擺好正確姿勢 看 Google 神級深度學(xué)習(xí)框架 TensorFlow 的實踐思路
原創(chuàng)在2015年11月9號Google發(fā)布了人工智能系統(tǒng)TensorFlow并宣布開源,此舉在深度學(xué)習(xí)領(lǐng)域影響巨大,也受到大量的深度學(xué)習(xí)開發(fā)者極大的關(guān)注。當(dāng)然,對于人工智能這個領(lǐng)域,依然有不少質(zhì)疑的聲音,但不可否認(rèn)的是人工智能仍然是未來發(fā)展的趨勢。
而TensorFlow能夠在登陸GitHub的當(dāng)天就成為最受關(guān)注的項目,作為構(gòu)建深度學(xué)習(xí)模型的最佳方式、深度學(xué)習(xí)框架的領(lǐng)頭者,在發(fā)布當(dāng)周輕松獲得超過1萬個星數(shù)評級,這主要是因為Google在人工智能領(lǐng)域的研發(fā)成績斐然和神級的技術(shù)人才儲備。當(dāng)然還有一點是在圍棋上第一次打敗人類,然后升級版Master保持連續(xù)60盤不敗的AlphaGo,其強(qiáng)化學(xué)習(xí)的框架也是基于TensorFlow的高級API實現(xiàn)的。
TensorFlow: 為什么是它?
作為Goolge二代DL框架,使用數(shù)據(jù)流圖的形式進(jìn)行計算的TensorFlow已經(jīng)成為了機(jī)器學(xué)習(xí)、深度學(xué)習(xí)領(lǐng)域中最受歡迎的框架之一。自從發(fā)布以來,TensorFlow不斷在完善并增加新功能,并在今年的2月26號在Mountain View舉辦的首屆年度TensorFlow開發(fā)者峰會上正式發(fā)布了TensorFlow 1.0版本,其最大的亮點就是通過優(yōu)化模型達(dá)到最快的速度,且快到令人難以置信,更讓人想不到的是很多擁護(hù)者用TensorFlow 1.0的發(fā)布來定義AI的元年。
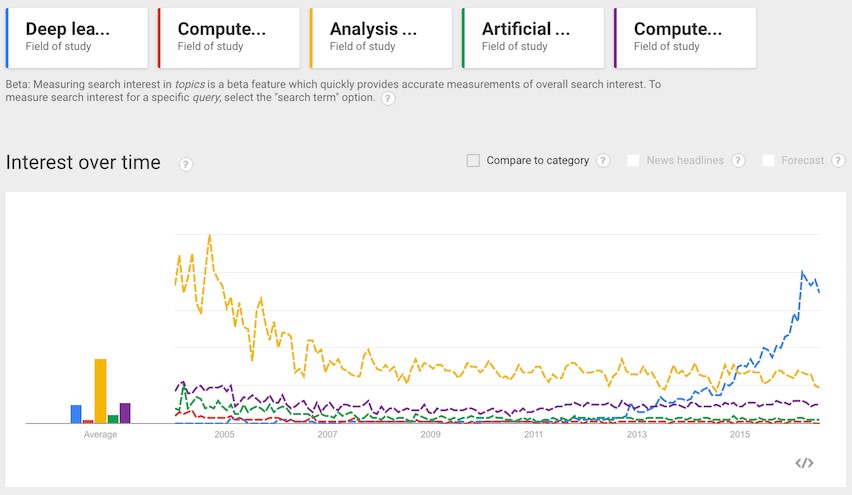
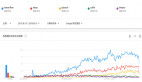
通過以上Google指數(shù),深度學(xué)習(xí)占據(jù)目前流程技術(shù)的第一位
TensorFlow在過去獲得成績主要有以下幾點:
|
Google第一代分布式機(jī)器學(xué)習(xí)框架DistBelief不再滿足Google內(nèi)部的需求,Google的小伙伴們在DistBelief基礎(chǔ)上做了重新設(shè)計,引入各種計算設(shè)備的支持包括CPU/GPU/TPU,以及能夠很好地運行在移動端,如安卓設(shè)備、ios、樹莓派 等等,支持多種不同的語言(因為各種high-level的api,訓(xùn)練僅支持Python,inference支持包括C++,Go,Java等等),另外包括像TensorBoard這類很棒的工具,能夠有效地提高深度學(xué)習(xí)研究工作者的效率。
TensorFlow在Google內(nèi)部項目應(yīng)用的增長也十分迅速:在Google多個產(chǎn)品都有應(yīng)用如:Gmail,Google Play Recommendation, Search, Translate, Map等等;有將近100多project和paper使用TensorFlow做相關(guān)工作。

TensorFlow在正式版發(fā)布前的過去14個月的時間內(nèi)也獲得了很多的成績,包括475+非Google的Contributors,14000+次commit,超過5500標(biāo)題中出現(xiàn)過TensorFlow的github project以及在Stack Overflow上有包括5000+個已被回答 的問題,平均每周80+的issue提交,且被一些頂尖的學(xué)術(shù)研究項目使用: – Neural Machine Translation – Neural Architecture Search – Show and Tell.
