數據科學家職位最常問的40道面試題
選文/校對 | 姚佳靈
翻譯 | 郭姝妤
導讀
想去機器學習初創公司做數據科學家?這些問題值得你三思!
機器學習和數據科學被看作是下一次工業革命的驅動器。這也意味著有許許多多令人激動的初創公司正在起步成長、尋找專業人士和數據科學家。它們可能是未來的特斯拉、谷歌。
對于有職業抱負的你來說,看好一家好的創業公司團隊后,如何能夠脫穎而出,進入一家靠譜的創業團隊呢?
想得到這樣的工作并不容易。首先你要強烈認同那個公司的理念、團隊和愿景。同時你可能會遇到一些很難的技術問題。而這些問題則取決于公司的業務。他們是咨詢公司?他們是做機器學習產品的?在準備面試之前就要了解清楚這些方面的問題。
為了幫你為今后的面試做準備,我準備了40道面試時可能碰到的棘手問題。如果你能回答和理解這些問題,那么放心吧,你能頑強抵抗住面試。
注意:要回答這些問題的關鍵是對機器學習和相關統計概念有具體的實際理解。
機器學習面試題

問1:給你一個有1000列和1百萬行的訓練數據集。這個數據集是基于分類問題的。經理要求你來降低該數據集的維度以減少模型計算時間。你的機器內存有限。你會怎么做?(你可以自由做各種實際操作假設。)
答:你的面試官應該非常了解很難在有限的內存上處理高維的數據。以下是你可以使用的處理方法:
1.由于我們的RAM很小,首先要關閉機器上正在運行的其他程序,包括網頁瀏覽器,以確保大部分內存可以使用。
2.我們可以隨機采樣數據集。這意味著,我們可以創建一個較小的數據集,比如有1000個變量和30萬行,然后做計算。
3.為了降低維度,我們可以把數值變量和分類變量分開,同時刪掉相關聯的變量。對于數值變量,我們將使用相關性分析。對于分類變量,我們可以用卡方檢驗。
4.另外,我們還可以使用PCA(主成分分析),并挑選可以解釋在數據集中有最大偏差的成分。
5.利用在線學習算法,如VowpalWabbit(在Python中可用)是一個可能的選擇。
6.利用Stochastic GradientDescent(隨機梯度下降)法建立線性模型也很有幫助。
7.我們也可以用我們對業務的理解來估計各預測變量對響應變量的影響大小。但是,這是一個主觀的方法,如果沒有找出有用的預測變量可能會導致信息的顯著丟失。
注意:對于第4和第5點,請務必閱讀有關在線學習算法和隨機梯度下降法的內容。這些是高階方法。
問2:在PCA中有必要做旋轉變換嗎?如果有必要,為什么?如果你沒有旋轉變換那些成分,會發生什么情況?
答:是的,旋轉(正交)是必要的,因為它把由主成分捕獲的方差之間的差異最大化。這使得主成分更容易解釋。但是不要忘記我們做PCA的目的是選擇更少的主成分(與特征變量個數相較而言),那些選上的主成分能夠解釋數據集中最大方差。通過做旋轉,各主成分的相對位置不發生變化,它只能改變點的實際坐標。如果我們沒有旋轉主成分,PCA的效果會減弱,那樣我們會不得不選擇更多個主成分來解釋數據集里的方差。
注意:對PCA(主成分分析)需要了解更多。
問3:給你一個數據集。這個數據集有缺失值,且這些缺失值分布在離中值有1個標準偏差的范圍內。百分之多少的數據不會受到影響?為什么?
答:這個問題給了你足夠的提示來開始思考!由于數據分布在中位數附近,讓我們先假設這是一個正態分布。我們知道,在一個正態分布中,約有68%的數據位于跟平均數(或眾數、中位數)1個標準差范圍內的,那樣剩下的約32%的數據是不受影響的。因此,約有32%的數據將不受到缺失值的影響。
問4:給你一個癌癥檢測的數據集。你已經建好了分類模型,取得了96%的精度。為什么你還是不滿意你的模型性能?你可以做些什么呢?
