深度學習框架Caffe源碼解析
相信社區中很多小伙伴和我一樣使用了很長時間的Caffe深度學習框架,也非常希望從代碼層次理解Caffe的實現從而實現新功能的定制。本文將從整體架構和底層實現的視角,對Caffe源碼進行解析。
Caffe總體架構
Caffe框架主要有五個組件,Blob,Solver,Net,Layer,Proto,其結構圖如下圖1所示。Solver負責深度網絡的訓練,每個Solver中包含一個訓練網絡對象和一個測試網絡對象。每個網絡則由若干個Layer構成。每個Layer的輸入和輸出Feature map表示為Input Blob和Output Blob。Blob是Caffe實際存儲數據的結構,是一個不定維的矩陣,在Caffe中一般用來表示一個拉直的四維矩陣,四個維度分別對應Batch Size(N),Feature Map的通道數(C),Feature Map高度(H)和寬度(W)。Proto則基于Google的Protobuf開源項目,是一種類似XML的數據交換格式,用戶只需要按格式定義對象的數據成員,可以在多種語言中實現對象的序列化與反序列化,在Caffe中用于網絡模型的結構定義、存儲和讀取。
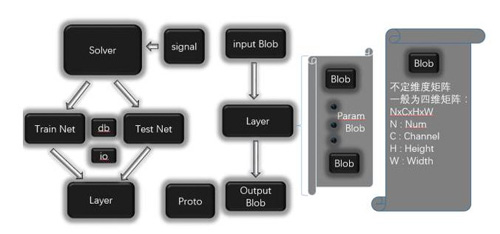
圖1 Caffe源碼總體架構圖
Blob解析
下面介紹Caffe中的基本數據存儲類Blob。Blob使用SyncedMemory類進行數據存儲,數據成員 data_指向實際存儲數據的內存或顯存塊,shape_存儲了當前blob的維度信息,diff_這個保存了反向傳遞時候的梯度信息。在Blob中其實不是只有num,channel,height,width這種四維形式,它是一個不定維度的數據結構,將數據展開存儲,而維度單獨存在一個vector 類型的shape_變量中,這樣每個維度都可以任意變化。
來一起看看Blob的關鍵函數,data_at這個函數可以讀取的存儲在此類中的數據,diff_at可以用來讀取反向傳回來的誤差。順便給個提示,盡量使用data_at(const vector& index)來查找數據。Reshape函數可以修改blob的存儲大小,count用來返回存儲數據的數量。BlobProto類負責了將Blob數據進行打包序列化到Caffe的模型中。
工廠模式說明
接下來介紹一種設計模式Factory Pattern,Caffe 中Solver和Layer對象的創建均使用了此模式,首先看工廠模式的UML的類圖:
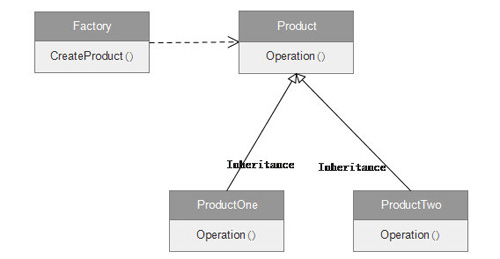
圖2 工廠模式UML類圖
如同Factory生成同一功能但是不同型號產品一樣,這些產品實現了同樣Operation,很多人看了工廠模式的代碼,會產生這樣的疑問為何不new一個出來呢,這樣new一個出來似乎也沒什么問題吧。試想如下情況,由于代碼重構類的名稱改了,或者構造函數參數變化(增加或減少參數)。而你代碼中又有N處new了這個類。如果你又沒用工廠,就只能一個一個找來改。工廠模式的作用就是讓使用者減少對產品本身的了解,降低使用難度。如果用工廠,只需要修改工廠類的創建具體對象方法的實現,而其他代碼不會受到影響。
舉個例子,寫代碼少不得餓了要加班去吃夜宵,麥當勞的雞翅和肯德基的雞翅都是MM愛吃的東西,雖然口味有所不同,但不管你帶MM去麥當勞或肯德基,只管向服務員說“來四個雞翅”就行了。麥當勞和肯德基就是生產雞翅的Factory。
Solver解析
接下來切回正題,我們看看Solver這個優化對象在Caffe中是如何實現的。SolverRegistry這個類就是我們看到的上面的factory類,負責給我們一個優化算法的產品,外部只需要把數據和網絡結構定義好,它就可以自己優化了。
Solver* CreateSolver(const SolverParameter& param)這個函數就是工廠模式下的CreateProduct的操作, Caffe中這個SolverRegistry工廠類可以提供給我們6種產品(優化算法):

