AI 學會“腦補”:神經網絡超逼真圖像補完從 0 到 1
1 新智元編譯
來源:arXiv、Github
編譯:張易
【新智元導讀】自動圖像補全是計算機視覺和圖形領域幾十年來的研究熱點和難點。在神經網絡的幫助下,來自伯克利、Adobe 等研究人員利用組合優化和類似風格轉移的方法,突破以往技術局限,成功實現了超逼真的“從0到1”圖像生成。代碼已在Github 開源。
 完勝 PS!新方法實現完美“腦補”
完勝 PS!新方法實現完美“腦補”
在分享照片之前,你可能會想進行一些修改,例如擦除分散注意力的場景元素,調整圖像中的物體位置以獲得更好的組合效果,或者把被遮擋的部分恢復出來。
這些操作,以及其他許多編輯操作,需要進行自動的孔洞填充(圖像補足),這是過去幾十年間計算機視覺和圖形領域的一個研究熱點。因為自然圖像固有的模糊性和復雜性,整體填充也是長期以來的難點。
但現在,這個問題終于得到了比較好的解決,證據就是下面這幅圖。

這項全新研究的主要貢獻是:
-
提出了一個聯合優化框架,可以通過用卷積神經網絡為全局內容約束和局部紋理約束建模,來虛構出缺失的圖像區域。
-
進一步介紹了基于聯合優化框架的用于高分辨率圖像修復的多尺度神經補丁合成算法。
-
在兩個公共數據集上評估了所提出的方法,并證明了其優于基線和現有技術的優勢。
克服現有方法局限,用深度學習風格轉移合成逼真細節
我們稍后會詳細介紹這項研究成果。在此之前,有必要補充一下背景知識。
現有的解決孔洞填充問題的方法分為兩組。第一組方法依賴于紋理合成技術,其通過擴展周圍區域的紋理來填充空白。這些技術的共同點是使用相似紋理的補丁,以從粗到精的方式合成孔洞的內容。有時,會引入多個尺度和方向,以找到更好的匹配補丁。Barnes et al.(2009) 提出了 PatchMatch,這是一種快速近似最近鄰補丁的搜索算法。
盡管這樣的方法有益于傳遞高頻紋理細節,但它們不抓取圖像的語義或全局結構。第二組方法利用大型外部數據庫,以數據驅動的方式虛構缺失的圖像區域。這些方法假定被相似上下文包圍的區域可能具有相似的內容。如果能找到和所查詢圖像具有足夠視覺相似度的圖像樣本,這種方法會非常有效,但是當查詢圖像在數據庫中沒有被很好地表示時,該方法可能會失敗。另外,這樣的方法需要訪問外部數據庫,這極大地限制了可能的應用場景。
最近,深度神經網絡被用于紋理合成和圖像的風格化(stylization)。特別需要指出,Phatak et al(2016)訓練了具有結合了和對抗性損失的編碼器 - 解碼器 CNN(Context Encoders)來直接預測丟失的圖像區域。這項工作能夠預測合理的圖像結構,并且評估非常快,因為孔洞區域的預測是在a single forward pass中進行的。雖然結果令人鼓舞,但有時這種方法的修復結果缺乏精細的紋理細節,在空白區域的邊界周圍會產生可見的偽跡。 這種方法也不能處理高分辨率圖像,因為當輸入較大時,和對抗性損失相關的訓練會有困難。
在最近的一項研究中,Li和Wand(2016)指出,通過對圖像進行優化(該圖像的中間層神經響應與內容圖像相似,底層卷局部響應模仿style圖像的局部響應),可以實現逼真的圖像stylization結果。那些局部響應由小的(通常3×3)神經補丁表示。 該方法證明能夠將高頻率細節從style圖像傳輸到內容圖像,因此適合于實際的傳遞任務(例如,傳遞面部或汽車的外觀)。盡管如此,通過使用神經響應的 gram matrices 能更好地進行更多藝術風格的傳遞。
好,是主角出場的時候了——
為了克服上述方法的局限性,來自伯克利、Adobe、Pinscreen 和 USC Institute for Creative Technologies 的研究人員提出了一種混合優化方法(joint optimization),利用編碼器 - 解碼器CNN的結構化預測和神經補丁的力量,成功合成了實際的高頻細節。類似于風格轉移,他們的方法將編碼器 - 解碼器預測作為全局內容約束,并且將孔洞和已知區域之間的局部神經補丁相似性作為風格(style)約束。
更具體地說,使用中間層的補丁響應(該中間層使用預訓練分類網絡),可以通過訓練類似于 Context Encoder 的全局內容預測網絡來構造內容約束,并且可以用環繞孔洞的圖像內容來對紋理約束進行建模。可以使用具有有限存儲的 BFGS 的反向傳遞算法來有效地優化這兩個約束。
作者在論文中寫道:“我們通過實驗證明,新提出的多尺度神經補丁合成方法可以產生更多真實和連貫的結果,保留結構和紋理的細節。我們在兩個公共數據集上定量和定性地評估了所提出的方法,并證明了其在各種基線和現有技術上的有效性,如圖1 所示。”

