深度學習框架TensorFlow在Kubernetes上的實踐
什么是深度學習?
深度學習這個名詞聽了很多次,它到底是什么東西,它背后的技術其實起源于神經網絡。神經網絡最早受到人類大腦工作原理的啟發,我們知道人的大腦是很復雜的結構,它可以被分為很多區域,比如聽覺中心、視覺中心,我在讀研究中心的時候,做視頻有計算機視覺研究室,做語言有語言所,語音有語音所,不同的功能在學科劃分中已經分開了,這個和我們人類對大腦理解多多少少有一些關系。之后科學家發現人類大腦是一個通用的計算模型。
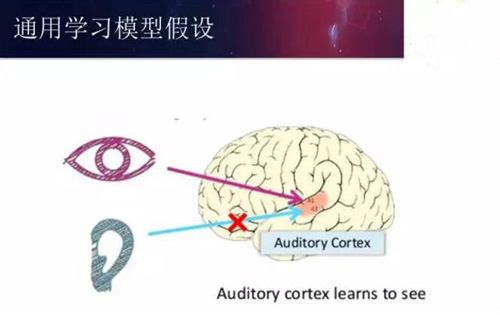
科學家做了這樣一個實驗,把小白鼠的聽覺中心的神經和耳朵通路剪斷,視覺輸入接到聽覺中心上,過了幾個月,小白鼠可以通過聽覺中心處理視覺信號。這就說明人類大腦工作原理是一樣的,神經元工作原理一樣,只是需要經過不斷的訓練。基于這樣的假設,神經學家做了這樣的嘗試,希望給盲人能夠帶來重新看到世界的希望,他們相當于是把電極接到舌頭上,通過攝像機把不同的像素傳到舌頭上,使得盲人有可能通過舌頭看到世界。對人類神經工作原理的進一步理解讓我們看到深度學習有望成為一種通用的學習模型。

上圖給出了神經網絡的大致結構。圖中左側是人類的神經元,右側是神經網絡的神經元。神經網絡的神經元最早受到了人類神經元結構的啟發,并試圖模型人類神經元的工作方式。具體的技術這里不做過深的討論。上圖中下側給出的是人類神經網絡和人工神經網絡(Artificial Neural Network)的對比,在計算機神經網絡中,我們需要明確的定義輸入層、輸出層。合理的利用人工神經網絡的輸入輸出就可以幫助我們解決實際的問題。
神經網絡最核心的工作原理,是要通過給定的輸入信號轉化為輸出信號,使得輸出信號能夠解決需要解決的問題。比如在完成文本分類問題時,我們需要將文章分為體育或者藝術。那么我們可以將文章中的單詞作為輸入提供給神經網絡,而輸出的節點就代表不同的種類。文章應該屬于哪一個種類,那么我們希望對應的輸出節點的輸出值為1,其他的輸出值為0。通過合理的設置神經網絡的結構和訓練神經網絡中的參數,訓練好的神經網絡模型就可以幫助我們判斷一篇文章應該屬于哪一個種類了。
深度學習在圖像識別中的應用
深度學習,它最初的應用,在于圖像識別。最經典的應用就是Imagenet的數據集。
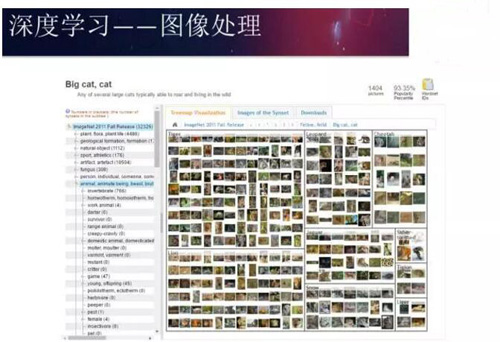
ImageNet是一個非常大的數據集,它里面有1500萬張圖片。下圖展示了數據集中一張樣例圖片。

在深度學習算法被應用之前,傳統的機器學習方法對圖像處理的能力有限。在2012年之前,***的機器學習算法能夠達到的錯誤率為25%,而且已經很難再有新的突破了。在2012年時,深度學習***被應用在在ImageNet數據集上,直接將錯誤率降低到了16%。在隨后的幾年中,隨著深度學習算法的改進,錯誤率一直降低到2016年的3.5%。在ImageNet數據集上,人類分類的錯誤率大概為5.1%。我們可以看到,機器的錯誤率比人的錯誤率更低,這是深度學習帶來的技術突破。
什么是TensorFlow
TensorFlow是谷歌在去年11月份開源出來的深度學習框架。開篇我們提到過AlphaGo,它的開發團隊DeepMind已經宣布之后的所有系統都將基于TensorFlow來實現。TensorFlow一款非常強大的開源深度學習開源工具。它可以支持手機端、CPU、GPU以及分布式集群。TensorFlow在學術界和工業界的應用都非常廣泛。在工業界,基于TensorFlow開發的谷歌翻譯、谷歌RankBrain等系統都已經上線。在學術界很多我在CMU、北大的同學都表示TensorFlow是他們實現深度學習算法的***工具。
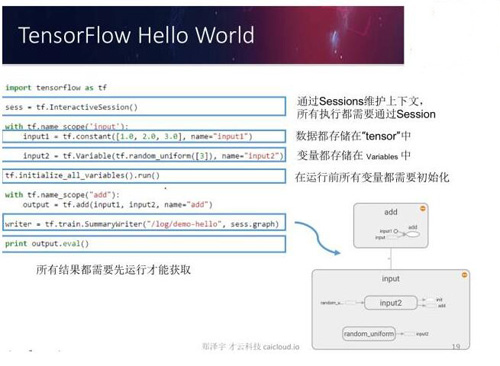
上面的ppt給出了一個簡單的TensorFlow程序樣例,這個樣例實現了向量加法的功能。TensorFlow提供了Python和C++的API,但Python的API更全面,所以大部分TensorFlow程序都是通過Python實現的。在上面程序的***行我們通過import將TensorFlow加載進來。在TensorFlow中所有的數據都是通過張量(Tensor)的方式存儲,要計算張量中數據的具體取值,我們需要通過一個會話(session)。
上面代碼中的第二行展示了如何生成會話。會話管理運行一個TensorFlow程序所需要的計算資源。TensorFlow中一個比較特殊的張量是變量(tf.Variable),在使用變量之前,我們需要明確調用變量初始化的過程。在上面的代碼***一行,我們可以看到要得到結果張量output的取值,我們需要明確調用計算張量取值的過程。