答:如果你分析過足夠多的數據集,你應該可以判斷出來癌癥檢測結果是不平衡數據。在不平衡數據集中,精度不應該被用來作為衡量模型的標準,因為96%(按給定的)可能只有正確預測多數分類,但我們感興趣是那些少數分類(4%),是那些被診斷出癌癥的人。因此,為了評價模型的性能,應該用靈敏度(真陽性率),特異性(真陰性率),F值用來確定這個分類器的“聰明”程度。如果在那4%的數據上表現不好,我們可以采取以下步驟:
1.我們可以使用欠采樣、過采樣或SMOTE讓數據平衡。
2.我們可以通過概率驗證和利用AUC-ROC曲線找到最佳閥值來調整預測閥值。
3.我們可以給分類分配權重,那樣較少的分類獲得較大的權重。
4.我們還可以使用異常檢測。
注意:要更多地了解不平衡分類
問5: 為什么樸素貝葉斯如此“樸素”?
答:樸素貝葉斯太‘樸素’了,因為它假定所有的特征在數據集中的作用是同樣重要和獨立的。正如我們所知,這個假設在現實世界中是很不真實的。
問6:解釋樸素貝葉斯算法里面的先驗概率、似然估計和邊際似然估計?
答:先驗概率就是因變量(二分法)在數據集中的比例。這是在你沒有任何進一步的信息的時候,是對分類能做出的最接近的猜測。例如,在一個數據集中,因變量是二進制的(1和0)。例如,1(垃圾郵件)的比例為70%和0(非垃圾郵件)的為30%。因此,我們可以估算出任何新的電子郵件有70%的概率被歸類為垃圾郵件。似然估計是在其他一些變量的給定的情況下,一個觀測值被分類為1的概率。例如,“FREE”這個詞在以前的垃圾郵件使用的概率就是似然估計。邊際似然估計就是,“FREE”這個詞在任何消息中使用的概率。
問7:你正在一個時間序列數據集上工作。經理要求你建立一個高精度的模型。你開始用決策樹算法,因為你知道它在所有類型數據上的表現都不錯。后來,你嘗試了時間序列回歸模型,并得到了比決策樹模型更高的精度。這種情況會發生嗎?為什么?
答:眾所周知,時間序列數據有線性關系。另一方面,決策樹算法是已知的檢測非線性交互最好的算法。為什么決策樹沒能提供好的預測的原因是它不能像回歸模型一樣做到對線性關系的那么好的映射。因此,我們知道了如果我們有一個滿足線性假設的數據集,一個線性回歸模型能提供強大的預測。
問8:給你分配了一個新的項目,是關于幫助食品配送公司節省更多的錢。問題是,公司的送餐隊伍沒辦法準時送餐。結果就是他們的客戶很不高興。最后為了使客戶高興,他們只好以免餐費了事。哪個機器學習算法能拯救他們?
答:你的大腦里可能已經開始閃現各種機器學習的算法。但是等等!這樣的提問方式只是來測試你的機器學習基礎。這不是一個機器學習的問題,而是一個路徑優化問題。機器學習問題由三樣東西組成:
1.模式已經存在。
2.不能用數學方法解決(指數方程都不行)。
3.有相關的數據。
通過判斷以上三個因素來決定機器學習是不是個用來解決特定問題的工具。
問9:你意識到你的模型受到低偏差和高方差問題的困擾。應該使用哪種算法來解決問題呢?為什么?
答:低偏差意味著模型的預測值接近實際值。換句話說,該模型有足夠的靈活性,以模仿訓練數據的分布。貌似很好,但是別忘了,一個靈活的模型沒有泛化能力。這意味著,當這個模型用在對一個未曾見過的數據集進行測試的時候,它會令人很失望。在這種情況下,我們可以使用bagging算法(如隨機森林),以解決高方差問題。bagging算法把數據集分成重復隨機取樣形成的子集。然后,這些樣本利用單個學習算法生成一組模型。接著,利用投票(分類)或平均(回歸)把模型預測結合在一起。另外,為了應對大方差,我們可以:
1.使用正則化技術,懲罰更高的模型系數,從而降低了模型的復雜性。
2.使用可變重要性圖表中的前n個特征。可以用于當一個算法在數據集中的所有變量里很難尋找到有意義信號的時候。
問10:給你一個數據集。該數據集包含很多變量,你知道其中一些是高度相關的。經理要求你用PCA。你會先去掉相關的變量嗎?為什么?
