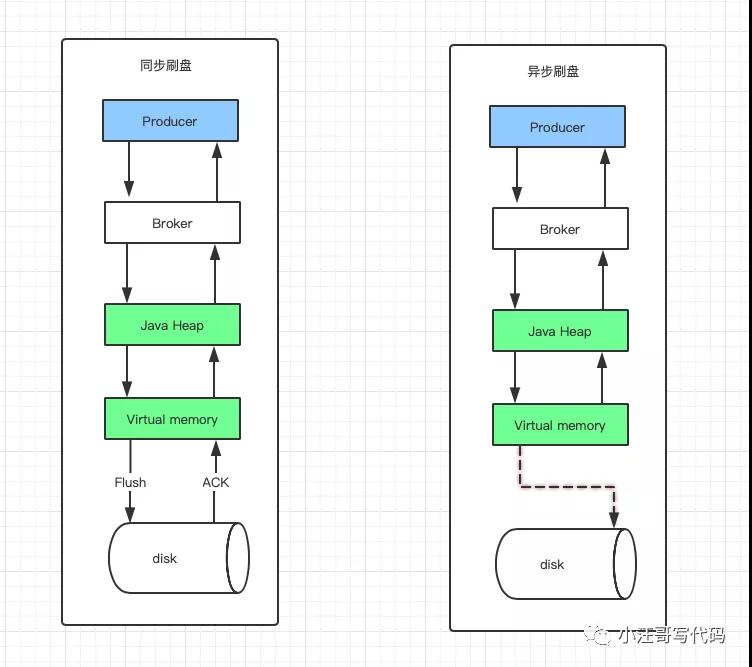
- 異步刷盤:消息被寫入內存的PAGECACHE,返回寫成功狀態,當內存里的消息量積累到一定程度時,統一觸發寫磁盤操作,快速寫入 。吞吐量高,當磁盤損壞時,會丟失消息
- 同步刷盤:消息寫入內存的PAGECACHE后,立刻通知刷盤線程刷盤,然后等待刷盤完成,刷盤線程執行完成后喚醒等待的線程,給應用返回消息寫成功的狀態。吞吐量低,但不會造成消息丟失。
【刷盤流程】
producer發送給broker的消息保存在MappedFile中,然后通過刷盤機制同步到磁盤中。
刷盤分為同步刷盤和異步刷盤。
異步刷盤后臺線程按一定時間間隔執行。
同步刷盤也是生產者-消費者模型。broker保存消息到MappedFile后,創建GroupCommitRequest請求放入列表,并阻塞等待。后臺線程從列表中獲取請求并刷新磁盤,成功刷盤后通知等待線程。
RocketMQ 文件存儲模型層次結構
文件存儲模型層次結構圖
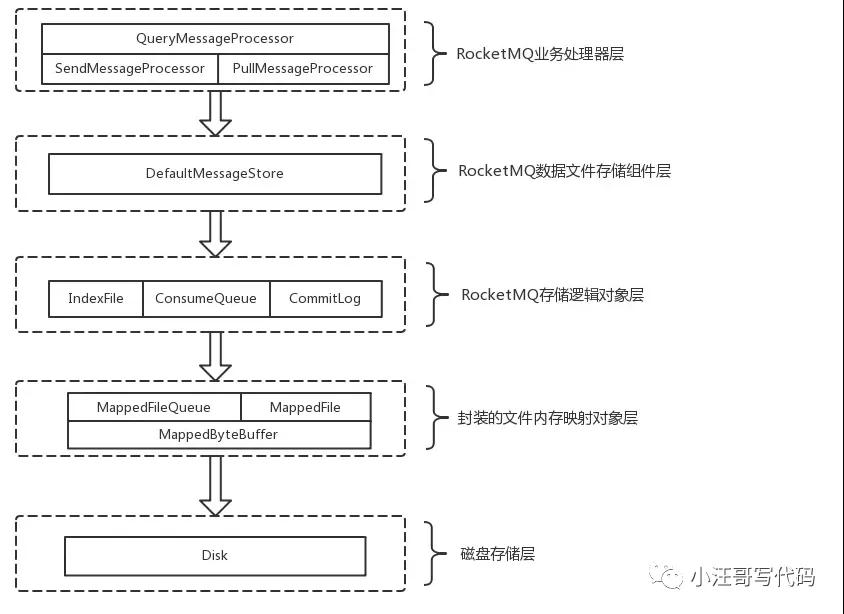
RocketMQ文件存儲模型層次結構如上圖所示,根據類別和作用從概念模型上大致可以劃分為5層,下面將從各個層次分別進行分析和闡述:
RocketMQ業務處理器層:Broker端對消息進行讀取和寫入的業務邏輯入口,比如前置的檢查和校驗步驟、構造MessageExtBrokerInner對象、decode反序列化、構造Response返回對象等;
RocketMQ數據存儲組件層;該層主要是RocketMQ的存儲核心類—DefaultMessageStore,其為RocketMQ消息數據文件的訪問入口,通過該類的“putMessage()”和“getMessage()”方法完成對CommitLog消息存儲的日志數據文件進行讀寫操作(具體的讀寫訪問操作還是依賴下一層中CommitLog對象模型提供的方法);另外,在該組件初始化時候,還會啟動很多存儲相關的后臺服務線程,包括AllocateMappedFileService(MappedFile預分配服務線程)、ReputMessageService(回放存儲消息服務線程)、HAService(Broker主從同步高可用服務線程)、StoreStatsService(消息存儲統計服務線程)、IndexService(索引文件服務線程)等;