當(dāng)然了,說到底深度學(xué)習(xí)就是用非監(jiān)督式或者半監(jiān)督式的特征學(xué)習(xí),分層特征提取高校算法來替代手工獲取特征。目前研究人員和從事深度學(xué)習(xí)的開發(fā)者使用深度學(xué)習(xí)框架也并非只有TensorFlow一個,同樣也有很多在視覺、語言、自然語言處理和生物信息等領(lǐng)域較為優(yōu)秀的框架,比如Torch、Caffe、Theano、Deeplearning4j等。
下面,編者整理段石石博文中的一些對網(wǎng)絡(luò)神經(jīng)模型、算法深度分析的內(nèi)容,了解TensorFlow這個開源深度學(xué)習(xí)框架的強(qiáng)大之處。
深入理解Neural Style
這篇文章主要針對Tensorflow利用CNN的方法對藝術(shù)照片做下Neural Style的相關(guān)工作。首先,作者會詳細(xì)解釋下A Neural Algorithm of Artistic Style這篇paper是怎么做的,然后會結(jié)合一個開源的Tensorflow的Neural Style版本來領(lǐng)略下大神的風(fēng)采。
A Neural Algorithm of Artistic Style
在藝術(shù)領(lǐng)域,尤其是繪畫,藝術(shù)家們通過創(chuàng)造不同的內(nèi)容與風(fēng)格,并相互交融影響來創(chuàng)立獨立的視覺體驗。如果給定兩張圖像,現(xiàn)在的技術(shù)手段,完全有能力讓計算機(jī)識別出圖像具體內(nèi)容。而風(fēng)格是一種很抽象的東西,在計算機(jī)的眼中,當(dāng)然就是一些pixel,但人眼就能很有效地的辨別出不同畫家不同的style,是否有一些更復(fù)雜的feature來構(gòu)成,最開始學(xué)習(xí)DeepLearning的paper時,多層網(wǎng)絡(luò)的實質(zhì)其實就是找出更復(fù)雜、更內(nèi)在的features,所以圖像的style理論上可以通過多層網(wǎng)絡(luò)來提取里面可能一些有意思的東西。而這篇文章就是利用卷積神經(jīng)網(wǎng)絡(luò)(利用pretrain的Pre-trained VGG network model)來分別做Content、Style的reconstruction,在合成時考慮content loss 與style loss的最小化(其實還包括去噪變化的的loss),這樣合成出來的圖像會保證在content 和style的重構(gòu)上更準(zhǔn)確。

這里是整個paper在neural style的工作流,理解這幅圖對理解整篇paper的邏輯很關(guān)鍵,主要分為兩部分:
|
methods
理解了以上兩點,剩下的就是建模的數(shù)據(jù)問題了,這里按Content和Style來分別計算loss,Content loss的method比較簡單:
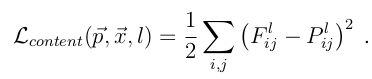
其中F^l是產(chǎn)生的Content Representation在第l層的數(shù)據(jù)表示,P^l是原始圖片在第l層的數(shù)據(jù)表示,定義squared-error loss為兩種特征表示的error。
Style的loss基本也和Content loss一樣,只不過要包含每一層輸出的errors之和
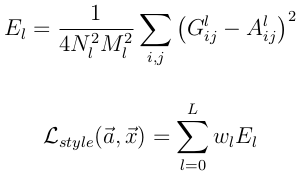
其中A^l 是原始style圖片在第l的數(shù)據(jù)表示,而G^l是產(chǎn)生的Style Representation在第l層的表示
定義好loss之后就是采用優(yōu)化方法來最小化模型loss(注意paper當(dāng)中只有content loss和style loss),源碼當(dāng)中還涉及到降噪的loss:
![]()
優(yōu)化方法這里就不講了,tensorflow有內(nèi)置的如Adam這樣的方法來處理。
深入理解AlexNet
前面看了一些Tensorflow的文檔和一些比較有意思的項目,發(fā)現(xiàn)這里面水很深的,需要多花時間好好從頭了解下,尤其是cv這塊的東西,特別感興趣,接下來一段時間會開始深入了解ImageNet比賽中中獲得好成績的那些模型: AlexNet、GoogLeNet、VGG(對就是之前在nerual network用的pretrained的model)、deep residual networks。
ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks 是Hinton和他的學(xué)生Alex Krizhevsky在12年ImageNet Challenge使用的模型結(jié)構(gòu),刷新了Image Classification的幾率,從此deep learning在Image這塊開始一次次超過state-of-art,甚至于搭到打敗人類的地步,看這邊文章的過程中,發(fā)現(xiàn)了很多以前零零散散看到的一些優(yōu)化技術(shù),但是很多沒有深入了解,這篇文章講解了他們alexnet如何做到能達(dá)到那么好的成績,好的廢話不多說,來開始看文章:
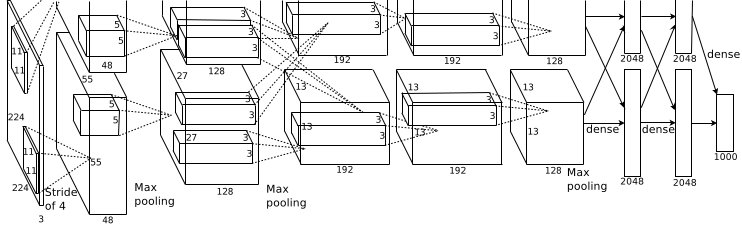
這張圖是基本的caffe中alexnet的網(wǎng)絡(luò)結(jié)構(gòu),這里比較抽象,作者用caffe的draw_net把a(bǔ)lexnet的網(wǎng)絡(luò)結(jié)構(gòu)畫出來了:
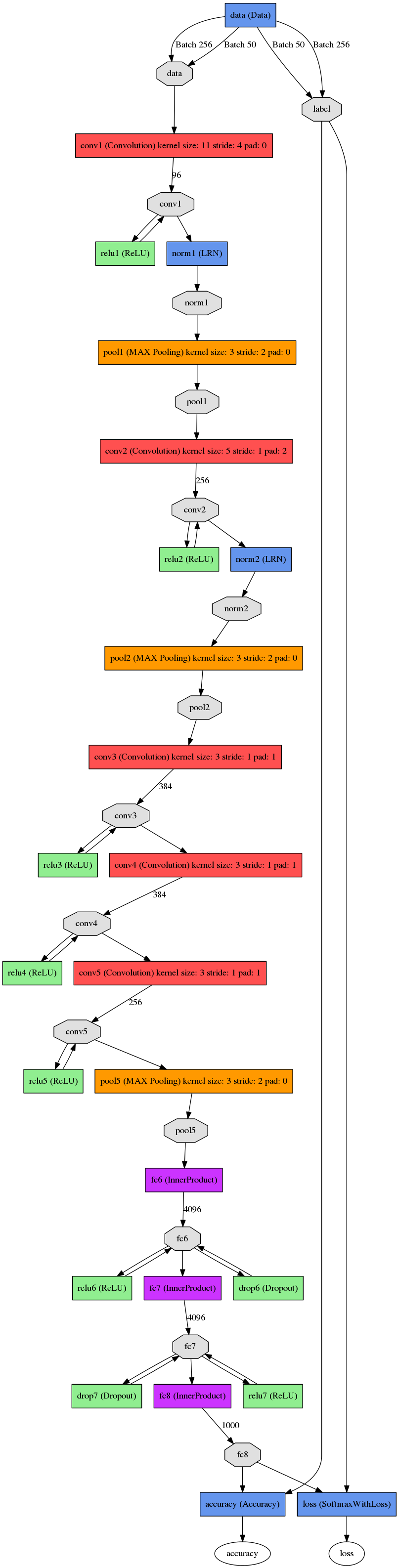
AlexNet的基本結(jié)構(gòu)
alexnet總共包括8層,其中前5層convolutional,后面3層是full-connected,文章里面說的是減少任何一個卷積結(jié)果會變得很差,下面具體講講每一層的構(gòu)成:
|
paper里面也指出了這張圖是在兩個GPU下做的,其中和caffe里面的alexnet可能還真有點差異,但這可能不是重點,各位在使用的時候,直接參考caffe中的alexnet的網(wǎng)絡(luò)結(jié)果,每一層都十分詳細(xì),基本的結(jié)構(gòu)理解和上面是一致的。
AlexNet為啥取得比較好的結(jié)果
前面講了下AlexNet的基本網(wǎng)絡(luò)結(jié)構(gòu),大家肯定會對其中的一些點產(chǎn)生疑問,比如LRN、Relu、dropout, 相信接觸過dl的小伙伴們都有聽說或者了解過這些。這里按paper中的描述詳細(xì)講述這些東西為什么能提高最終網(wǎng)絡(luò)的性能。
ReLU Nonlinearity
一般來說,剛接觸神經(jīng)網(wǎng)絡(luò)還沒有深入了解深度學(xué)習(xí)的小伙伴們對這個都不會太熟,一般都會更了解另外兩個激活函數(shù)(真正往神經(jīng)網(wǎng)絡(luò)中引入非線性關(guān)系,使神經(jīng)網(wǎng)絡(luò)能夠有效擬合非線性函數(shù))tanh(x)和(1+e^(-x))^(-1),而ReLU(Rectified Linear Units) f(x)=max(0,x)。基于ReLU的深度卷積網(wǎng)絡(luò)比基于tanh的網(wǎng)絡(luò)訓(xùn)練塊數(shù)倍,下圖是一個基于CIFAR-10的四層卷積網(wǎng)絡(luò)在tanh和ReLU達(dá)到25%的training error的迭代次數(shù):
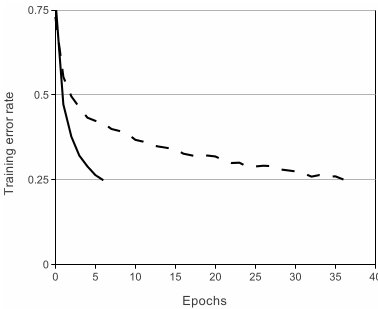
實線、間斷線分別代表的是ReLU、tanh的training error,可見ReLU比tanh能夠更快的收斂
Local Response Normalization
使用ReLU f(x)=max(0,x)后,你會發(fā)現(xiàn)激活函數(shù)之后的值沒有了tanh、sigmoid函數(shù)那樣有一個值域區(qū)間,所以一般在ReLU之后會做一個normalization,LRU就是文中提出(這里不確定,應(yīng)該是提出?)一種方法,在神經(jīng)科學(xué)中有個概念叫“Lateral inhibition”,講的是活躍的神經(jīng)元對它周邊神經(jīng)元的影響。
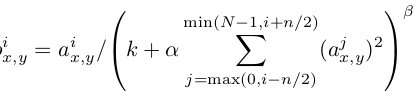
Dropout
Dropout也是經(jīng)常挺說的一個概念,能夠比較有效地防止神經(jīng)網(wǎng)絡(luò)的過擬合。 相對于一般如線性模型使用正則的方法來防止模型過擬合,而在神經(jīng)網(wǎng)絡(luò)中Dropout通過修改神經(jīng)網(wǎng)絡(luò)本身結(jié)構(gòu)來實現(xiàn)。對于某一層神經(jīng)元,通過定義的概率來隨機(jī)刪除一些神經(jīng)元,同時保持輸入層與輸出層神經(jīng)元的個人不變,然后按照神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)方法進(jìn)行參數(shù)更新,下一次迭代中,重新隨機(jī)刪除一些神經(jīng)元,直至訓(xùn)練結(jié)束
Data Augmentation