這六種產品的功能都是實現網絡的參數更新,只是實現方式不一樣。那我們來看看他們的使用流程吧。當然這些產品類似上面Product類中的Operation,每一個Solver都會繼承Solve和Step函數,而每個Solver中獨有的僅僅是ApplyUpdate這個函數里面執行的內容不一樣,接口是一致的,這也和我們之前說的工廠生產出來的產品一樣功能一樣,細節上有差異,比如大多數電飯煲都有煮飯的功能,但是每一種電飯煲煮飯的加熱方式可能不同,有底盤加熱的還有立體加熱的等。接下里我們看看Solver中的關鍵函數。
Solver中Solve函數的流程圖如下:
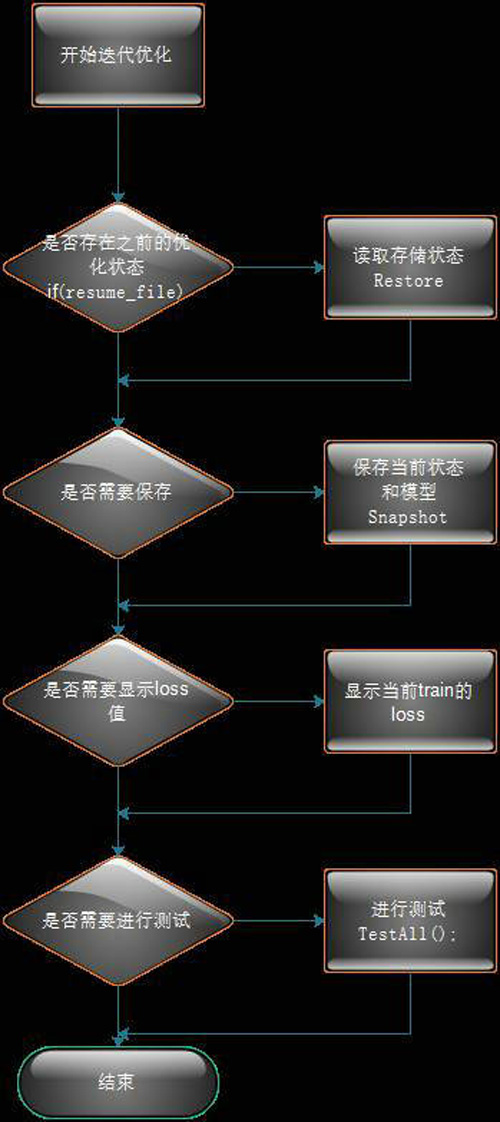
圖3 Solver類Solve方法流程圖
Solver類中Step函數流程圖:
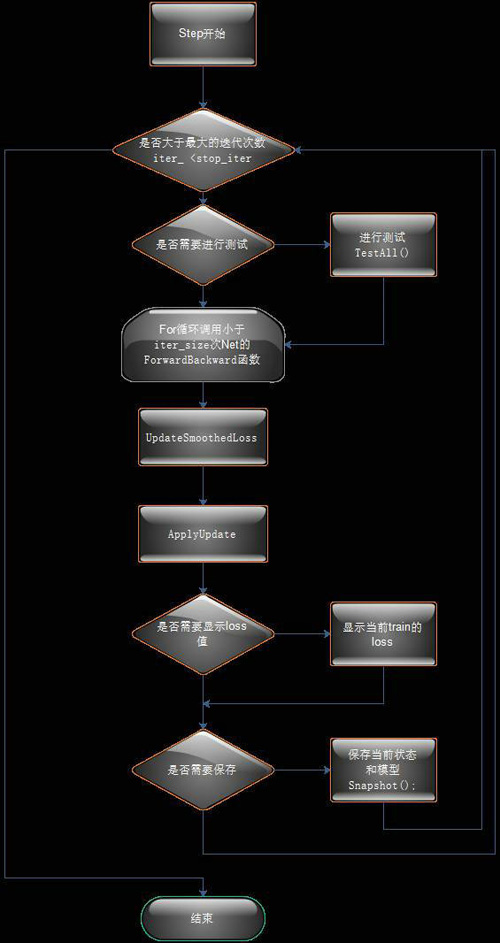
圖4 Solver類Step方法流程圖
Solver中關鍵的就是調用Sovle函數和Step函數的流程,你只需要對照Solver類中兩個函數的具體實現,看懂上面兩個流程圖就可以理解Caffe訓練執行的過程了。
Net類解析
分析過Solver之后我們來分析下Net類的一些關鍵操作。這個是我們使用Proto創建出來的深度網絡對象,這個類負責了深度網絡的前向和反向傳遞。以下是Net類的初始化方法NetInit函數調用流程:
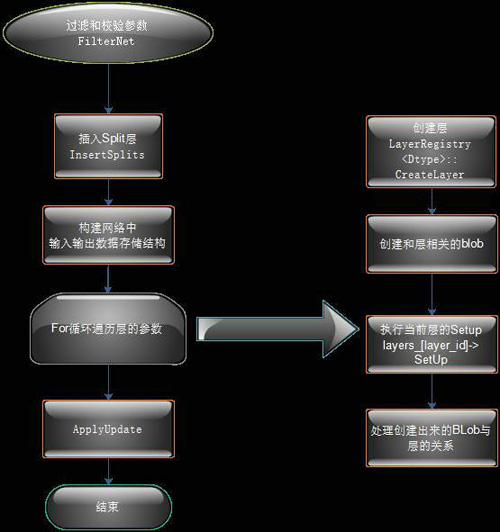