答:你可能會說不,但是這有可能是不對的。丟棄相關變量會對PCA有實質性的影響,因為有相關變量的存在,由特定成分解釋的方差被放大。例如:在一個數據集有3個變量,其中有2個是相關的。如果在該數據集上用PCA,第一主成分的方差會是與其不相關變量的差異的兩倍。此外,加入相關的變量使PCA錯誤地提高那些變量的重要性,這是有誤導性的。
問11:花了幾個小時后,現在你急于建一個高精度的模型。結果,你建了5 個GBM (Gradient Boosted Models),想著boosting算法會顯示魔力。不幸的是,沒有一個模型比基準模型表現得更好。最后,你決定將這些模型結合到一起。盡管眾所周知,結合模型通常精度高,但你就很不幸運。你到底錯在哪里?
答:據我們所知,組合的學習模型是基于合并弱的學習模型來創造一個強大的學習模型的想法。但是,只有當各模型之間沒有相關性的時候組合起來后才比較強大。由于我們已經試了5個 GBM,但沒有提高精度,表明這些模型是相關的。具有相關性的模型的問題是,所有的模型提供相同的信息。例如:如果模型1把User1122歸類為 1,模型2和模型3很有可能會做有同樣分類,即使它的實際值應該是0,因此,只有弱相關的模型結合起來才會表現更好。
問12:KNN和KMEANS聚類(kmeans clustering)有什么不同?
答:不要被它們的名字里的“K”誤導。你應該知道,這兩種算法之間的根本區別是,KMEANS本質上是無監督學習而KNN是監督學習。KMEANS是聚類算法。KNN是分類(或回歸)算法。 KMEAN算法把一個數據集分割成簇,使得形成的簇是同構的,每個簇里的點相互靠近。該算法試圖維持這些簇之間有足夠的可分離性。由于無監督的性質,這些簇沒有任何標簽。NN算法嘗試基于其k(可以是任何數目)個周圍鄰居來對未標記的觀察進行分類。它也被稱為懶惰學習法,因為它涉及最小的模型訓練。因此,它不用訓練數據對未看見的數據集進行泛化。
問13:真陽性率和召回有什么關系?寫出方程式。
答:真陽性率=召回。是的,它們有相同的公式(TP / TP + FN)。
注意:要了解更多關于估值矩陣的知識。
問14:你建了一個多元回歸模型。你的模型R2為并不如你設想的好。為了改進,你去掉截距項,模型R的平方從0.3變為0.8。這是否可能?怎樣才能達到這個結果?
答:是的,這有可能。我們需要了解截距項在回歸模型里的意義。截距項顯示模型預測沒有任何自變量,比如平均預測。公式R² = 1 – ∑(y – y´)²/∑(y – ymean)²中的y´是預測值。 當有截距項時,R²值評估的是你的模型基于均值模型的表現。在沒有截距項(ymean)時,當分母很大時,該模型就沒有這樣的估值效果了,∑(y – y´)²/∑(y – ymean)²式的值會變得比實際的小,而R2會比實際值大。
問15:在分析了你的模型后,經理告訴你,你的模型有多重共線性。你會如何驗證他說的是真的?在不丟失任何信息的情況下,你還能建立一個更好的模型嗎?
答:要檢查多重共線性,我們可以創建一個相關矩陣,用以識別和除去那些具有75%以上相關性(決定閾值是主觀的)的變量。此外,我們可以計算VIF(方差膨脹因子)來檢查多重共線性的存在。 VIF值<= 4表明沒有多重共線性,而值> = 10意味著嚴重的多重共線性。此外,我們還可以用容差作為多重共線性的指標。但是,刪除相關的變量可能會導致信息的丟失。為了留住這些變量,我們可以使用懲罰回歸模型,如Ridge和Lasso回歸。我們還可以在相關變量里添加一些隨機噪聲,使得變量變得彼此不同。但是,增加噪音可能會影響預測的準確度,因此應謹慎使用這種方法。
注意:多了解關于回歸的知識。
問16:什么時候Ridge回歸優于Lasso回歸?