其實,最簡單的增強(qiáng)模型性能,防止模型過擬合的方法是增加數(shù)據(jù),但是其實增加數(shù)據(jù)也是有策略的,paper當(dāng)中從256*256中隨機(jī)提出227*227的patches(paper里面是224*224),還有就是通過PCA來擴(kuò)展數(shù)據(jù)集。這樣就很有效地擴(kuò)展了數(shù)據(jù)集,其實還有更多的方法視你的業(yè)務(wù)場景去使用,比如做基本的圖像轉(zhuǎn)換如增加減少亮度,一些濾光算法等等之類的,這是一種特別有效地手段,尤其是當(dāng)數(shù)據(jù)量不夠大的時候。
深度理解GoogLeNet
GoogLeNet是ILSVRC 2014的冠軍,主要是致敬經(jīng)典的LeNet-5算法,主要是Google的team成員完成,paper見Going Deeper with Convolutions.相關(guān)工作主要包括LeNet-5、Gabor filters、Network-in-Network.Network-in-Network改進(jìn)了傳統(tǒng)的CNN網(wǎng)絡(luò),采用少量的參數(shù)就輕松地?fù)魯×薃lexNet網(wǎng)絡(luò),使用Network-in-Network的模型最后大小約為29MNetwork-in-Network caffe model.GoogLeNet借鑒了Network-in-Network的思想,下面會詳細(xì)講述下。
1) Network-in-Network
左邊是CNN的線性卷積層,一般來說線性卷積層用來提取線性可分的特征,但所提取的特征高度非線性時,需要更加多的filters來提取各種潛在的特征,這樣就存在一個問題,filters太多,導(dǎo)致網(wǎng)絡(luò)參數(shù)太多,網(wǎng)絡(luò)過于復(fù)雜對于計算壓力太大。
文章主要從兩個方法來做了一些改良:
| 1,卷積層的改進(jìn):MLPconv,在每個local部分進(jìn)行比傳統(tǒng)卷積層復(fù)雜的計算,如上圖右,提高每一層卷積層對于復(fù)雜特征的識別能力,這里舉個不恰當(dāng)?shù)睦樱瑐鹘y(tǒng)的CNN網(wǎng)絡(luò),每一層的卷積層相當(dāng)于一個只會做單一任務(wù),你必須要增加海量的filters來達(dá)到完成特定量類型的任務(wù),而MLPconv的每層conv有更加大的能力,每一層能夠做多種不同類型的任務(wù),在選擇filters時只需要很少量的部分; 2,采用全局均值池化來解決傳統(tǒng)CNN網(wǎng)絡(luò)中最后全連接層參數(shù)過于復(fù)雜的特點,而且全連接會造成網(wǎng)絡(luò)的泛化能力差,Alexnet中有提高使用dropout來提高網(wǎng)絡(luò)的泛化能力。 |
最后作者設(shè)計了一個4層的Network-in-network+全局均值池化層來做imagenet的分類問題。
- class NiN(Network):
- def setup(self):
- (self.feed('data')
- .conv(11, 11, 96, 4, 4, padding='VALID', name='conv1')
- .conv(1, 1, 96, 1, 1, name='cccp1')
- .conv(1, 1, 96, 1, 1, name='cccp2')
- .max_pool(3, 3, 2, 2, name='pool1')
- .conv(5, 5, 256, 1, 1, name='conv2')
- .conv(1, 1, 256, 1, 1, name='cccp3')
- .conv(1, 1, 256, 1, 1, name='cccp4')
- .max_pool(3, 3, 2, 2, padding='VALID', name='pool2')
- .conv(3, 3, 384, 1, 1, name='conv3')
- .conv(1, 1, 384, 1, 1, name='cccp5')
- .conv(1, 1, 384, 1, 1, name='cccp6')
- .max_pool(3, 3, 2, 2, padding='VALID', name='pool3')
- .conv(3, 3, 1024, 1, 1, name='conv4-1024')
- .conv(1, 1, 1024, 1, 1, name='cccp7-1024')
- .conv(1, 1, 1000, 1, 1, name='cccp8-1024')
- .avg_pool(6, 6, 1, 1, padding='VALID', name='pool4')
- .softmax(name='prob'))
