Openstack源碼閱讀的正確姿勢

1. 談談Openstack的發展歷史
OpenStack是一個面向IaaS層的云管理平臺開源項目,用于實現公有云和私有云的部署及管理。最開始Openstack只有兩個組件,分別為提供計算服務的Nova項目以及提供對象存儲服務的Swift,其中Nova不僅提供虛擬機服務,還包含了網絡服務、塊存儲服務、鏡像服務以及裸機管理服務。之后隨著項目的不斷發展,從Nova中拆分成多個獨立的項目各自提供不同的服務,如拆分為Cinder項目提供塊存儲服務,拆分為Glance項目,提供鏡像服務,nova-network則是neutron的前身,裸機管理也從Nova中分離出來為Ironic項目。最開始容器服務也是由Nova提供支持的,作為Nova的driver之一來實現,而后遷移到Heat,到現在已經分離成獨立的項目Magnum,后來Magnum主要提供容器編排服務,單純的容器服務由Zun項目負責。最開始Openstack并沒有認證功能,從E版開始才加入認證服務Keystone,至此Openstack 6個核心服務才終于聚齊了。
- Keystone 認證服務。
- Glance 鏡像服務。
- Nova 計算服務。
- Cinder 塊存儲服務。
- Neutorn 網絡服務。
- Swift 對象存儲服務。
E版之后,在這些核心服務之上,又不斷涌現新的服務,如面板服務Horizon、服務編排服務Heat、數據庫服務Trove、文件共享服務Manila、大數據服務Sahara以及前面提到的Magnum等,這些服務幾乎都依賴于以上的核心服務。比如Sahara大數據服務會先調用Heat模板服務,Heat又會調用Nova創建虛擬機,調用Glance獲取鏡像,調用Cinder創建數據卷,調用Neutron創建網絡等。還有一些項目圍繞Openstack部署的項目,比如Puppet-openstack、Kolla、TripleO、Fuel等項目。
截至現在(2016年11月27日),Openstack已經走過了6年半的歲月,***發布的版本為第14個版本,代號為Newton,Ocata版已經處在快速開發中。
Openstack服務越來越多、越來越復雜,并且不斷變化發展。以Nova為例,從最開始使用nova-conductor代理數據庫訪問增強安全性,引入objects對象模型來支持對象版本控制,現在正在開發Cell項目來支持大規模的集群部署以及將要分離的Nova-EC2項目,截至到現在Nova包含nova-api、nova-conductor、nova-scheduler、nova-compute、nova-cell、nova-console等十多個組件。這么龐大的分布式系統需要深刻理解其工作原理,理清它們的交互關系非常不容易,尤其對于新手來說。
2.工欲善其事,必先利其器
由于Openstack使用python語言開發,而python是動態類型語言,參數類型不容易從代碼中看出,因此首先需要部署一個allinone的Openstack開發測試環境,建議使用RDO部署:Packstack quickstart,當然樂于折騰使用devstack也是沒有問題的。
其次需要安裝科學的代碼閱讀工具,圖形界面使用pycharm沒有問題,不過通常在虛擬機中是沒有圖形界面的,***vim,需要簡單的配置使其支持代碼跳轉和代碼搜索,可以參考我的vim配置GitHub - int32bit/dotfiles: A set of vim, zsh, git, and tmux configuration files。
掌握python的調試技巧,推薦pdb、ipdb、ptpdb,其中ptpdb***用,不過需要手動安裝。打斷點前需要注意代碼執行時屬于哪個服務組件,nova-api的代碼,你跑去nova-compute里打斷點肯定沒用。另外需要注意打了斷點后的服務必須在前端運行,不能在后臺運行,比如我們在nova/compute/manager.py中打了斷點,我們需要kill掉后臺進程:
- systemctl stop openstack-nova-compute
然后直接在終端運行nova-compute即可。
- su -c 'nova-compute' nova
3 .教你閱讀的正確姿勢
學習Openstack的***步驟是:
- 看文檔
- 部署allineone
- 使用之
- 折騰之、怒斥之
- 部署多節點
- 深度使用、深度吐槽
- 閱讀源碼
- 混社區,參與社區開發
閱讀源碼的首要問題就是就要對代碼的結構了然于胸,需要強調的是,Openstack項目的目錄結構并不是根據組件劃分的,而是根據功能劃分的,以Nova為例,compute目錄并不是一定在nova-compute節點上運行的代碼,而主要是和compute相關(虛擬機操作相關)的功能實現,同樣的,scheduler目錄代碼并不全在scheduler服務節點運行,但主要是和調度相關的代碼。好在目錄結構并不是完全混亂的,它是有規律的。
