從ISSCC 2017看人工智能芯片的四大趨勢
身處人工智能的風口,ISSCC也不能幸免地將本次大會主題定為「Intelligent chips for a smarter world」。


同時,大會還在研究論文報告中設立了專門討論深度學習處理芯片的論文session,在SPR海報session中,也有兩篇來自復旦大學(與華盛頓大學合作)和清華大學的研究,分別針對RNN和CNN的處理器芯片設計。除此之外,大會也安排了探討神經網絡相關課題的tutorialsession(面向初學者)和forum session(面向專業人士)。
本次ISSCC中關于深度學習的論文集中出現在session 14。
作為有深度的專業人工智能公眾號,矽說將從各個技術報告中進行深度歸納、刨析在這些論文引導下的AI芯片發展趨勢。
趨勢一:更高效的大卷積解構/復用
在《腦芯編(四)》中,我們曾提到,在標準SIMD的基礎上,CNN由于其特殊的復用機制,可以進一步減少總線上的數據通信。而復用的這一概念,在超大型神經網絡中的顯得格外重要。對于AlexNet/VGG這些模型中的中后級卷積核,卷積核的參數量可以達3x3x512之巨大,合理地分解這些超大卷積到有效的硬件上成為了一個值得研究的問題。
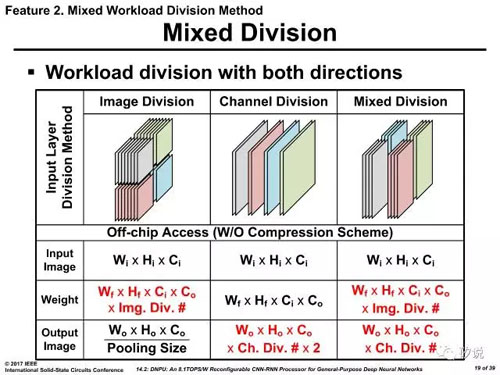
在14.2 中,韓國KAIST學院分析了集中不同的分解方法,包括輸入圖像/卷積核分解,及其混合模式,得到了最終的方案。
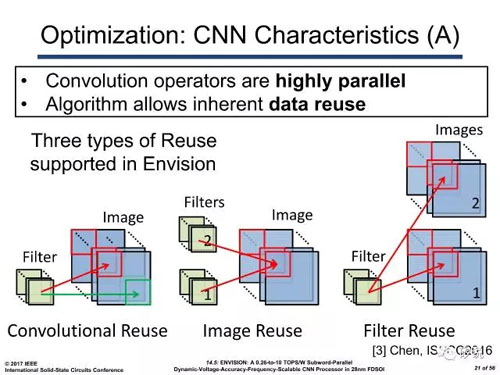
而來自比利時的IMEC在報告14.5中對該問題也有涉及。其方案在Eyeriss的基礎上,沿用了其在2016年VLSI提出的2D SIMD方案。輪流復用輸入與參數,達到高效的數據分解。
趨勢二:更低的Inference計算/存儲位寬
在過去的一年,對AI芯片最大的演進可能就是位寬的迅速衰減。從32位fixed point,16位fixed point,8位fixedpoint,甚至4位fixed point的位寬。在CS的理論計算領域,2位甚至2進制的參數位寬。在ISSCC上,這些“傳說”都已經逐漸進入實踐領域。
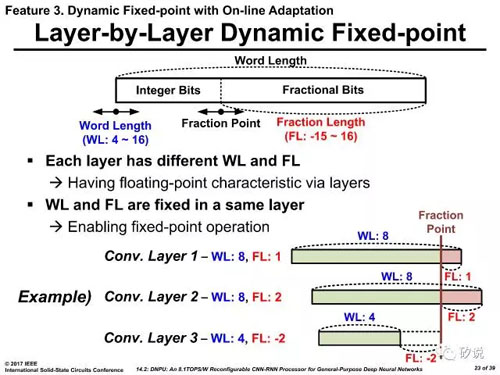
KAIST采用了類似傳說中Nervana的flexpoint方案,在定點系統中采用可浮動的定點進制方案。該方案的前提是在某一固定層的前提下,所有該層的卷積核均服從一個由訓練確定的進制方案,但是在層和層之間是可以變化的。
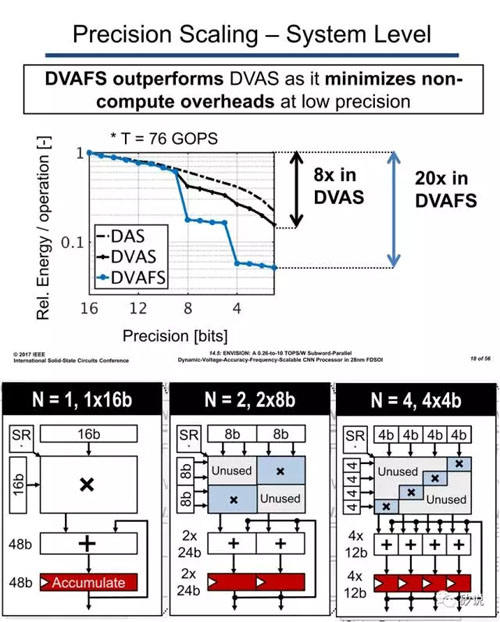
其實,這類方法也不是近年來的創舉,在《腦心編(四)》中我們提到的ARM SIMD指令集——NEON就已經采取了這些辦法,只是最小位寬沒有到達4位罷了。而報告14.5中IMEC的方案在變化進制的基礎上,進一步采用的通過改變電壓和頻率的方法得到更優的能效值。
另外,指的一提的是參數的非線性映射以減少參數讀取時的位寬也成為了一個新的關注點。其理論基礎由Stanford 大學Bill Dally課題組提出,目前已經出現了類似的芯片實現,詳見14.2。

趨勢三:更多樣的存儲器定制設計
當乘加計算(MAC,Multiplier and accumulation)不再成為神經網絡加速器的設計瓶頸時,一個新的研究方向就冉冉而生——如何減少存儲器的訪問延時。在《腦心編(六)》里,我們提到過,離計算越近的存儲器越值錢。于是新型的存儲結構也應運而生。
首先是密歇根大學提出了面向深度學習優化的協處理器多層高速緩存機制,通過數據的重要性對數據位置進行定義。
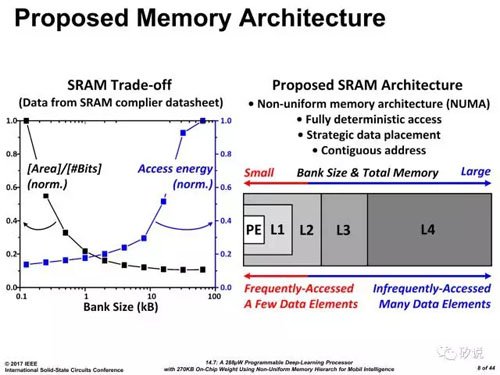
在KAIST的另外一篇文章14.6里,作者提出了一種可轉置(transpose)的SRAM架構,即數據的寫入與讀出可以是通向的,也可以是垂直的。該方法能省去卷積網絡中額外的數據整理,并且就大卷積的解構提供了芯思路。

趨勢四:更稀疏的大規模向量乘實現
神經網絡雖然大,但是,實際上的有非常多以零為輸入的情況(Relu輸出或者系數為0)此時稀疏計算可以高校地減少無用能效。來自哈佛大學的團隊就該問題優化的五級流水線結構,在最后一級輸出了觸發信號,見14.3。
在Activation層后對下一次計算的必要性進行預先判斷,如果發現這是一個稀疏節點,則觸發SKIP信號,避免乘法運算的功耗,以達到減少無用功耗的問題。
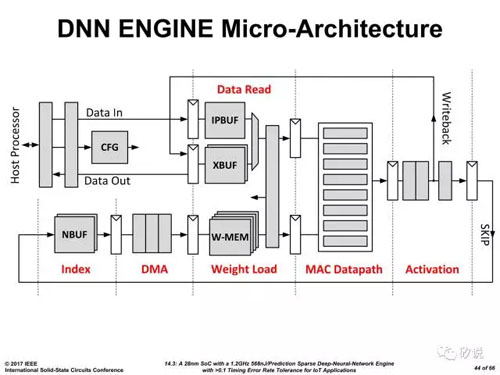
這一問題甚至受到了Bill Dally老人家的關注,在其Forum的演講中提到了它們尚未發表的稀疏加速架構。
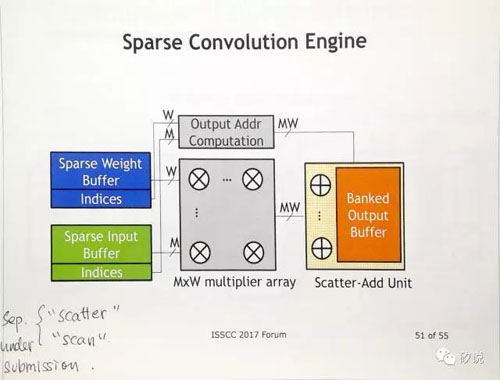
只可惜,我們要直到九月份才能讀到paper。
最后,我們總結下這四個趨勢的關鍵詞——復用、位寬、存儲、稀疏。要做 AI 芯片的你,有關注到的么?
【本文是51CTO專欄機構機器之心的原創文章,微信公眾號“機器之心( id: almosthuman2014)”】