圖5 Net類NetInit方法流程圖
Net的類中的關鍵函數簡單剖析
• ForwardBackward:按順序調用了Forward和Backward。
• ForwardFromTo(int start, int end):執行從start層到end層的前向傳遞,采用簡單的for循環調用。
• BackwardFromTo(int start, int end):和前面的ForwardFromTo函數類似,調用從start層到end層的反向傳遞。
• ToProto函數完成網絡的序列化到文件,循環調用了每個層的ToProto函數。
Layer解析
Layer是Net的基本組成單元,例如一個卷積層或一個Pooling層。本小節將介紹Layer類的實現。
Layer的繼承結構
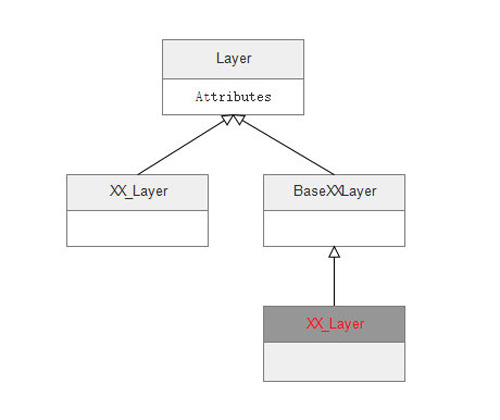
圖6 Layer層的繼承結構
Layer的創建
與Solver的創建方式很像,Layer的創建使用的也是工廠模式,這里簡單說明下幾個宏函數:
REGISTER_LAYER_CREATOR負責將創建層的函數放入LayerRegistry。
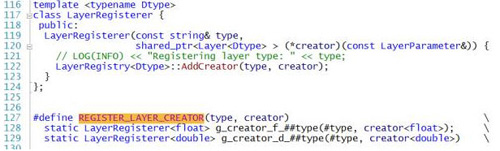
我們來看看大多數層創建的函數的生成宏REGISTER_LAYER_CLASS,可以看到宏函數比較簡單的,將類型作為函數名稱的一部分,這樣就可以產生出一個創建函數,并將創建函數放入LayerRegistry。

