Yelp的實時流技術之四:流處理器PaaStorm
這是關于Yelp的實時流數據基礎設施系列文章的第四篇。這個系列會深度講解我們如何用“確保只有一次”的方式把MySQL數據庫中的改動實時地以流的方式傳輸出去,我們如何自動跟蹤表模式變化、如何處理和轉換流,以及最終如何把這些數據存儲到Redshift或Salesforce之類的數據倉庫中去。
在2010年時,Yelp開源了一個名叫MRJob的框架,是用來在AWS基礎設施上運行大MapReduce Job的。Yelp的工程師們用MRJob實現了很多功能,從廣告推送到翻譯,比比皆是。事實證明,MRJob是一個非常強大的工具,可以在我們當時豐富的數據集合上完成計算和聚集操作。
不幸的是,隨著使用MRJob的服務數量巨增,運行和調度任務開始變得越來越復雜。由于很多任務都是要依賴上游任務的,所以就要好好地安排整個系統的拓撲。MapReduce任務并不是用于實時處理的,所以任務的拓撲要每天調度一次。更糟的是,萬一上游的任務失敗了,下游的也會失敗,最終會輸出錯誤的結果。因此就要有非常專業的能力來判斷應該從哪個任務開始、以什么順序重新運行,最終輸出正確的結果。
愛思考的人就會問了:我們有沒有什么辦法來更高效地完成計算和轉換任務呢?我們還想支持一個復雜的數據流中不同數據轉換操作之間的依賴關系,尤其是要能優雅地處理模式改變及上游的故障。我們還希望系統能實時或者近實時地運行。這樣,系統就可以用于業務分析及指標監控。換句話說,我們需要的是一個流處理器。
Storm之類現成的計算系統本來也是非常不錯的。但由于許多主流的流處理框架對Python的支持都不太好,因此要把我們的其他后臺程序與Storm或者其他現有流處理系統結合起來就會非常痛苦。
我們***用的是Pyleus,這是一個讓開發者可以用Python處理和轉換數據的開源框架。Pyleus的底層仍然是使用Storm的,構建耗時比較久,運行得也慢。Twitter Heron宣布開源后,我們發現我們也碰上了許多他們碰到過的問題。Yelp自己有功能非常強大的用于部署服務的Platform-as-a-Service平臺PaasTA,相比之下我們更喜歡使用PaaSTA,而不是運行專用的Storm集群。
從2015年7月開始,有一幫工程師們開始研發一種新型的數據倉庫,也碰上了典型的擴展和性能問題。最開始時他們想用Pyleus來先清洗數據,再拷貝到Redshift上。后來他們意識到部署一整套Storm集群來運行些簡單的Python邏輯實在太沒必要了:用Yelp自己的運行服務的平臺去部署一套基于Python的流處理器就足夠了。我們的流處理器是基于Samza設計的,目的是提供一些簡單的接口,用一種“處理消息”的方法來做數據轉換。
工程師們在Hackathon 17上構建了運行在PyPy上的流處理器的原型,這樣PassStorm就誕生了。
這名字中有什么含義?
PaaStorm的名字其實是PaaSTA和Storm的組合。那PaaStorm到底是干什么的呢?要回答這個問題,咱們先看看數據管道的基本架構:
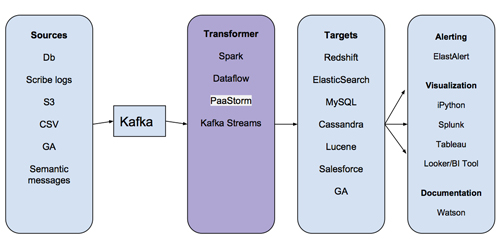
主要看看“Transformer”那一步,就會知道大多數存儲在Kafka中的消息都并不能直接被導入目標系統。設想有一套Redshift集群是用來存儲廣告推送數據的。廣告推送集群想存儲的只是上游系統的某一個字段(比如某個業務的平均權重),否則它就要保存原始數據并對其進行聚合計算。如果Redhift廣告推送集群要存儲所有上游數據的話,就會浪費存儲空間,導致系統性能降低。