通常一個服務的目錄都會包含api.py、rpcapi.py、manager.py,這個三個是最重要的模塊。
- api.py: 通常是供其它組件調用的庫。換句話說,該模塊通常并不會由本模塊調用。比如compute目錄的api.py,通常由nova-api服務的controller調用。
- rpcapi.py:這個是RPC請求的封裝,或者說是RPC實現的client端,該模塊封裝了RPC請求調用。
- manager.py: 這個才是真正服務的功能實現,也是RPC的服務端,即處理RPC請求的入口,實現的方法通常和rpcapi實現的方法對應。
前面提到Openstack項目的目錄結構是按照功能劃分的,而不是服務組件,因此并不是所有的目錄都能有對應的組件。仍以Nova為例:
- cmd:這是服務的啟動腳本,即所有服務的main函數。看服務怎么初始化,就從這里開始。
- db: 封裝數據庫訪問,目前支持的driver為sqlalchemy。
- conf:Nova的配置項聲明都在這里。
- locale: 本地化處理。
- image: 封裝Glance調用接口。
- network: 封裝網絡服務接口,根據配置不同,可能調用nova-network或者neutron。
- volume: 封裝數據卷訪問接口,通常是Cinder的client封裝。
- virt: 這是所有支持的hypervisor驅動,主流的如libvirt、xen等。
- objects: 對象模型,封裝了所有實體對象的CURD操作,相對以前直接調用db的model更安全,并且支持版本控制。
- policies: policy校驗實現。
- tests: 單元測試和功能測試代碼。
根據進程閱讀源碼并不是什么好的實踐,因為光理解服務如何初始化、如何通信、如何發送心跳等就不容易,各種高級封裝太復雜了。而我認為比較好的閱讀源碼方式是追蹤一個任務的執行過程,比如追蹤啟動一臺虛擬機的整個流程。
不管任何操作,一定是先從API開始的,RESTFul API是Openstack服務的唯一入口,也就是說,閱讀源碼就從api開始。而api組件也是根據實體劃分的,不同的實體對應不同的controller,比如servers、flavors、keypairs等,controller通常對應有如下方法:
- index: 獲取資源列表,一般對應RESTFul API的URL為“GET /resources”,如獲取虛擬機的列表API為“GET /servers”。
- get: 獲取一個資源,比如返回一個虛擬機的詳細信息API為”GET /servers/uuid“。
- create: 創建一個新的資源,通常對應為POST請求。比如創建一臺虛擬機為 “POST /servers”, 當然POST的數據為虛擬機信息。
- delete: 刪除指定資源,通常對應DELETE請求,比如刪除一臺虛擬機為“DELETE/servers/uuid”。
- update: 更新資源信息,通常對應為PUT請求,比如更新虛擬機資源為”PUT /servers/uuid,body為虛擬機數據。
了解了代碼結構,找到了入口,再配合智能跳轉,閱讀源碼勢必事半功倍。如果有不明白的地方,隨時可以加上斷點單步調試。
4.案例分析
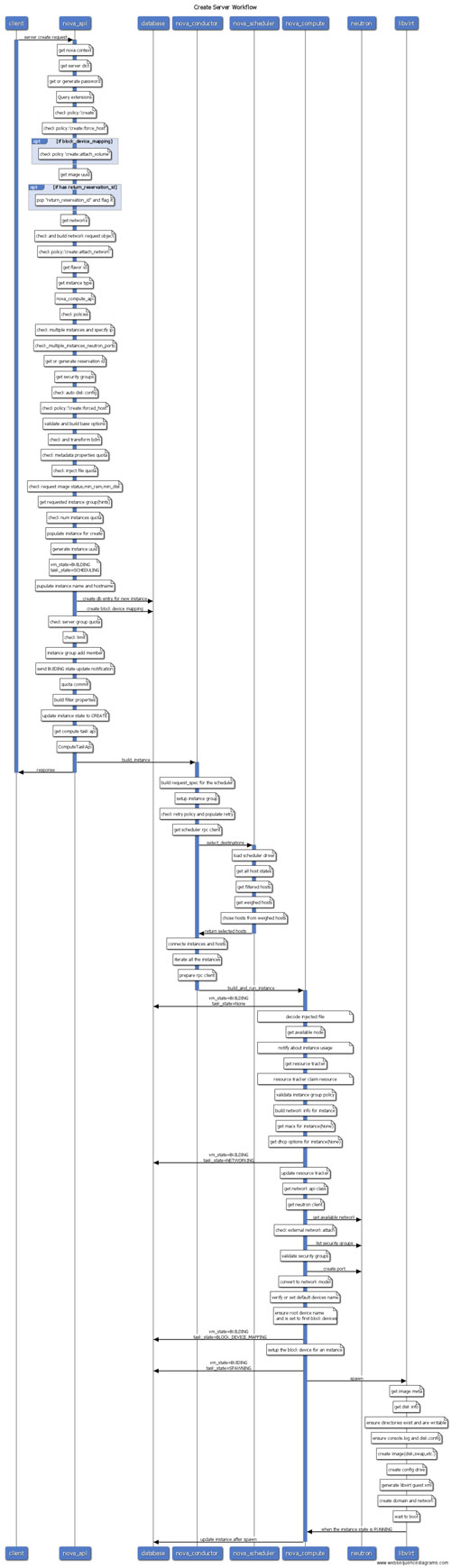
接下來以創建虛擬機為例,根據組件劃分,一步步分析整個工作流程以及操作序列。請再次回顧下api.py、rpcapi.py、manager.py以及api下的controller結構,否則閱讀到后面會越來越迷糊。
S1 nova-api
入口為nova/api/openstack/compute/servers.py的create方法,該方法檢查了一堆參數以及policy后,調用compute_api的create方法,這里的compute_api即前面說的nova/compute/api.py模塊的API。
compute_api會創建數據庫記錄、檢查參數等,然后調用compute_task_api的build_instances方法,compute_task_api即conductor的api.py。
conductor的api并沒有執行什么操作,直接調用了conductor_compute_rpcapi的build_instances方法,該方法即時conductor RPC調用api,即nova/conductor/rpcapi.py模塊,該方法除了一堆的版本檢查,剩下的就是對RPC調用的封裝,代碼只有兩行:
- cctxt = self.client.prepare(version=version)
- cctxt.cast(context, 'build_instances', **kw)
其中cast表示異步調用,build_instances是遠程調用的方法,kw是傳遞的參數。參數是字典類型,沒有復雜對象結構,因此不需要特別的序列化操作。
截至到現在,雖然目錄由api->compute->conductor,但仍在nova-api進程中運行,直到cast方法執行,該方法由于是異步調用,因此nova-api不會等待遠程方法調用結果,直接返回結束。
S2 nova-conductor
由于是向nova-conductor發起的RPC調用,而前面說了接收端肯定是manager.py,因此進程跳到nova-conductor服務,入口為nova/conductor/manager.py的build_instances方法。
該方法首先調用了_schedule_instances方法,該方法調用了scheduler_client的select_destinations方法,scheduler_client和compute_api以及compute_task_api都是一樣對服務的client調用(即api.py),不過scheduler沒有api.py,而是有個單獨的client目錄,實現在client目錄的__init__.py模塊,這里僅僅是調用query.py下SchedulerQueryClient的select_destinations實現,然后又很直接的調用了scheduler_rpcapi的select_destinations方法,終于又到了RPC調用環節。
毫無疑問,RPC封裝同樣是在scheduler的rpcapi中實現。該方法RPC調用代碼如下:
- return cctxt.call(ctxt, 'select_destinations', **msg_args)
注意這里調用的call方法,即同步調用,此時nova-conductor并不會退出,而是堵塞等待直到nova-scheduler返回。
S3 nova-scheduler
同理找到scheduler的manager.py模塊的select_destinations方法,該方法會調用driver對應的方法,這里的driver其實就是調度算法實現,由配置文件決定,通常用的比較多的就是filter_scheduler,對應filter_scheduler.py模塊,該模塊首先通過host_manager拿到所有的計算節點信息,然后通過filters過濾掉不滿足條件的計算節點,剩下的節點通過weigh方法計算權值,***選擇權值高的作為候選計算節點返回。nova-scheduler進程結束。
S4 nova-condutor
回到scheduler/manager.py的build_instances方法,nova-conductor等待nova-scheduler返回后,拿到調度的計算節點列表,然后調用了compute_rpcapi的build_and_run_instance方法。看到xxxrpc立即想到對應的代碼位置,位于compute/rpcapi模塊,該方法向nova-compute發起RPC請求:
- cctxt.cast(ctxt, 'build_and_run_instance', ...)
可見發起的是異步RPC,因此nova-conductor結束,緊接著終于輪到nova-compute登場了。
S5 nova-compute
到了nova-compute服務,入口為compute/manager.py,找到build_and_run_instance方法,該方法調用了driver的spawn方法,這里的driver就是各種hypervisor的實現,所有實現的driver都在virt目錄下,入口為driver.py,比如libvirt driver實現對應為virt/libvirt/driver.py,找到spawn方法,該方法拉取鏡像創建根磁盤、生成xml文件、define domain,啟動domain等。***虛擬機完成創建。nova-compute服務結束。
一張圖總結以上是創建虛擬機的各個服務的交互過程以及調用關系,需要注意的是,所有的數據庫操作,比如instance.save()以及update操作,如果配置use_local為false,則會向nova-conductor發起RPC調用,由nova-conductor代理完成數據庫更新,而不是由nova-compute直接訪問數據庫,這里的RPC調用過程在以上的分析中省略了。
整個流程用一張圖表示為:
【本文是51CTO專欄作者“付廣平”的原創文章,如需轉載請通過51CTO獲得聯系】