圖1:對于給定的一張帶有孔洞(256×256)的圖像(512×512),我們的算法可以合成出更清晰連貫的孔洞內容(d)。我們可以和用Context Encoders(b)、PatchMatch(c)這兩種方法產生的結果進行比較。
具體方法
為了進一步處理帶有大面積孔洞的高分辨率圖像,作者提出了一種多尺度神經補丁合成方法。為了簡化公式,假設測試圖像始終裁剪為 512×512,中間有一個 256×256 的孔洞。然后,創建一個三級金字塔,步長為二,在每個級別將圖像縮小一半。它呈現 128×128 的最低分辨率,帶有 64×64 的孔洞。接下來,我們以從粗到精的方式執行孔洞填充任務。初始化最低級別的內容預測網絡的輸出,在每個尺度(1)執行聯合優化以更新孔洞;(2)upsample 以初始化聯合優化并為下一個尺度設置內容約束。最后,重復此步驟,直到聯合優化以最高分辨率完成。
Framework 概述
我們尋求對損失函數進行了優化的修復圖像,其被表示為三個項的組合:整體內容項,局部紋理項和tv-loss項。 內容項是捕獲圖像的語義和全局結構的全局結構約束,并且局部項通過使其與已知區域一致來重新定義局部紋理。 內容項和紋理項均使用具有固定參數的預訓練網絡來計算。
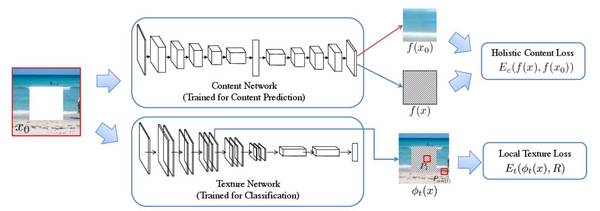
圖2. Framework 概述。我們的方法使用兩個聯合損失函數來解決未知圖像,即整體內容損失和局部紋理損失。通過將圖像饋送到預訓練的內容預測網絡,并且將輸出與推理(reference)內容預測進行比較來導出整體內容損失。 通過將 x 饋送到預訓練網絡(稱為紋理網絡),并且在其特征圖上比較局部神經補丁來導出局部紋理損失。
高分辨率圖像修復的算法
給定一個帶有孔洞的高分辨率圖像,我們產生了多尺度輸入其中S是尺度的數量。s = 1是最粗糙的尺度,s = S是輸入圖像的原始分辨率。我們以迭代多尺度方式進行這一優化。
我們首先將輸入縮小到粗糙尺度,計算內容的推理(reference)。在實際操作中,我們在 upsample 到一個新尺度時,將寬度和高度加倍。 在每個尺度中,我們根據等式 1 更新,通過 upsample 設置優化初始,并通過 upsample 在尺度上設置內容 reference。我們因此迭代地取得高分辨率的修復結果。算法1 是對該算法的總結。

實驗過程
數據集
我們在兩個不同的數據集上評估了我們提出的方法:Paris StreetView 和ImageNet 。 不使用與這些圖像相關聯的標簽或其他信息。 Paris StreetView 包含 14,900 個訓練圖像和 100個測試圖像。 ImageNet 有 1,260,000 個訓練圖像,以及從驗證集隨機選取的 200 個測試圖像。 我們還選擇了20個含干擾項的圖像,以測試我們用于真實干擾項移除場景的算法。
量化比較
我們首先在 Paris StreetView 數據集上就低分辨率圖像(128×128)將我們的方法和基線方法進行了定量比較。表1中的結果表明,我們的方法實現了最高的數值性能。我們將這歸因于我們方法的性質——和 PatchMatch 相比,它能夠推斷圖像的正確結構,而和 Context Encoder 相比,它能夠從已知區域傳遞紋理細節。(圖3)我們優于PatchMatch的結果表明,內容網絡有助于預測合理的結構。我們勝過 Context Encoder 的結果表明,由紋理網絡執行的神經補丁合成方法的有效性。
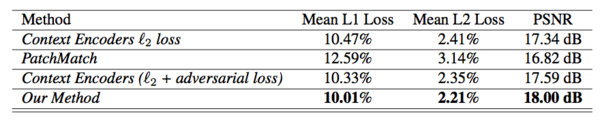
表1:在Paris StreetView數據集上的數值比較。PSNR值越高越好。