答:你可以引用ISLR的作者Hastie和Tibshirani的話,他們斷言在對少量變量有中等或大尺度的影響的時候用lasso回歸。在對多個變量只有小或中等尺度影響的時候,使用Ridge回歸。
從概念上講,我們可以說,Lasso回歸(L1)同時做變量選擇和參數收縮,而ridge回歸只做參數收縮,并最終在模型中包含所有的系數。在有相關變量時,ridge回歸可能是首選。此外,ridge回歸在用最小二乘估計有更高的偏差的情況下效果最好。因此,選擇合適的模型取決于我們的模型的目標。
注意:多了解關于ridge和lasso回歸的相關知識。
問17:全球平均溫度的上升導致世界各地的海盜數量減少。這是否意味著海盜的數量減少引起氣候變化?
答:看完這個問題后,你應該知道這是一個“因果關系和相關性”的經典案例。我們不能斷定海盜的數量減少是引起氣候變化的原因,因為可能有其他因素(潛伏或混雜因素)影響了這一現象。全球平均溫度和海盜數量之間有可能有相關性,但基于這些信息,我們不能說因為全球平均氣溫的上升而導致了海盜的消失。
注意:多了解關于因果關系和相關性的知識。
問18:如何在一個數據集上選擇重要的變量?給出解釋。
答:以下是你可以使用的選擇變量的方法:
1.選擇重要的變量之前除去相關變量
2.用線性回歸然后基于P值選擇變量
3.使用前向選擇,后向選擇,逐步選擇
4.使用隨機森林和Xgboost,然后畫出變量重要性圖
5.使用lasso回歸
6.測量可用的特征集的的信息增益,并相應地選擇前n個特征量。
問19:協方差和相關性有什么區別?
答:相關性是協方差的標準化格式。協方差本身很難做比較。例如:如果我們計算工資($)和年齡(歲)的協方差,因為這兩個變量有不同的度量,所以我們會得到不能做比較的不同的協方差。為了解決這個問題,我們計算相關性來得到一個介于-1和1之間的值,就可以忽略它們各自不同的度量。
問20:是否有可能捕獲連續變量和分類變量之間的相關性?如果可以的話,怎樣做?
答:是的,我們可以用ANCOVA(協方差分析)技術來捕獲連續型變量和分類變量之間的相關性。
問21:Gradient boosting算法(GBM)和隨機森林都是基于樹的算法,它們有什么區別?
答:最根本的區別是,隨機森林算法使用bagging技術做出預測。 GBM采用boosting技術做預測。在bagging技術中,數據集用隨機采樣的方法被劃分成使n個樣本。然后,使用單一的學習算法,在所有樣本上建模。接著利用投票或者求平均來組合所得到的預測。Bagging是平行進行的。而boosting是在第一輪的預測之后,算法將分類出錯的預測加高權重,使得它們可以在后續一輪中得到校正。這種給予分類出錯的預測高權重的順序過程持續進行,一直到達到停止標準為止。隨機森林通過減少方差(主要方式)提高模型的精度。生成樹之間是不相關的,以把方差的減少最大化。在另一方面,GBM提高了精度,同時減少了模型的偏差和方差。
注意:多了解關于基于樹的建模知識。
問22:運行二元分類樹算法很容易,但是你知道一個樹是如何做分割的嗎,即樹如何決定把哪些變量分到哪個根節點和后續節點上?