網(wǎng)絡(luò)基本結(jié)果如上,代碼見https://github.com/ethereon/caffe-tensorflow. 這里因為作者最近工作變動的問題,沒有了機(jī)器來跑一篇,也無法畫下基本的網(wǎng)絡(luò)結(jié)構(gòu)圖,之后會補(bǔ)上。這里指的提出的是中間cccp1和ccp2(cross channel pooling)等價于1*1kernel大小的卷積層。caffe中NIN的實現(xiàn)(略,請前往原文閱讀)
NIN的提出其實也可以認(rèn)為我們加深了網(wǎng)絡(luò)的深度,通過加深網(wǎng)絡(luò)深度(增加單個NIN的特征表示能力)以及將原先全連接層變?yōu)閍ver_pool層,大大減少了原先需要的filters數(shù),減少了model的參數(shù)。paper中實驗證明達(dá)到Alexnet相同的性能,最終model大小僅為29M。
理解NIN之后,再來看GoogLeNet就不會有不明所理的感覺。
痛點:
|
Inception module
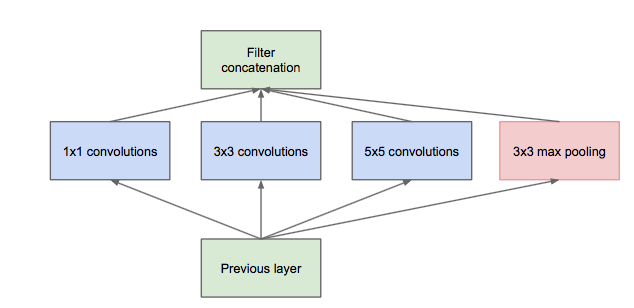
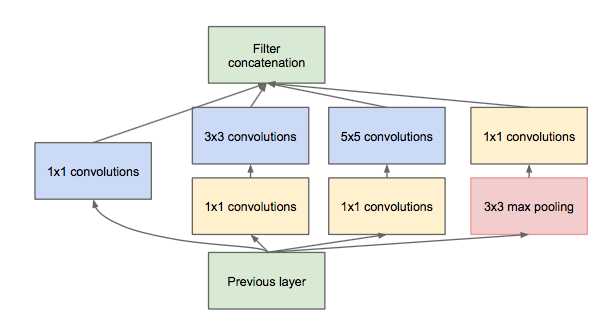
Inception module的提出主要考慮多個不同size的卷積核能夠hold圖像當(dāng)中不同cluster的信息,為方便計算,paper中分別使用1*1,3*3,5*5,同時加入3*3 max pooling模塊。 然而這里存在一個很大的計算隱患,每一層Inception module的輸出的filters將是分支所有filters數(shù)量的綜合,經(jīng)過多層之后,最終model的數(shù)量將會變得巨大,naive的inception會對計算資源有更大的依賴。 前面有提到Network-in-Network模型,1*1的模型能夠有效進(jìn)行降維(使用更少的來表達(dá)盡可能多的信息),所以文章提出了”Inception module with dimension reduction”,在不損失模型特征表示能力的前提下,盡量減少filters的數(shù)量,達(dá)到減少model復(fù)雜度的目的。
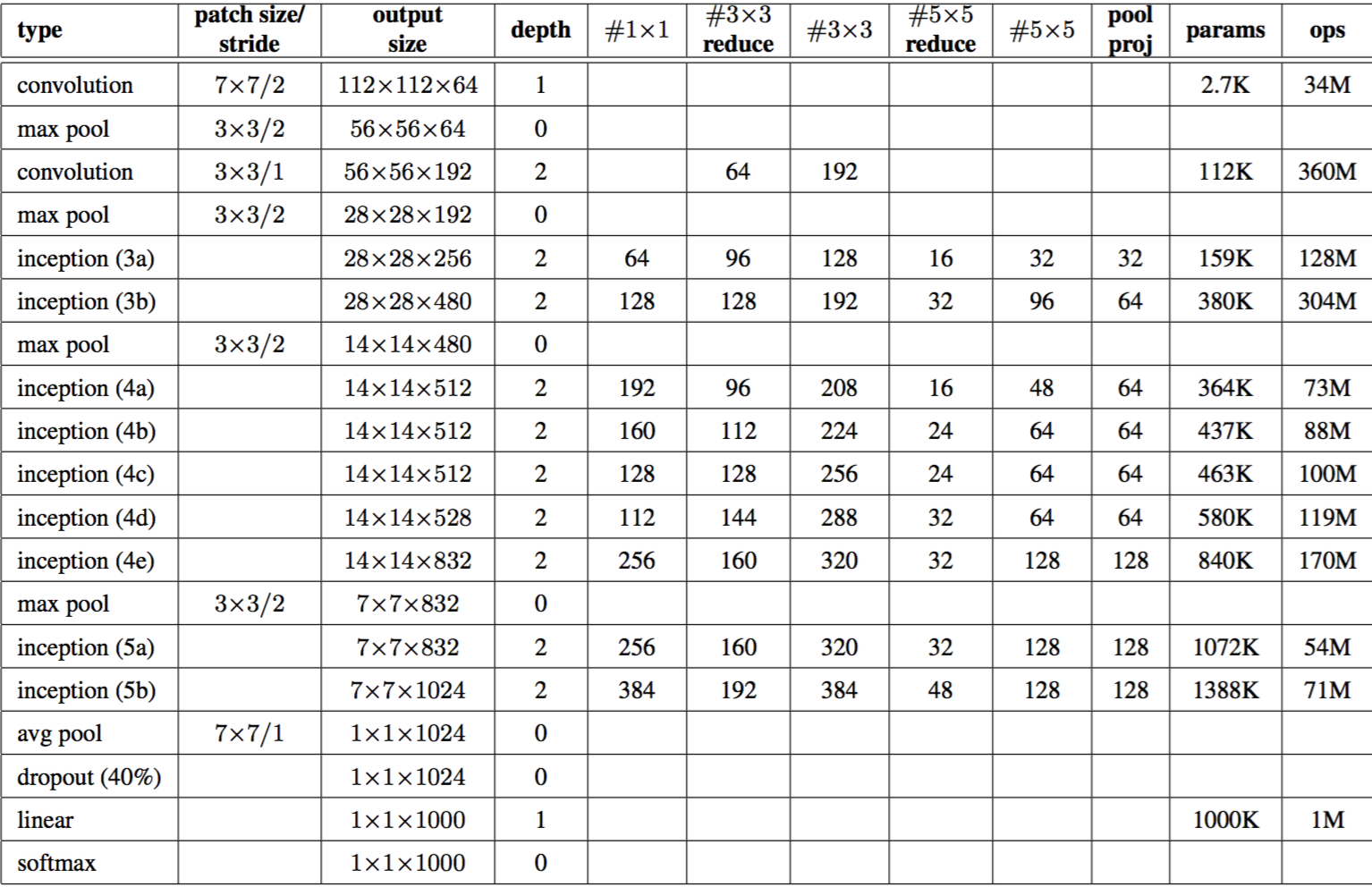
Overall of GoogLeNet
在tensorflow構(gòu)造GoogLeNet基本的代碼在https://github.com/ethereon/caffe-tensorflow中(如果懶得找,原文有展示),作者封裝了一些基本的操作,了解網(wǎng)絡(luò)結(jié)構(gòu)之后,構(gòu)造GoogLeNet很容易。之后等到新公司之后,作者會試著在tflearn的基礎(chǔ)上寫下GoogLeNet的網(wǎng)絡(luò)代碼。
GoogLeNet on Tensorflow
GoogLeNet為了實現(xiàn)方便,作者用tflearn來重寫了下,代碼中和caffe model里面不一樣的就是一些padding的位置,因為改的比較麻煩,必須保持inception部分的concat時要一致,這里也不知道怎么修改pad的值(caffe prototxt),所以統(tǒng)一padding設(shè)定為same,具體代碼(略,原文有展示)
大家如果感興趣,可以看看這部分的caffe model prototxt, 幫忙檢查下是否有問題,代碼作者已經(jīng)提交到tflearn的官方庫了,add GoogLeNet(Inception) in Example,各位有tensorflow的直接安裝下tflearn,看看是否能幫忙檢查下是否有問題,這里因為沒有GPU的機(jī)器,跑的比較慢,TensorBoard的圖如下,不像之前Alexnet那么明顯(主要還是沒有跑那么多epoch,這里在寫入的時候發(fā)現(xiàn)主機(jī)上沒有磁盤空間了,尷尬,然后從新寫了restore來跑的,TensorBoard的圖也貌似除了點問題, 好像每次載入都不太一樣,但是從基本的log里面的東西來看,是逐步在收斂的,這里圖也貼下看看吧)
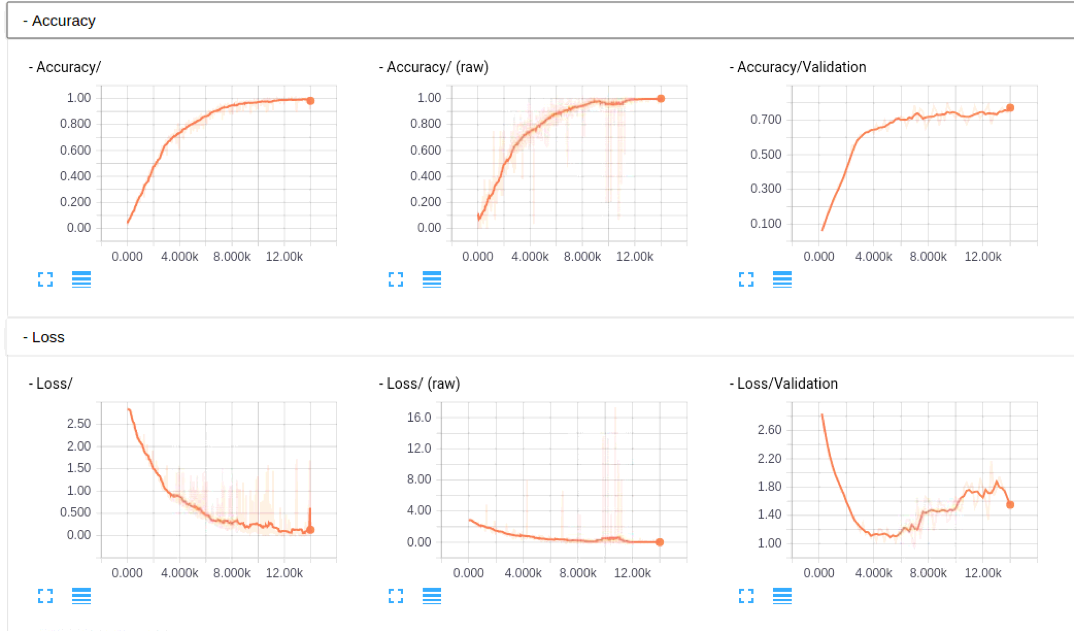
網(wǎng)絡(luò)結(jié)構(gòu),這里有個bug,可能是TensorBoard的,googlenet的graph可能是太大,大概是1.3m,在chrome上無法下載,試了火狐貌似可以了:

深入理解VGG\Residual Network
這段時間到了新公司,工作上開始研究DeepLearning以及TensorFlow,挺忙了,前段時間看了VGG和deep residual的paper,一直沒有時間寫,今天準(zhǔn)備好好把這兩篇相關(guān)的paper重讀下。
VGGnet