RocketMQ存儲邏輯對象層:該層主要包含了RocketMQ數據文件存儲直接相關的三個模型類IndexFile、ConsumerQueue和CommitLog。IndexFile為索引數據文件提供訪問服務,ConsumerQueue為邏輯消息隊列提供訪問服務,CommitLog則為消息存儲的日志數據文件提供訪問服務。這三個模型類也是構成了RocketMQ存儲層的整體結構(對于這三個模型類的深入分析將放在后續篇幅中);
封裝的文件內存映射層:RocketMQ主要采用JDK NIO中的MappedByteBuffer和FileChannel兩種方式完成數據文件的讀寫。其中,采用MappedByteBuffer這種內存映射磁盤文件的方式完成對大文件的讀寫,在RocketMQ中將該類封裝成MappedFile類。這里限制的問題在上面已經講過;對于每類大文件(IndexFile/ConsumerQueue/CommitLog),在存儲時分隔成多個固定大小的文件(單個IndexFile文件大小約為400M、單個ConsumerQueue文件大小約5.72M、單個CommitLog文件大小為1G),其中每個分隔文件的文件名為前面所有文件的字節大小數+1,即為文件的起始偏移量,從而實現了整個大文件的串聯。這里,每一種類的單個文件均由MappedFile類提供讀寫操作服務(其中,MappedFile類提供了順序寫/隨機讀、內存數據刷盤、內存清理等和文件相關的服務);
磁盤存儲層:主要指的是部署RocketMQ服務器所用的磁盤。這里,需要考慮不同磁盤類型(如SSD或者普通的HDD)特性以及磁盤的性能參數(如IOPS、吞吐量和訪問時延等指標)對順序寫/隨機讀操作帶來的影響;
文件存儲的高可用
【分布式存儲】
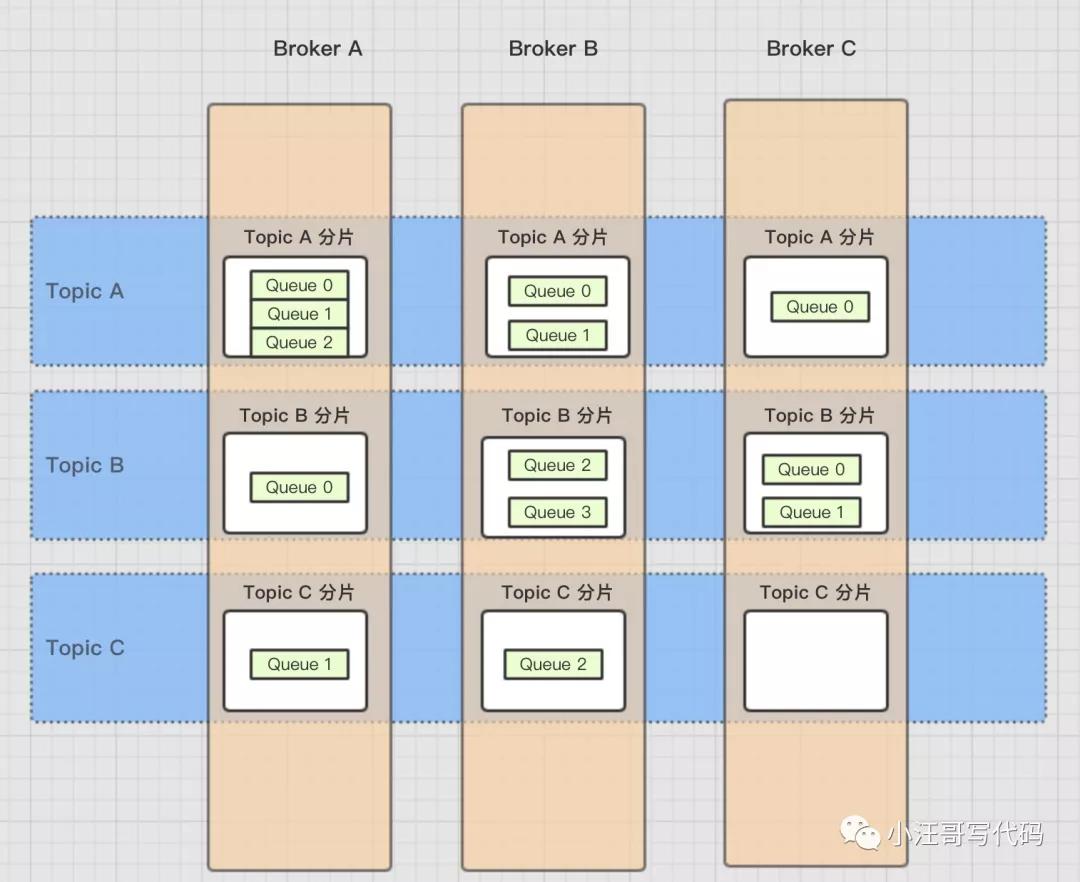
同一個topic 上的數據會分成多個queue 分布在不同的 broker 上,而且每個queue 都有副本機制。
【副本的主從同步(HA)】
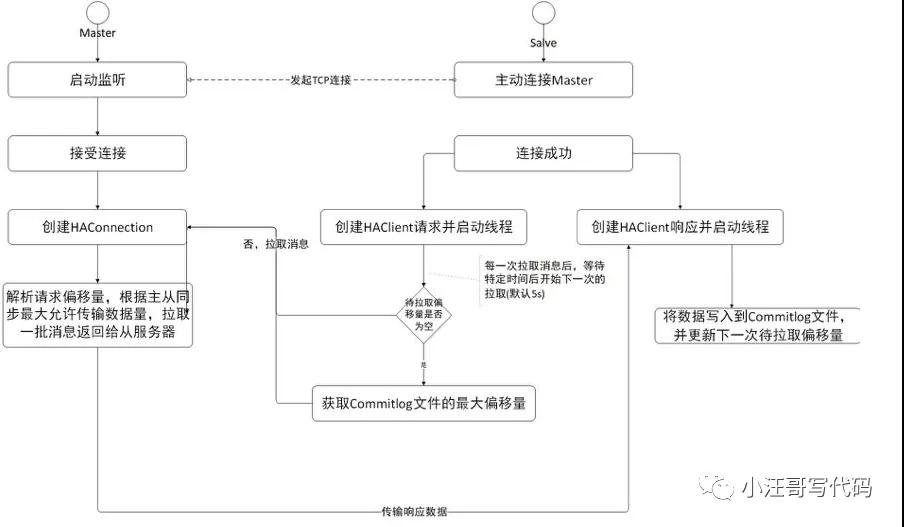
RocketMQ 的主從同步機制如下:
1.首先啟動Master并在指定端口監聽;
2.客戶端啟動,主動連接Master,建立TCP連接;