答:分類樹利用基尼系數與節點熵來做決定。簡而言之,樹算法找到最好的可能特征,它可以將數據集分成最純的可能子節點。樹算法找到可以把數據集分成最純凈的可能的子節點的特征量。基尼系數是,如果總體是完全純的,那么我們從總體中隨機選擇2個樣本,而這2個樣本肯定是同一類的而且它們是同類的概率也是1。我們可以用以下方法計算基尼系數:
1.利用成功和失敗的概率的平方和(p^2+q^2)計算子節點的基尼系數
2.利用該分割的節點的加權基尼分數計算基尼系數以分割
熵是衡量信息不純的一個標準(二分類):
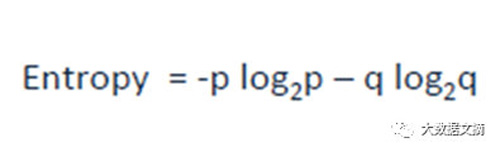
這里的p和q是分別在該節點成功和失敗的概率。當一個節點是均勻時熵為零。當2個類同時以50%對50%的概率出現在同一個節點上的時候,它是最大值。熵越低越好。
問23:你已經建了一個有10000棵樹的隨機森林模型。在得到0.00的訓練誤差后,你非常高興。但是,驗證錯誤是34.23。到底是怎么回事?你還沒有訓練好你的模型嗎?
答:該模型過度擬合。訓練誤差為0.00意味著分類器已在一定程度上模擬了訓練數據,這樣的分類器是不能用在未看見的數據上的。因此,當該分類器用于未看見的樣本上時,由于找不到已有的模式,就會返回的預測有很高的錯誤率。在隨機森林算法中,用了多于需求個數的樹時,這種情況會發生。因此,為了避免這些情況,我們要用交叉驗證來調整樹的數量。
問24:你有一個數據集,變量個數p大于觀察值個數n。為什么用OLS是一個不好的選擇?用什么技術最好?為什么?
答:在這樣的高維數據集中,我們不能用傳統的回歸技術,因為它們的假設往往不成立。當p>nN,我們不能計算唯一的最小二乘法系數估計,方差變成無窮大,因此OLS無法在此使用的。為了應對這種情況,我們可以使用懲罰回歸方法,如lasso、LARS、ridge,這些可以縮小系數以減少方差。準確地說,當最小二乘估計具有較高方差的時候,ridge回歸最有效。
其他方法還包括子集回歸、前向逐步回歸。
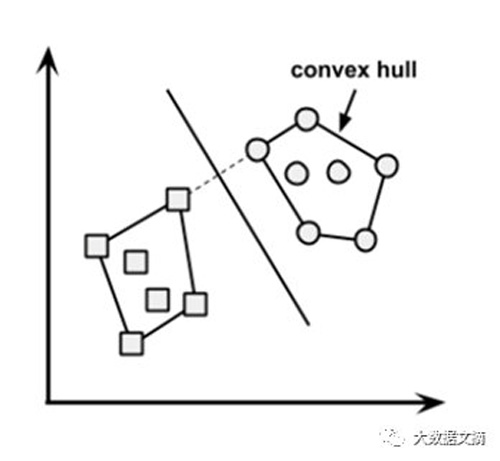
問25:什么是凸包?(提示:想一想SVM)
答:當數據是線性可分的,凸包就表示兩個組數據點的外邊界。一旦凸包建立,我們得到的最大間隔超平面(MMH)作為兩個凸包之間的垂直平分線。 MMH是能夠最大限度地分開兩個組的線。
問26:我們知道,一位有效編碼會增加數據集的維度。但是,標簽編碼不會。為什么?
答:對于這個問題不要太糾結。這只是在問這兩者之間的區別。
用一位有效編碼編碼,數據集的維度(也即特征)增加是因為它為分類變量中存在的的每一級都創建了一個變量。例如:假設我們有一個變量“顏色”。這變量有3個層級,即紅色、藍色和綠色。對“顏色”變量進行一位有效編碼會生成含0和1值的Color.Red,Color.Blue和Color.Green 三個新變量。在標簽編碼中,分類變量的層級編碼為0和1,因此不生成新變量。標簽編碼主要是用于二進制變量。
問27:你會在時間序列數據集上使用什么交叉驗證技術?是用k倍或LOOCV?
