大火的Apache Spark也有諸多不完美
現在如果你想要選擇一個解決方案來處理企業中的大數據并不是難事,畢竟有很多數據處理框架可以任君選擇,如Apache Samza,Apache Storm 、Apache Spark等等。Apache Spark應該是2016年風頭最勁的數據處理框架,它在數據的批處理和實時流處理方面有著得天獨厚的優勢。
Apache Spark為大數據處理提供一套完整的工具,用戶在大數據集上進行操作完全不需考慮底層基礎架構,它會幫助用戶進行數據采集、查詢、處理以及機器學習,甚至還可以構建抽象分布式系統。
Apache Spark以速度而聞名,當然這是MapReduce改進的結果,它沒有把數據保存在磁盤上,而是選擇將數據保存在內存中。另外,Apache Spark提供了三種語言的庫,即Scala,Java和Python。
Spark架構
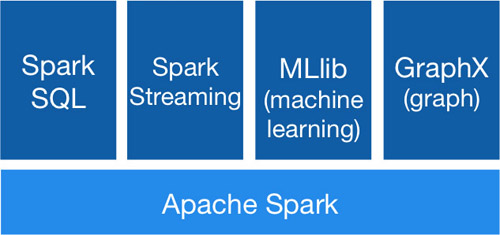
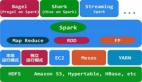
Apache Spark雖然主要用于處理流數據,但是它也包含了很多數據執行操作的組件,上圖就展示了它的不同模塊。
Spark SQL:Apache Spark附帶了SQL接口,這意味著用戶可以直接使用SQL查詢來與數據進行交互,這些查詢統統是由Spark的執行引擎來處理的。
Spark Streaming:此模塊提供一組API,用于編寫對數據的實時流執行操作的應用程序,它會先將傳入的數據流劃分為微批次,然后再對數據執行操作。
MLib:MLLib提供了一組API,主要用于對大型數據集運行機器學習算法。
GraphX:支持內置的圖操作算法,尤其適用于有很多連接節點的數據集。
除了數據處理庫,Apache Spark還附帶了一個Web UI。當運行Spark應用程序時,Web UI會默認打開4040端口進行監聽,用戶可以在其中查看有關任務執行器和統計信息的詳細信息,甚至還可以查看任務在執行階段所花費的時間,從而幫助用戶進一步優化性能。
用例
分析:Spark在數據流傳入構建實時分析時能夠發揮很大作用,它可以有效處理各種來源的大量數據,支持HDFS,Kafka,Flume,Twitter和ZeroMQ,還可以處理自定義數據源。
趨勢數據:Apache Spark可用于從傳入事件流計算趨勢數據。
物聯網:物聯網系統會生成大量數據然后將其推送到后端進行處理。 Apache Spark能夠以固定的間隔(每分鐘,小時,周,月等)構建數據管道,還可以基于一組可配置的事件觸發操作。
機器學習:因為Spark可以批量處理離線數據并提供機器學習庫(MLib),所以用戶的數據集上可以輕松應用機器學習算法。 此外,用戶可以通過一個大型數據集來實驗不同的算法,將MLib與Spark Streaming組合,就可以輕松擁有一個實時機器學習系統。
雖然Apache Spark在很短的時間內就獲得了***的人氣,但是它也不是***無缺的。
部署棘手
目前Apache Spark支持三種分布式部署方式,分別是standalone、spark on mesos和 spark on YARN。其中,獨立部署是最簡單直接的方法,而后兩種部署方式較為復雜,對于沒有經驗的新手來說難度很大,在安裝依賴的時候可能會遇到一些問題。如果不正確,Spark應用程序將在獨立模式下工作,但在集群模式下運行時會遇到類路徑異常。
內存問題
因為Apache Spark是為處理大量數據而存在的,所以監控和測量內存使用是至關重要的。Spark中有很多配置是可以根據用例進行調整的,默認配置不一定是***的,所以建議用戶要仔細閱讀Spark內存配置的文檔,根據自己的需求及時作出調整。
版本發布頻繁導致API更改
Apache Spark無論是1.x.x版本還是2.x.x版本都一直遵循著三四個月的發布周期,雖說版本的快速迭代代表了Spark的活力和開發人員功能開發的能力,但是它也意味著API的變化。對于,不希望API變化的用戶來說,頻繁的版本發布反而成了一大難題,甚至為了確保Spark應用程序不受API更改的影響不得不增加額外的開銷。
Python支持不成熟
Apache Spark支持Scala,Java和Python,這很對開發人員的胃口,但是這三者的地位并非平起平坐的,尤其是在涉及到新功能時,Java和Scala總是可以***時間更新,而 Python庫需要一些時間才能趕上***的API和功能。所以用戶在選用***版本的Spark時,應該首先考慮使用Java或Scala實現,如果選用Python則需考慮 feature/API中是否已經支持。
文檔貧乏
文檔教程和代碼演練對于新手快速提升能力非常重要,而Apache Spark的樣例雖然會和文檔一起分享出來,但是大部分的示例都很基本,有質量的深度樣例很少,所以對于想要學習Spark的用戶來說參考意義并不是很大。
后記
Apache Spark能夠在短時間內擊敗其它對手走紅,不是沒有道理的,它的確是一款很好的大數據處理框架,但是如果你的數據沒有達到一定的量級,選用Spark無異于殺雞用牛刀,而簡單的解決方案不失為一個更好的選擇。