VGGnet是Oxford的Visual Geometry Group的team,在ILSVRC 2014上的相關(guān)工作,主要工作是證明了增加網(wǎng)絡(luò)的深度能夠在一定程度上影響網(wǎng)絡(luò)最終的性能,如下圖,文章通過逐步增加網(wǎng)絡(luò)深度來提高性能,雖然看起來有一點小暴力,沒有特別多取巧的,但是確實有效,很多pretrained的方法就是使用VGG的model(主要是16和19),VGG相對其他的方法,參數(shù)空間很大,最終的model有500多m,alnext只有200m,googlenet更少,所以train一個vgg模型通常要花費更長的時間,所幸有公開的pretrained model讓我們很方便的使用,前面neural style這篇文章就使用的pretrained的model,paper中的幾種模型如下:
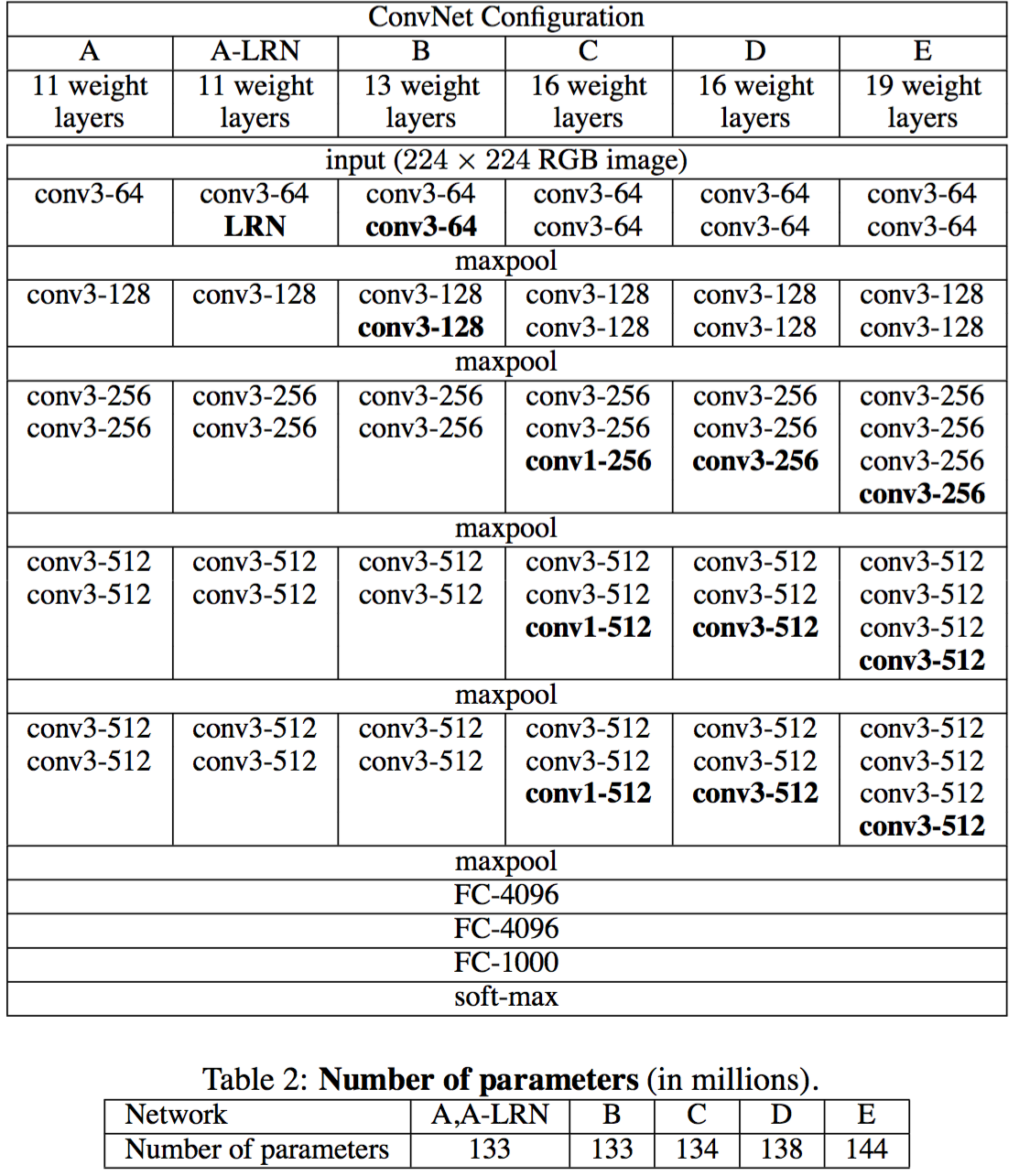
可以從圖中看出,從A到最后的E,他們增加的是每一個卷積組中的卷積層數(shù),最后D,E是我們常見的VGG-16,VGG-19模型,C中作者說明,在引入1*1是考慮做線性變換(這里channel一致, 不做降維),后面在最終數(shù)據(jù)的分析上來看C相對于B確實有一定程度的提升,但不如D、VGG主要得優(yōu)勢在于
|
VGG-16 tflearn實現(xiàn)
tflearn 官方github上有給出基于tflearn下的VGG-16的實現(xiàn) from future import division, print_function, absolute_import
- import tflearn
- from tflearn.layers.core import input_data, dropout, fully_connected
- from tflearn.layers.conv import conv_2d, max_pool_2d
- from tflearn.layers.estimator import regression
- # Data loading and preprocessing
- import tflearn.datasets.oxflower17 as oxflower17
- X, Y = oxflower17.load_data(one_hot=True)
- # Building 'VGG Network'
- network = input_data(shape=[None, 224, 224, 3])
- network = conv_2d(network, 64, 3, activation='relu')
- network = conv_2d(network, 64, 3, activation='relu')
- network = max_pool_2d(network, 2, strides=2)
- network = conv_2d(network, 128, 3, activation='relu')
- network = conv_2d(network, 128, 3, activation='relu')
- network = max_pool_2d(network, 2, strides=2)
- network = conv_2d(network, 256, 3, activation='relu')
- network = conv_2d(network, 256, 3, activation='relu')
- network = conv_2d(network, 256, 3, activation='relu')
- network = max_pool_2d(network, 2, strides=2)
- network = conv_2d(network, 512, 3, activation='relu')
- network = conv_2d(network, 512, 3, activation='relu')
- network = conv_2d(network, 512, 3, activation='relu')
- network = max_pool_2d(network, 2, strides=2)
- network = conv_2d(network, 512, 3, activation='relu')
- network = conv_2d(network, 512, 3, activation='relu')
- network = conv_2d(network, 512, 3, activation='relu')
- network = max_pool_2d(network, 2, strides=2)
- network = fully_connected(network, 4096, activation='relu')