在過去,各個服務都會寫復雜的MapReduce任務,在把數據寫到目標數據存儲之前先進行數據處理。可是,這些MapReduce任務都碰到了上文所述的性能和擴展問題。數據管道給大家提供的好處之一是消費者程序可以拿到它所需要的數據的形式,不管上游數據本來是什么樣。
減少示例代碼
本來我們是可以讓每個消費者程序自己按自己需要的方式做數據轉換的。比如,廣告推送系統可以自己寫一個轉換服務,從Kafka中的業務數據中提取出查看統計量,并自己維護這個轉換服務的。這種辦法最初工作得很好,但最終系統上規模時我們就碰上問題了。
我們想提供一個轉換框架是基于以下考慮:
很多轉換邏輯是通用的,可以在多個團隊之間共享。比如把標志位轉換成有意義的字段。
這樣的轉換邏輯通常會需要很多示例代碼。比如連接數據源或數據目的、保存狀態、監控吞吐量、故障恢復等。這樣的代碼本來并不需要在各種服務之間拷來拷去。
要保證能對數據進行實時處理的話,數據轉換操作要盡可能地快,要基于流。
減少示例代碼最自然的方式就是提供一個轉換接口。大家的服務實現接口中完成一次轉換操作的具體邏輯,然后,剩下的工作就由我們的流處理框架完成。
把Kafka作為消息總線
最初PaaStorm是一個Kafka-to-Kafka的轉換框架,慢慢地才演進成也支持了其他類型的終端節點。把Kafka做為PaaStorm的終端節點簡化了很多東西:每個對數據感興趣的服務都可以注冊到Topic上,關注任意轉換過的數據或者原始數據,有新消息到來就處理就好了,完全不必在意是誰創建了這個Topic。轉換過的數據按Kafka的保留策略持久化。因為Kafka是一個發布-訂閱系統,下游系統也可以在任何它想的時候消費數據。
用Storm處理一切
當采用了PaaStorm之后,我們該怎樣把我們的Kafka Topic之間的關系可視化呢?因為有些Topic中的數據會按照源到端的方式流向別的Topic,我們可以把我們的拓撲結構當成一個有向無環圖:
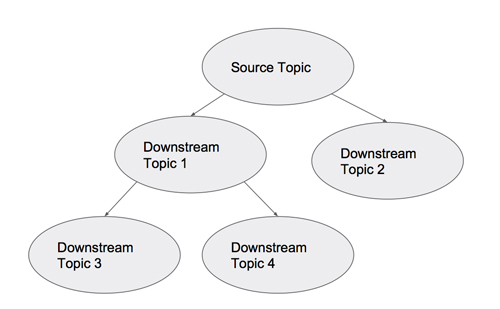
每個節點都是一個Kafka Topic,箭頭表示PaaStorm提供的轉換操作。這時候“PaaStorm”這個名字就變得更有意義了:象Storm一樣,PaaStorm通過轉換模塊(象Bolt一樣)提供對數據流的源(象Spout一樣)的實時轉換。
PaaStorm內部機制
PaaStorm的核心抽象叫做Spolt(Spout和Bolt的結合物)。象名字表示的一樣,Spolt接口也定義了兩個重要的東西:一個輸入數據源,一種對那個源的消息數據進行的某種處理。
下面例子定義了一個最簡單的Spolt:
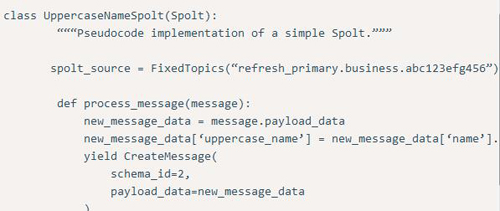
這個Spolt會處理“refresh_primary.business.abc123efg456”這個Topic中的每一條消息,增加一個字段,保存原始消息中的‘name’字段的大寫的值,然后再把這條處理過的新版本的消息發送出去。
值得一提的是數據管道中的所有消息都是不可修改的。要得到一條修改過的消息,就要創建一個新的對象。而且,因為我們在為消息體中增加一個新字段(就是那個增加的“大寫字母的name”字段),新消息的模式已經改變了。在生產環境中,消息的模式ID是從來都不能寫死的。我們要依靠Schematizer服務來為一條修改過的消息注冊并提供合適的模式。
***提一句,數據管道的客戶端庫提供了好幾種非常相似的用名字空間、Topic名、源名和模式ID的組合來生成“spolt_source”的方法。這樣就可以很容易地讓某個Spolt去找到它需要的所有源并從中讀取數據。
與Kafka相關的處理是怎樣的?
