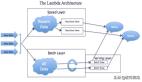
使用Apache Spark 的Lambda架構
市場上很多玩家已經建造了MapReduce工作流用來日常處理兆兆字節的歷史數據。但是誰愿意等待24小時來拿到更新后的分析報告?這篇博客會向你介紹Lambda Architecture,它被設計出來既可以利用批量處理方法,也可以使用流式處理方法。這樣我們就可以利用Apache Spark(核心, SQL, 流),Apache Parquet,Twitter Stream等工具處理實時流式數據,實現對歷史數據的快速訪問。代碼簡潔干凈,而且附上直接明了的示例!
Apache Hadoop: 簡要歷史
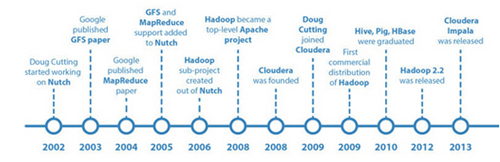
Apache Hadoop的豐富歷史開始于大約2002年。Hadoop是Doug Cutting創立的, 他也是Apache Lucene這一被廣泛使用的文本檢索庫的創造者. Hadoop的起源與Apache Nutch有關, Apache Nutch是一個開源的web搜索引擎, 本身也是Lucene項目的一部分. Apache Nutch在大約10年前成為一個獨立的項目.
事實上,許多用戶實現了成功的基于HadoopM/R的通道,一直運行到現在.現實生活中我至少能舉出好幾個例子:
- Oozie協調下的工作流每日運行和處理多達8TB數據并生成分析報告
- bash管理的工作流每日運行和處理多達8TB數據并生成分析報告
現在是2016年了
商業現實已經改變,所以做出長遠的決定變得更有價值。除此以外,技術本身也在演化進步。Kafka, Storm, Trident, Samza, Spark, Flink, Parquet, Avro, Cloud providers等時髦的技術被工程師們和在商業上廣泛使用.
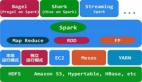
因此,現代基于Hadoop的 M/R通道 (以及Kafka,現代的二進制形式如Avro和數據倉庫等。在本例中Amazon Redshift用作ad-hoc查詢) 可能看起來像這樣:
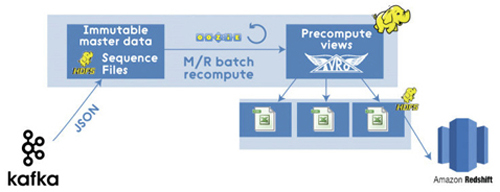
以上M/R通道看起來很不錯,但是它仍然是傳統上具有許多缺點的批處理。由于在新數據不斷進入系統時,批處理過程通常需要花費很多時間來完成,它們主要是提供給終端用戶的乏味的數據罷了。
Lambda 架構
Nathan Marz為通用,可擴展和容錯性強的數據處理架構想出了一個術語Lambda架構。這個數據架構結合了批處理和流處理方法的優點來處理大批量數據。
我強烈推薦閱讀 Nathan Marz 的書 ,這本書從源碼角度對Lambda架構進行了完美的詮釋。
層結構
從頂層來看,這是層的結構:
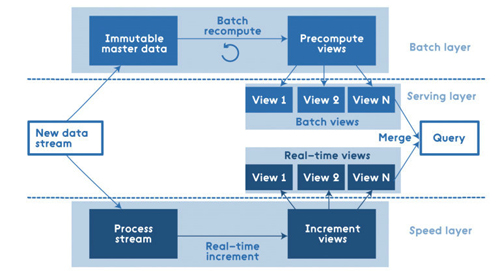
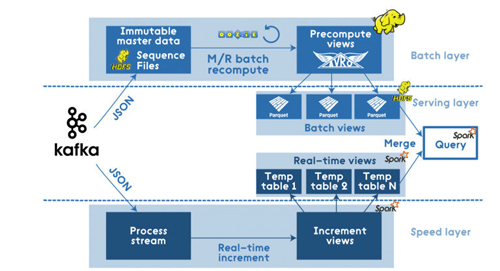