答:都不是。對于時間序列問題,k倍可能會很麻煩,因為第4年或第5年的一些模式有可能跟第3年的不同,而對數據集的重復采樣會將分離這些趨勢,我們可能最終是對過去幾年的驗證,這就不對了。相反,我們可以采用如下所示的5倍正向鏈接策略:
- fold 1 : training [1], test [2]
- fold 2 : training [1 2], test [3]
- fold 3 : training [1 2 3], test [4]
- fold 4 : training [1 2 3 4], test [5]
- fold 5 : training [1 2 3 4 5], test [6]
1,2,3,4,5,6代表的是年份。
問28:給你一個缺失值多于30%的數據集?比方說,在50個變量中,有8個變量的缺失值都多于30%。你對此如何處理?
答:我們可以用下面的方法來處理:
1.把缺失值分成單獨的一類,這些缺失值說不定會包含一些趨勢信息。
2.我們可以毫無顧忌地刪除它們。
3.或者,我們可以用目標變量來檢查它們的分布,如果發現任何模式,我們將保留那些缺失值并給它們一個新的分類,同時刪除其他缺失值。
問29:“買了這個的客戶,也買了......”亞馬遜的建議是哪種算法的結果?
答:這種推薦引擎的基本想法來自于協同過濾。
協同過濾算法考慮用于推薦項目的“用戶行為”。它們利用的是其他用戶的購買行為和針對商品的交易歷史記錄、評分、選擇和購買信息。針對商品的其他用戶的行為和偏好用來推薦項目(商品)給新用戶。在這種情況下,項目(商品)的特征是未知的。
注意:了解更多關于推薦系統的知識。
問30:你怎么理解第一類和第二類錯誤?
答:第一類錯誤是當原假設為真時,我們卻拒絕了它,也被稱為“假陽性”。第二類錯誤是當原假設為是假時,我們接受了它,也被稱為“假陰性”。在混淆矩陣里,我們可以說,當我們把一個值歸為陽性(1)但其實它是陰性(0)時,發生第一類錯誤。而當我們把一個值歸為陰性(0)但其實它是陽性(1)時,發生了第二類錯誤。
問31:當你在解決一個分類問題時,出于驗證的目的,你已經將訓練集隨機抽樣地分成訓練集和驗證集。你對你的模型能在未看見的數據上有好的表現非常有信心,因為你的驗證精度高。但是,在得到很差的精度后,你大失所望。什么地方出了錯?
答:在做分類問題時,我們應該使用分層抽樣而不是隨機抽樣。隨機抽樣不考慮目標類別的比例。相反,分層抽樣有助于保持目標變量在所得分布樣本中的分布。
問32:你被要求基于R²、校正后的R²和容差對一個回歸模型做評估。你的標準會是什么?
答:容差(1 / VIF)是多重共線性的指標。它是一個預測變量中的方差的百分比指標,這個預測變量不能由其他預測變量來計算。容差值越大越好。相對于R²我們會用校正R²,因為只要增加變量數量,不管預測精度是否提高,R²都會變大。但是,如果有一個附加變量提高了模型的精度,則校正R²會變大,否則保持不變。很難給校正R²一個標準閾值,因為不同數據集會不同。例如:一個基因突變數據集可能會得到一個較低的校正R²但仍提供了相當不錯的預測,但相較于股票市場,較低的校正R²只能說明模型不好。
問33:在k-means或kNN,我們是用歐氏距離來計算最近的鄰居之間的距離。為什么不用曼哈頓距離?
答:我們不用曼哈頓距離,因為它只計算水平或垂直距離,有維度的限制。另一方面,歐式距離可用于任何空間的距離計算問題。因為,數據點可以存在于任何空間,歐氏距離是更可行的選擇。例如:想象一下國際象棋棋盤,象或車所做的移動是由曼哈頓距離計算的,因為它們是在各自的水平和垂直方向的運動。
問34:把我當成一個5歲的小孩來解釋機器學習。
答:很簡單。機器學習就像嬰兒學走路。每次他們摔倒,他們就學到(無知覺地)并且明白,他們的腿要伸直,而不能彎著。他們下一次再跌倒,摔疼了,摔哭了。但是,他們學會“不要用那種姿勢站著”。為了避免摔疼,他們更加努力嘗試。為了站穩,他們還扶著門或墻壁或者任何靠近他們的東西。這同樣也是一個機器如何在環境中學習和發展它的“直覺”的。
注意:這個面試問題只是想考查你是否有深入淺出地講解復雜概念的能力。
問35:我知道校正R²或者F值來是用來評估線性回歸模型的。那用什么來評估邏輯回歸模型?