通過TensorFlow實現神經網絡是非常簡單的。通過TFLearn或者TensorFlow-Slim可以在10行之內實現MNIST手寫體數字識別問題。上面的ppt展示了TensorFlow對于不同神經網絡結構的支持,可以看出,TensorFlow可以在很短的代碼內支持各種主要的神經網絡結構。
雖然TensorFlow可以很快的實現神經網絡的功能,不過單機版的TensorFlow卻很難訓練大規模的深層神經網絡。

這張圖給出了谷歌在2015年提出的Inception-v3模型。這個模型在ImageNet數據集上可以達到95%的正確率。然而,這個模型中有2500萬個參數,分類一張圖片需要50億次加法或者乘法運算。即使只是使用這樣大規模的神經網絡已經需要非常大的計算量了,如果需要訓練深層神經網絡,那么需要更大的計算量。神經網絡的優化比較復雜,沒有直接的數學方法求解,需要反復迭代。在單機上要把Inception-v3模型訓練到78%的準確率大概需要5個多月的時間。如果要訓練到95%的正確率需要數年。這對于實際的生產環境是完全無法忍受的。
TensorFlow on Kubernetes
如我們上面所介紹的,在單機環境下是無法訓練大型的神經網絡的。在谷歌的內部,Google Brain以及TensorFlow都跑在谷歌內部的集群管理系統Borg上。我在谷歌電商時,我們使用的商品分類算法就跑在1千多臺服務器上。在谷歌外,我們可以將TensorFlow跑在Kubernetes上。在介紹如何將TensorFlow跑在Kubernetes上之前,我們先來介紹一下如何并行化的訓練深度學習的模型。
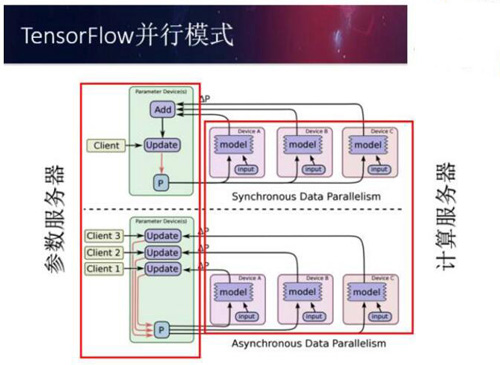
深度學習模型常用的有兩種分布式訓練方式。一種是同步更新,另一種是異步更新。如上面的ppt所示,在同步更新模式下,所有服務器都會統一讀取參數的取值,計算參數梯度,***再統一更新。而在異步更新模式下,不同服務器會自己讀取參數,計算梯度并更新參數,而不需要與其他服務器同步。同步更新的***問題在于,不同服務器需要同步完成所有操作,于是快的服務器需要等待慢的服務器,資源利用率會相對低一些。而異步模式可能會使用陳舊的梯度更新參數導致訓練的效果受到影響。不同的更新模式各有優缺點,很難統一的說哪一個更好,需要具體問題具體分析。
無論使用哪種更新方式,使用分布式TensorFlow訓練深度學習模型需要有兩種類型的服務器,一種是參數服務器,一種是計算服務器。參數服務器管理并保存神經網絡參數的取值;計算服務器負責計算參數的梯度。
在TensorFlow中啟動分布式深度學習模型訓練任務也有兩種模式。一種為In-graph replication。在這種模式下神經網絡的參數會都保存在同一個TensorFlow計算圖中,只有計算會分配到不同計算服務器。另一種為Between-graph replication,這種模式下所有的計算服務器也會創建參數,但參數會通過統一的方式分配到參數服務器。因為In-graph replication處理海量數據的能力稍弱,所以Between-graph replication是一個更加常用的模式。

***一個問題,我們剛剛提到TensorFlow是支持以分布式集群的方式運行的,那么為什么還需要Kubernetes?如果我們將TensorFlow和Hadoop系統做一個簡單的類比就可以很清楚的解釋這個問題。大家都知道Hadoop系統主要可以分為Yarn、HDFS和mapreduce計算框架,那么TensorFlow就相當于只是Hadoop系統中Mapreduce計算框架的部分。
TensorFlow沒有類似Yarn的調度系統,也沒有類似HDFS的存儲系統。這就是Kubernetes需要解決的部分。Kubernetes可以提供任務調度、監控、失敗重啟等功能。沒有這些功能,我們很難手工的去每一臺機器上啟動TensorFlow服務器并時時監控任務運行的狀態。除此之外,分布式TensorFlow目前不支持生命周期管理,結束的訓練進程并不會自動關閉,這也需要進行額外的處理。
鄭澤宇,谷歌高級工程師。從 2013 年加入谷歌至今,鄭澤宇作為主要技術人員參與并領導了多個大數據項目,擁有豐富機器學習、數據挖掘工業界及科研項目經驗。