3.客戶端以每隔5s的間隔時間向服務端拉取消息,如果是第一次拉取的話,先獲取本地commitlog文件中最大的偏移量,以該偏移量向服務端拉取消息;
4.服務端解析請求,并返回一批數據給客戶端;
5.客戶端收到一批消息后,將消息寫入本地commitlog文件中,然后向Master匯報拉取進度,并更新下一次待拉取偏移量;
6.然后重復第3步;
文件存儲的優化技術
RocketMQ存儲層采用的幾項優化技術方案在一定程度上可以減少PageCache的缺點帶來的影響,主要包括內存預分配,文件預熱和mlock系統調用。
【預先分配MappedFile】
在消息寫入過程中(調用CommitLog的putMessage()方法),CommitLog會先從MappedFileQueue隊列中獲取一個 MappedFile,如果沒有就新建一個。
RocketMQ中預分配MappedFile的設計非常巧妙,下次獲取時候直接返回就可以不用等待MappedFile創建分配所產生的時間延遲。
【文件預熱&&mlock系統調用】
(1)mlock系統調用:其可以將進程使用的部分或者全部的地址空間鎖定在物理內存中,防止其被交換到swap空間。對于RocketMQ這種的高吞吐量的分布式消息隊列來說,追求的是消息讀寫低延遲,那么肯定希望盡可能地多使用物理內存,提高數據讀寫訪問的操作效率。
(2)文件預熱:預熱的目的主要有兩點;第一點,由于僅分配內存并進行mlock系統調用后并不會為程序完全鎖定這些內存,因為其中的分頁可能是寫時復制的。因此,就有必要對每個內存頁面中寫入一個假的值。其中,RocketMQ是在創建并分配MappedFile的過程中,預先寫入一些隨機值至Mmap映射出的內存空間里。第二,調用Mmap進行內存映射后,OS只是建立虛擬內存地址至物理地址的映射表,而實際并沒有加載任何文件至內存中。程序要訪問數據時OS會檢查該部分的分頁是否已經在內存中,如果不在,則發出一次缺頁中斷。這里,可以想象下1G的CommitLog需要發生多少次缺頁中斷,才能使得對應的數據才能完全加載至物理內存中(ps:X86的Linux中一個標準頁面大小是4KB)?RocketMQ的做法是,在做Mmap內存映射的同時進行madvise系統調用,目的是使OS做一次內存映射后對應的文件數據盡可能多的預加載至內存中,從而達到內存預熱的效果。
本文轉載自微信公眾號「小汪哥寫代碼」,可以通過以下二維碼關注。轉載本文請聯系小汪哥寫代碼公眾號。