也許你已經發現上面的Spolt中沒有什么代碼是與Kafka Topic相交互的。這是因為在PaaStorm中,所有真正的Kafka接口相關處理都是由一個內部實例(恰好也叫PaaStorm)完成的。PaaStorm實例會把一個特定的Spolt與對應的源和目的關聯起來,并把消息送給Spolt處理,再把Spolt輸出的消息發布到正確的Topic上去。
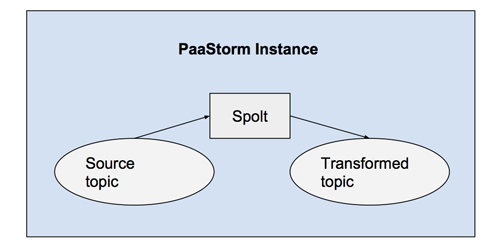
每個PaaStorm實例都用一個Spolt初始化。比如,下面的命令就用上文中定義的UppercaseNameSpolt開啟了一次處理:
PaaStorm(UppercaseNameSpolt()).start()
這就意味著所有有意寫一個新轉換器的人都可以簡單地定義一個新的Spolt子類,壓根不用修改任何PaaStorm運行體相關的東西。
從內部來看,PaaStorm運行體的主方法也是驚人的簡單,偽碼如下:

這個運行體先做了一些設置:初始化了生產者和消費者,以及消息計數器。然后,它一直等待上游Topic中的新數據。如果有新數據到來,就用Spolt處理它。Spolt處理之后會輸出一條或多條消息,生產者再把它發布到下游的Topic。
另外簡單提一下,PaaStorm運行體也提供了比如消費者注冊、心跳機制(名叫“tick”)等。比如某個Spolt要經常性地清空它的內容,那就可以用tick來觸發。
關于狀態保存
PaaStorm保證可以可靠地從故障中恢復。萬一發生了崩潰,我們就該從正確的偏移位置開始重新消費。但不幸的是,這個正確的偏移量一般情況下都并不是我們從上游的Topic中消費的***那一條消息。原因是雖然我們已經消費了它,但事實上我們還沒來得及把轉換后的版本發布出去。
所以重新啟動時正確的位置應該是上游Topic與已經成功發布到下游的***一條消息對應的位置。在知道發到下游的***一條消息的情況之后,我們需要知道它對應的上游的消息是哪一條,這樣就可以從那里恢復了。
為了方便實現這個功能,PaaStorm的Spolt在處理一條原始消息時,會把與這條原始消息相對應的在上游Topic中的Kafka偏移量也加到轉換后的包里。轉換后的消息隨后會在生產者的回調函數中把這個偏移量傳回來。這樣,我們就可以知道與下游Topic中***一條消息對應的上游Topic的偏移量了。因為回調函數只有在生產者成功地把轉換后的消息發布出去之后才會調用,也就意味著原始消息已經被成功處理了,在這種情況下,消費者就可以很放心的在那個回調函數中提交這個偏移量了。萬一發生崩潰,我們可以直接從還沒有被完全處理的上游消息那里開始繼續處理。
從上面的偽碼中可以看到,PaaStorm也會統計消費掉的消息數和發布的消息數。這樣,感興趣的用戶可以檢查上游和下游Topic中的吞吐量。這讓我們很輕松地有了對任意轉換操作的監控和性能檢查功能。在Yelp,我們是把我們的統計信息發給SignalFX的:
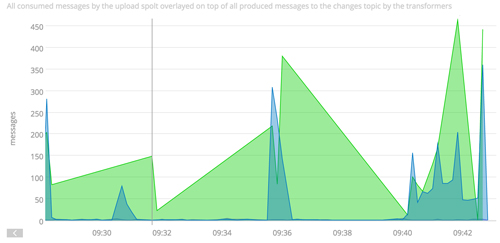
SignalFX圖可以顯示出在一個PaaStorm實例中生產者和消費者的吞吐量。在這個例子中,輸入輸出消息量并不匹配。
在PaaStorm中對生產者和消費者分開做統計的好處之一是我們可以把這兩個吞吐量放在一起,看看瓶頸是在哪里。如果到不了這個粒度,是很難發現管道中的性能問題的。
PaaStorm的未來
PaaStorm提供了兩個東西:一個接口,并實現了一套框架來支持這個接口。盡管我們并不希望PaaStorm的接口很快就被改動,但已經有一些孵化項目在計劃解決“轉換并連接”的問題了。在將來,我們希望能把PaaStorm的內部換成Kafka Stream或者Apache Beam,主要的障礙是對Python的支持程度如何,我們尤其看重的是對終端節點的支持。總之,在有開源的Python流處理項目成熟之前,我們會一直把PaaStorm用下去。