- network = dropout(network, 0.5)
- network = fully_connected(network, 4096, activation='relu')
- network = dropout(network, 0.5)
- network = fully_connected(network, 17, activation='softmax')
- network = regression(network, optimizer='rmsprop',
- loss='categorical_crossentropy',
- learning_rate=0.001)
- # Training
- model = tflearn.DNN(network, checkpoint_path='model_vgg',
- max_checkpoints=1, tensorboard_verbose=0)
- model.fit(X, Y, n_epoch=500, shuffle=True,
- show_metric=True, batch_size=32, snapshot_step=500,
- snapshot_epoch=False, run_id='vgg_oxflowers17')
VGG-16 graph如下:
對VGG,作者個人覺得他的亮點不多,pre-trained的model我們可以很好的使用,但是不如GoogLeNet那樣讓人有眼前一亮的感覺。
Deep Residual Network
一般來說越深的網(wǎng)絡(luò),越難被訓(xùn)練,Deep Residual Learning for Image Recognition中提出一種residual learning的框架,能夠大大簡化模型網(wǎng)絡(luò)的訓(xùn)練時間,使得在可接受時間內(nèi),模型能夠更深(152甚至嘗試了1000),該方法在ILSVRC2015上取得最好的成績。
隨著模型深度的增加,會產(chǎn)生以下問題:
- vanishing/exploding gradient,導(dǎo)致了訓(xùn)練十分難收斂,這類問題能夠通過norimalized initialization 和intermediate normalization layers解決;
- 對合適的額深度模型再次增加層數(shù),模型準(zhǔn)確率會迅速下滑(不是overfit造成),training error和test error都會很高,相應(yīng)的現(xiàn)象在CIFAR-10和ImageNet都有提及
為了解決因深度增加而產(chǎn)生的性能下降問題,作者提出下面一種結(jié)構(gòu)來做residual learning:
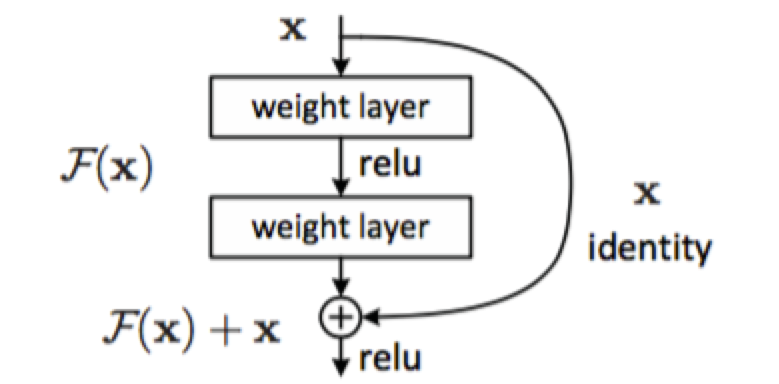
假設(shè)潛在映射為H(x),使stacked nonlinear layers去擬合F(x):=H(x)-x,殘差優(yōu)化比優(yōu)化H(x)更容易。 F(x)+x能夠很容易通過”shortcut connections”來實現(xiàn)。
這篇文章主要得改善就是對傳統(tǒng)的卷積模型增加residual learning,通過殘差優(yōu)化來找到近似最優(yōu)identity mappings。
paper當(dāng)中的一個網(wǎng)絡(luò)結(jié)構(gòu):
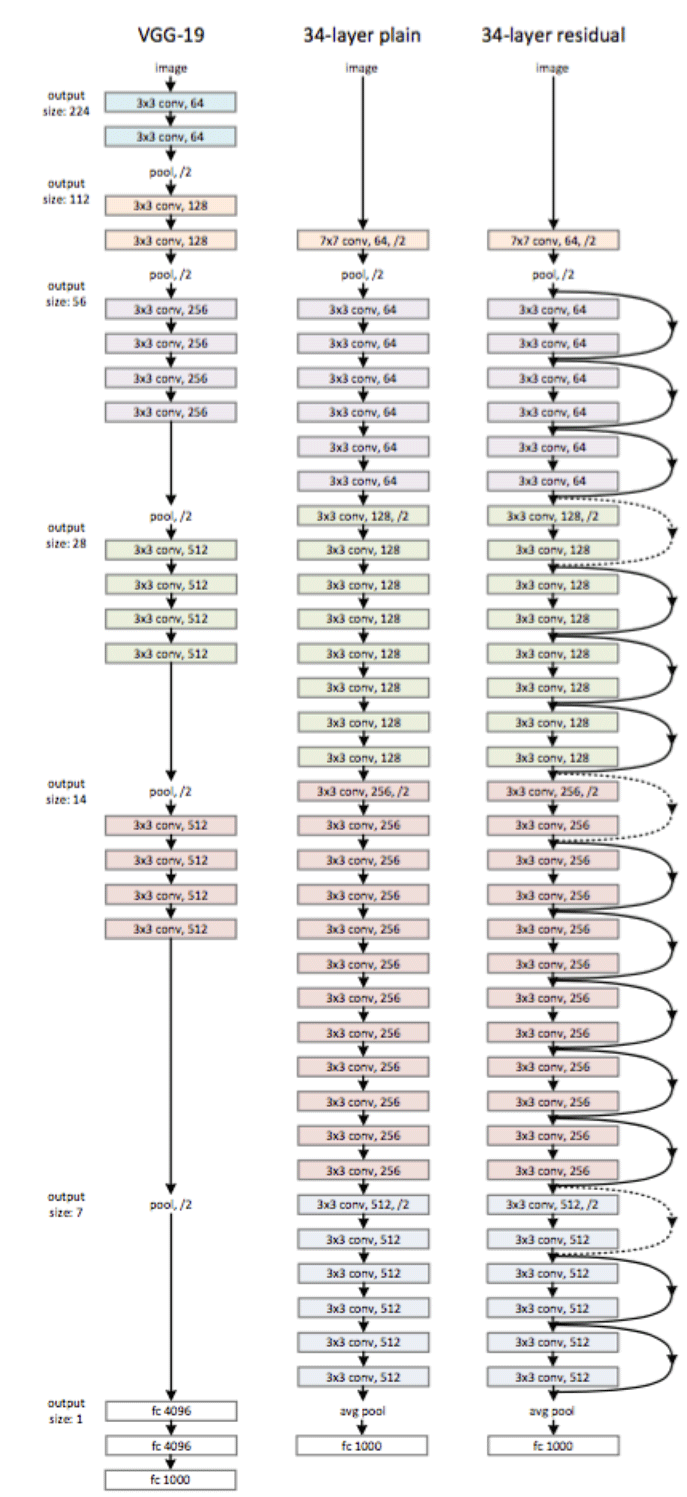
Deep Residual Network tflearn實現(xiàn)原文里面有詳細(xì)的介紹。
理解Fast Neural Style
前面幾篇文章講述了在Computer Vision領(lǐng)域里面常用的模型,接下來一段時間,作者會花精力來學(xué)習(xí)一些TensorFlow在Computer Vision領(lǐng)域的應(yīng)用,主要是分析相關(guān)pape和源碼,今天會來詳細(xì)了解下fast neural style的相關(guān)工作,前面也有文章分析neural style的內(nèi)容,那篇算是neural style的起源,但是無法應(yīng)用到實際工作上,為啥呢?它每次都需要指定好content image和style image,然后最小化content loss 和style loss去生成圖像,時間花銷很大,而且無法保存某種風(fēng)格的model,所以每次生成圖像都是訓(xùn)練一個model的過程,而fast neural style中能夠?qū)⒂?xùn)練好的某種style的image的模型保存下來,然后對content image 進(jìn)行transform,當(dāng)然文中還提到了image transform的另一個應(yīng)用方向:Super-Resolution,利用深度學(xué)習(xí)的技術(shù)將低分辨率的圖像轉(zhuǎn)換為高分辨率圖像,現(xiàn)在在很多大型的互聯(lián)網(wǎng)公司,尤其是視頻網(wǎng)站上也有應(yīng)用。