所有進入系統的數據被分配到了批處理層和高速層來處理。批處理層管理著主數據集(一個不可修改,只能新增的原始數據)和預計算批處理視圖。服務層索引批處理視圖,因此可以對它們進行低延時的臨時查詢。高速層只處理近期的數據。任何輸入的查詢結果都合并了批處理視圖和實時視圖的查詢結果。
焦點
許多工程師認為 Lambda架構就包含這些層和定義數據流程,但是 Nathan Marz在他的書中把焦點放在了其他重要的地方,如:
- 分布式思想
- 避免增量架構
- 關注數據的不可變性
- 創建再計算算法
- 數據的相關性
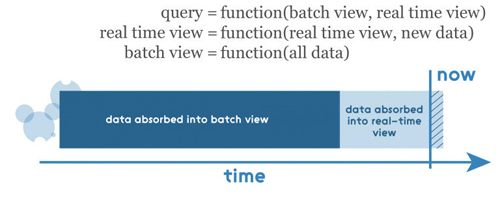
正如前面所提到的,任何輸入的查詢結果都會從批處理視圖和實時視圖的查詢結果返回,因此這些視圖需要被合并。在這里,需要注意的一點是,一個實時視圖是上一個實時視圖和新的數據增量的函數,因此一個增量算法可以在這里使用。批處理視圖是所有數據的視圖,因此再計算算法可以在這里使用。
均衡取舍
我們生活中的一切問題都存在權衡,Lambda架構(Lambda Architecture)不例外。 通常,我們需要解決幾個主要的權衡:
完全重新計算vs.部分重新計算
某些情況下,可以考慮使用Bloom過濾器來避免完全重新計算
重算算法 vs. 增量算法
使用增量算法是個很大的誘惑,但參考指南,我們必須使用重算算法,即使它更難得到相同的結果
加法算法 vs. 近似算法
Lambda Architecture 能與加法算法很好地協同工作。 因此,在另一種情況下,我們需要考慮使用近似算法,例如,使用HyperLogLog處理count-distinct的問題等。
實現
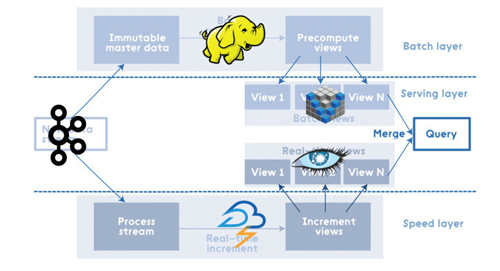
有許多實現Lambda架構的方法,因為對于每個層的底層解決方案是非常獨立的。每個層需要底層實現的特定功能,有助于做出更好的選擇并避免過度決策:
批量層(Batch Layer):寫一次,批量讀取多次
服務層(Serving layer):隨機讀取,不支持隨機寫入,批量計算和批量寫入
速度層(Speed layer):隨機讀取,隨機寫入;增量計算
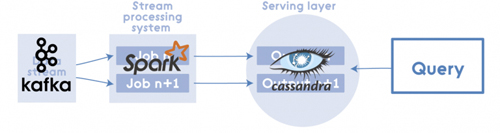
例如,其中一個實現方案的構成(使用Kafka,Apache Hadoop,Voldemort,Twitter Storm,Cassandra)可能如下圖所示:
Apache Spark
Apache Spark可以被認為是用于Lambda架構各層的集成解決方案。其中,Spark Core 包含了高層次的API和優化的支持通用圖運算引擎,Spark SQL用于SQL和結構化數據處理、 Spark Streaming 可以解決高拓展、高吞吐、容錯的實時流處理。在批處理中使用Spark可能小題大做,而且不是所有方案和數據集都適用。但除此之外,Spark算是對Lambda Architecture的合理的實現。
示例應用
下面通過一些路徑創建一個示例應用,以展示Lambda Architecture,其主要目的是提供#morningatlohika tweets(一個由我在Lviv, Ukraine發起的本地技術演講,)這個hash標簽的統計:包括之前到今天這一刻的所有時間。