答:我們可以使用下面的方法:
1.由于邏輯回歸是用來預測概率的,我們可以用AUC-ROC曲線以及混淆矩陣來確定其性能。
2.此外,在邏輯回歸中類似于校正R²的指標是AIC。AIC是對模型系數數量懲罰模型的擬合度量。因此,我們更偏愛有最小AIC的模型。
3.空偏差指的是只有截距項的模型預測的響應。數值越低,模型越好。殘余偏差表示由添加自變量的模型預測的響應。數值越低,模型越好。
了解更多關于邏輯回歸的知識。
問36:考慮到機器學習有這么多算法,給定一個數據集,你如何決定使用哪一個算法?
答:你應該說,機器學習算法的選擇完全取決于數據的類型。如果給定的一個數據集是線性的,線性回歸是最好的選擇。如果數據是圖像或者音頻,那么神經網絡可以構建一個穩健的模型。如果該數據是非線性互相作用的的,可以用boosting或bagging算法。如果業務需求是要構建一個可以部署的模型,我們可以用回歸或決策樹模型(容易解釋和說明),而不是黑盒算法如SVM,GBM等。總之,沒有一個一勞永逸的算法。我們必須有足夠的細心,去了解到底要用哪個算法。
問37:你認為把分類變量當成連續型變量會更得到一個更好的預測模型嗎?
回答:為了得到更好的預測,只有在分類變量在本質上是有序的情況下才可以被當做連續型變量來處理。
問38:什么時候正則化在機器學習中是有必要的?
答:當模型過度擬合或者欠擬合的時候,正則化是有必要的。這個技術引入了一個成本項,用于帶來目標函數的更多特征。因此,正則化是將許多變量的系數推向零,由此而降低成本項。這有助于降低模型的復雜度,使該模型可以在預測上(泛化)變得更好。
問39:你是怎么理解偏差方差的平衡?
答:從數學的角度來看,任何模型出現的誤差可以分為三個部分。以下是這三個部分:
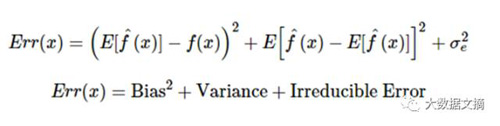
偏差誤差在量化平均水平之上預測值跟實際值相差多遠時有用。高偏差誤差意味著我們的模型表現不太好,因為沒有抓到重要的趨勢。而另一方面,方差量化了在同一個觀察上進行的預測是如何彼此不同的。高方差模型會過度擬合你的訓練集,而在訓練集以外的數據上表現很差。
問40:OLS是用于線性回歸。最大似然是用于邏輯回歸。解釋以上描述。
答:OLS和最大似然是使用各自的回歸方法來逼近未知參數(系數)值的方法。簡單地說,普通最小二乘法(OLS)是線性回歸中使用的方法,它是在實際值和預測值相差最小的情況下而得到這個參數的估計。最大似然性有助于選擇使參數最可能產生觀測數據的可能性最大化的參數值。
結語
看完以上所有的問題,真正的價值在于你能理解它們而且你從中學到的知識可以用于理解其他相似的問題。如果你對這些問題有疑問,不要擔心,現在正是學習的時候而不要急于表現。現在你應該專注學習這些問題。這些問題旨在讓你廣泛了解機器學習初創公司提出的問題類型。我相信這些問題會讓你感到好奇而讓你去做更深入的主題研究。如果你正在這么計劃,這是一個好兆頭。
文章來源:https://www.analyticsvidhya.com/blog/2016/09/40-interview-questions-asked-at-startups-in-machine-learning-data-science/?utm_source=feedburner&utm_medium=email&utm_campaign=Feed%3A+AnalyticsVidhya+%28Analytics+Vidhya%29
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】