Paper原理
幾個月前,就看了Neural Style相關(guān)的文章TensorFlow之深入理解Neural Style,A Neural Algorithm of Aritistic Style中構(gòu)造了一個多層的卷積網(wǎng)絡(luò),通過最小化定義的content loss和style loss最后生成一個結(jié)合了content和style的圖像,很有意思,而Perceptual Losses for Real-Time Style Transfer and Super-Resolution,通過使用perceptual loss來替代per-pixels loss使用pre-trained的vgg model來簡化原先的loss計算,增加一個transform Network,直接生成Content image的style版本, 如何實現(xiàn)的呢,請看下圖:
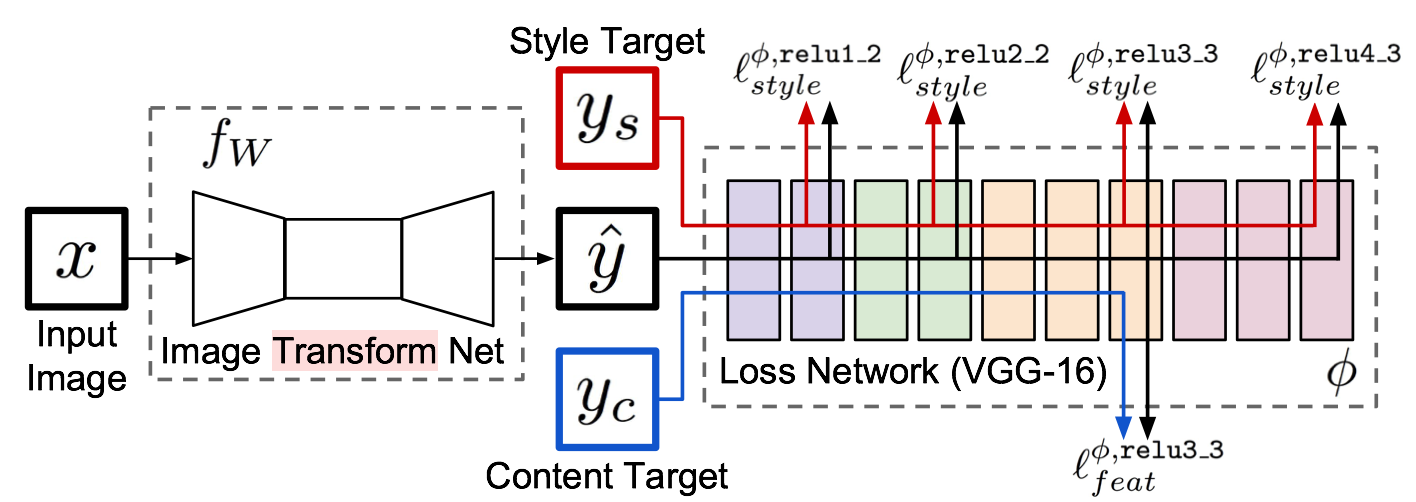
整個網(wǎng)絡(luò)是由部分組成:image transformation network、 loss netwrok;Image Transformation network是一個deep residual conv netwrok,用來將輸入圖像(content image)直接transform為帶有style的圖像;而loss network參數(shù)是fixed的,這里的loss network和A Neural Algorithm of Aritistic Style中的網(wǎng)絡(luò)結(jié)構(gòu)一致,只是參數(shù)不做更新,只用來做content loss 和style loss的計算,這個就是所謂的perceptual loss,作者是這樣解釋的為Image Classification的pretrained的卷積模型已經(jīng)很好的學(xué)習(xí)了perceptual和semantic information(場景和語義信息),所以后面的整個loss network僅僅是為了計算content loss和style loss,而不像A Neural Algorithm of Aritistic Style做更新這部分網(wǎng)絡(luò)的參數(shù),這里更新的是前面的transform network的參數(shù),所以從整個網(wǎng)絡(luò)結(jié)構(gòu)上來看輸入圖像通過transform network得到轉(zhuǎn)換的圖像,然后計算對應(yīng)的loss,整個網(wǎng)絡(luò)通過最小化這個loss去update前面的transform network,是不是很簡單?
loss的計算也和之前的都很類似,content loss:
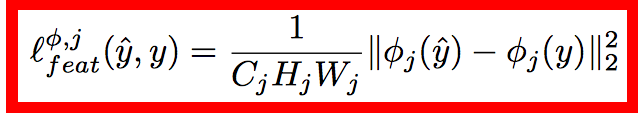
style loss:
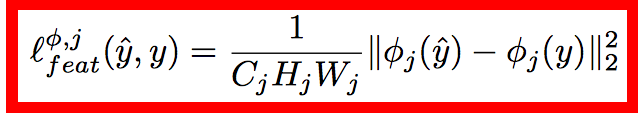
style loss中的gram matrix:
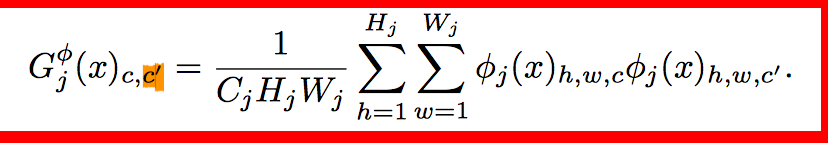
Gram Matrix是一個很重要的東西,他可以保證y^hat和y之間有同樣的shape。 Gram的說明具體見paper這部分,作者這也解釋不清楚,相信讀者一看就明白:

相信看到這里就基本上明白了這篇paper在fast neural style是如何做的,總結(jié)一下:
|
注:本文的技術(shù)內(nèi)容取得 深度學(xué)習(xí)工程師 段石石 的發(fā)布授權(quán),同時為了閱讀體驗,內(nèi)容有些小修改和整合,并精簡了部分的實踐內(nèi)容。如果想了解更多的深度學(xué)習(xí)實踐,請移步到 小石頭的碼瘋營 進(jìn)行閱讀。
【編輯推薦】
- 微服務(wù)時代 怎么看華為軟件開發(fā)云實現(xiàn)DevOps落地
- Google要逆天!Google Wear 2.0 最新離線AI技術(shù)解析
- 基于React與Vue后,移動開源項目Weex如何定義未來
- 世界級的開源項目:TiDB 如何重新定義下一代關(guān)系型數(shù)據(jù)庫
- APM從入門到放棄:可用性監(jiān)控體系和優(yōu)化手段的剖析
【責(zé)任編輯:林師授 TEL:(010)68476606】