圖3:Context Encoder(損失)、Context Encoders(對抗性損失)和PatchMatch的比較。當從邊界向孔洞區域傳遞紋理時,我們的方法比Context Encoder(既使用損失也使用對抗性損失)表現更好。在推理正確結構時,我們的方法比PatchMatch表現更好。
內容網絡在聯合優化中的作用。我們比較了使用內容約束和不使用內容約束的修復結果。如圖4 所示,當不使用內容項來引導優化時,修復結果的結構出錯了。

圖4:(a)為原始輸入,(b)是不使用內容約束產生的修復結果,(c)是我們的結果。
高分辨率圖像修復

圖5是在ImageNet數據集上的比較結果。從上至下:原始輸入,PatchMatch,Context Encoder(同時使用和對抗性損失),我們的結果。所有圖像分辨率都是512×512(本文中已縮小以適應頁面顯示)。

圖6是在Paris StreetView數據集上的比較結果。從上至下:原始輸入,PatchMatch,Context Encoder(同時使用和對抗性損失),我們的結果。所有圖像分辨率都是512×512(本文中已縮小以適應頁面顯示)。
真實世界干擾項去除場景
最后,我們的算法很容易擴展為處理任意形狀的孔洞。 這是通過估計任意孔洞周圍的邊界平方,填充孔洞內的平均像素值,并通過裁剪圖像形成輸入,以使正方形邊界框處于輸入的中心,并將輸入調整為內容網絡輸入的大小。然后,我們使用已經訓練的內容網絡進行前向傳播。在聯合優化中,紋理網絡對自然中孔洞的形狀和位置沒有限制。這是分離將內容和紋理項分離的額外好處。由于 Context Encoder 僅限于方孔,我們在圖7中展示了和 PatchMatch 的對比結果。如圖所示,我們提出的聯合優化方法更好地預測了結構,并提供了清晰和逼真的結果。

圖7:隨意對象的去除。從左到右:原始輸入,對象遮擋,PatchMatch 結果,我們的結果。
結論
作者使用神經補丁合成提升了語義修復的現有技術。可以看到,當內容網絡給出較強的關于語義和全局結構的先驗信息時,紋理網絡在生成高頻細節方面非常強大。有一些場景復雜的情況,這種新的方法會產生不連續性和違背真實的圖像(圖8)。此外,速度仍然是這種算法的瓶頸。研究人員的目標是在未來的工作中解決這些問題。

圖8:這是兩個聯合優化法失敗的例子。
論文:使用多尺度神經補丁合成修補高分辨率圖像

摘要
對于帶有語義合理性和情境感知細節的自然圖像,深度學習的最新進展為填充這些圖像上的大面積孔洞帶來了樂觀的前景,并影響了諸如對象移除這樣的基本的圖像處理任務。雖然這些基于學習的方法在捕獲高級特征方面比現有技術明顯更有效,但由于存儲器限制和訓練困難,它們只能處理分辨率很低的輸入。即使對于稍大的圖像,修復的區域也會顯得模糊,而且可以看到令人不快的邊界。我們提出一種基于圖像內容和風格(style)約束聯合優化的多尺度神經補丁合成方法,不僅保留上下文結構,而且通過匹配和適應具有與深度分類網絡相似的中層特性的補丁,可以產生高頻細節。我們在 ImageNet 和 Paris Streetview 數據集上評估了我們的方法,并實現了最先進的修復精度。我們表明,相對于之前的方法,我們的方法可以產生更清晰和更連貫的結果,特別是對于高分辨率圖像來說。
論文地址:https://arxiv.org/pdf/1611.09969.pdf
Github 代碼:https://github.com/leehomyc/High-Res-Neural-Inpainting