REGISTER_LAYER_CREATOR(type, Creator_##type##Layer)
這段代碼在split_layer.cpp文件中

REGISTER_LAYER_CLASS(Split)。
這樣我們將type替換過以后給大家做個范例,參考下面的代碼。

當然這里的創建函數好像是直接調用,沒有涉及到我們之前工廠模式的一些問題。所有的層的類都是這樣嗎?當然不是,我們仔細觀察卷積類。

卷積層怎么沒有創建函數呢,當然不是,卷積的層的創建函數在LayerFactory.cpp中,截圖給大家看下,具體代碼如下:

這樣兩種類型的Layer的創建函數都有了對應的聲明。這里直接說明除了有cudnn實現的層,其他層都是采用***種方式實現的創建函數,而帶有cudnn實現的層都采用的第二種方式實現的創建函數。
Layer的初始化
介紹完創建我們看看層里面的幾個函數都是什么時候被調用的。
關鍵函數Setup此函數在之前的流程圖中的NetInit時候被調用,代碼如下:

這樣整個Layer初始化的過程中,CheckBlobCounts被***調用,然后接下來是LayerSetUp,后面才是Reshape,***才是SetLossWeights。這樣Layer初始化的生命周期大家就有了了解。
Layer的其他函數的介紹
Layer的Forward函數和Backward函數完成了網絡的前向和反向傳遞,這兩個函數在自己實現新的層必須要實現。其中Backward會修改bottom中blob的diff_,這樣就完成了誤差的方向傳導。
Protobuf介紹
Caffe中的Caffe.proto文件負責了整個Caffe網絡的構建,又負責了Caffemodel的存儲和讀取。下面用一個例子介紹Protobuf的工作方式:
利用protobuffer工具存儲512維度圖像特征:
• message 編寫:新建txt文件后綴名改為proto,編寫自己的message如下,并放入解壓的protobuff的文件夾里;
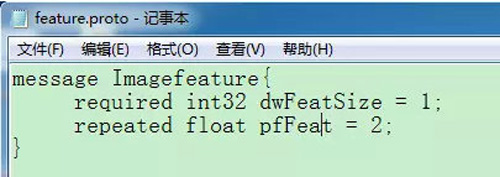
其中,dwFaceFeatSize表示特征點數量;pfFaceFeat表示人臉特征。
• 打開windows命令窗口(cmd.exe)—->cd空格,把protobuff的文件路徑復制粘貼進去——>enter;
• 輸入指令protoc *.proto –cpp_out=. ———>enter
• 可以看到文件夾里面生成“ .pb.h”和“.pb.cpp”兩個文件,說明成功了
![]()
• 下面可以和自己的代碼整合了:
• 新建你自己的工程,把“ .pb.h”和“.pb.cpp”兩個文件添加到自己的工程里,并寫上#include” *.pb.h”
• 按照配庫的教程把庫配置下就可以了
VS下Protobuf的配庫方法:
解決方案—->右擊工程名—->屬性
(1)c/c++—>常規—>附加包含目錄—>
($your protobuffer include path)\protobuffer
(2)c/c++—>鏈接器–>常規—>附加庫目錄–>
($your protobuffer lib path)\protobuffer
(3) c/c++—>鏈接器–>輸入—>附加依賴項–>
libprotobufd.lib;(帶d的為debug模式)
或libprotobuf.lib;(不帶d,為release模式)
使用protobuf進行打包的方法如下代碼:

Caffe的模型序列化
BlobProto其實就是Blob序列化成Proto的類,Caffe模型文件使用了該類。Net調用每個層的Toproto方法,每個層的Toproto方法調用了Blob類的ToProto方法,這樣完整的模型就被都序列化到proto里面了。***只要將這個proto繼承于message類的對象序列化到文件就完成了模型寫入文件。Caffe打包模型的時候就只是簡單調用了WriteProtoToBinaryFile這個函數,而這個函數里面的內容如下:

Proto.txt的簡單說明
Caffe網絡的構建和Solver的參數定義均由此類型文件完成。Net構建過程中調用ReadProtoFromTextFile將所有的網絡參數讀入。然后調用上面的流程進行整個caffe網絡的構建。這個文件決定了怎樣使用存在caffe model中的每個blob是用來做什么的,如果沒有了這個文件caffe的模型文件將無法使用,因為模型中只存儲了各種各樣的blob數據,里面只有float值,而怎樣切分這些數據是由prototxt文件決定的。
Caffe的架構在框架上采用了反射機制去動態創建層來構建Net,Protobuf本質上定義了graph,反射機制是由宏配合map結構形成的,然后使用工廠模式去實現各種各樣層的創建,當然區別于一般定義配置采用xml或者json,該項目的寫法采用了proto文件對組件進行組裝。
總結
以上為Caffe代碼架構的一個總體介紹,希望能借此幫助社區的小伙伴找到打開定制化Caffe大門的鑰匙。本文作者希望借此拋磚引玉,與更多期望了解Caffe和深度學習框架底層實現的同行交流。