Apache Spark
作者:chensf整理
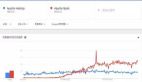
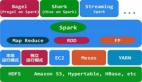
Spark是個開源的數(shù)據(jù)分析集群計算框架,最初由加州大學(xué)伯克利分校AMPLab開發(fā),建立于HDFS之上。Spark與Hadoop一樣,用于構(gòu)建大規(guī)模、低延時的數(shù)據(jù)分析應(yīng)用。Spark采用Scala語言實(shí)現(xiàn),使用Scala作為應(yīng)用框架。
代碼托管地址: Apache
Spark是個開源的數(shù)據(jù)分析集群計算框架,最初由加州大學(xué)伯克利分校AMPLab開發(fā),建立于HDFS之上。Spark與Hadoop一樣,用于構(gòu)建大規(guī)模、低延時的數(shù)據(jù)分析應(yīng)用。Spark采用Scala語言實(shí)現(xiàn),使用Scala作為應(yīng)用框架。
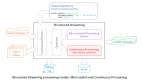
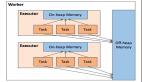
Spark采用基于內(nèi)存的分布式數(shù)據(jù)集,優(yōu)化了迭代式的工作負(fù)載以及交互式查詢。與Hadoop不同的是,Spark和Scala緊密集 成,Scala像管理本地collective對象那樣管理分布式數(shù)據(jù)集。Spark支持分布式數(shù)據(jù)集上的迭代式任務(wù),實(shí)際上可以在Hadoop文件系統(tǒng) 上與Hadoop一起運(yùn)行(通過YARN、Mesos等實(shí)現(xiàn))。
責(zé)任編輯:陳四芳
來源:
51CTO