源碼在GitHub 上,有關這個主題的更多信息可以在Slideshare上找到。
批處理視圖(Batch View)
簡單地說,假定我們的主數據集包含自開始時間以來的所有更新。 此外,我們已經實現了一個批處理,可用于創建我們的業務目標所需的批處理視圖,因此我們有一個預計算的批處理視圖,其中包含所有與#morningatlohika相關的標簽統計信息:

編號很容易記住,因為,為方便查看,我使用對應標簽的英文單詞的字母數目作為編號。
實時視圖
假設應用程序啟動后,同時有人發如下tweet:
“Cool blog post by @tmatyashovsky about #lambda #architecture using #apache #spark at #morningatlohika”
此時,正確的實時視圖應該包含如下的hash標簽和統計數據(本例中都是1,因為每個hash標簽只用了一次):

查詢
當終端用戶查詢出現是,為了給全部hash標簽返回實時統計結果,我們只需要合并批處理視圖和實時視圖。所以,輸出如下所示編碼(hash標簽的正確統計數據都加了1):

場景
示例中的場景可以簡化為如下步驟:
用Apache Spark創建批處理視圖(.parquet)
在Spark中緩存批處理視圖
將流處理應用連接到Twitter
實時監視包含#morningatlohika 的tweets
構造增量實時視圖
查詢,即,即時合并批處理視圖和實時視圖
技術細節
此源代碼是基于Apache Spark 1.6.x(注:再引入結構流之前)。 Spark Streaming架構是純微型批處理架構:
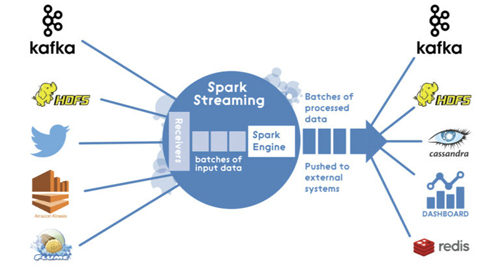
所以當我處理一個流媒體應用程序時,我使用DStream來連接使用TwitterUtils的Twitter:

在每個微批次中(使用可配置的批處理間隔),我正在對新tweets中的hashtags統計信息進行計算,并使用updateStateByKey()狀態轉換函數來更新實時視圖的狀態。簡單地說,就是使用臨時表將實時視圖存儲在存儲器中。
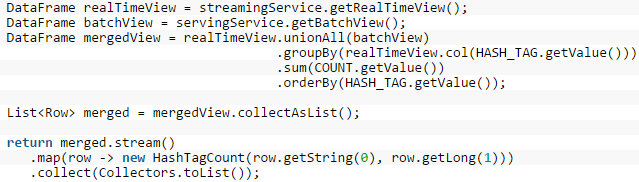
查詢服務反映了批處理的合并過程和通過代碼表示的DataFrame實時視圖:
成果
在簡化的方案下,文章開頭提到的基于Hadoop 的M/R 管道可以通過Apache Spark進行如下優化:
本章結語
正如上文提到的 Lambda架構有優點和缺點,所以結果就是有支持者和反對者。一些人會說批處理視圖和實時視圖有很多重復的邏輯,因為最終他們需要從查詢的角度創建出可以合并的視圖。因此,他們創建了Kappa架構——一個Lambda架構的簡化方案。Kappa 架構的系統去掉了批處理系統,取而代之的是數據從流處理系統中快速通過:
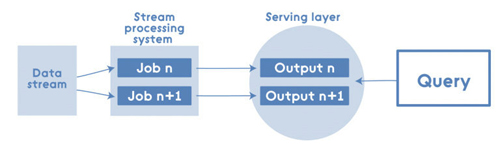
即便在此場景中,Spark也能發揮作用,比如,參與流處理系統: