Hive源碼編譯及閱讀修改調(diào)試

下載編譯
在git上下載合適的master分支,使用maven編譯。執(zhí)行編譯的目的在于,確保過程中生成的代碼(Thrift)已經(jīng)生成,這樣導(dǎo)入IDEA就不會出現(xiàn)有些類找不到的情況。
執(zhí)行源碼編譯分發(fā)命令,進入源碼根目錄執(zhí)行:
- mvn clean package -Phadoop-2 -DskipTests -Pdist
這里必須指定profile為hadoop-2來支持hadoop 2.x版本
1、后續(xù)更改完源碼后,還需執(zhí)行該命令來編譯打包。源碼更改后需評價其對Hive各模塊的影響(改動代碼多的話可通過pom的依賴來看),如果影響的模塊非常少,可以直接進入相應(yīng)的模塊進行上述命令的編譯打包,如果影響模塊很多,則直接在Hive源碼根目錄進行編譯打包。
2、打完包后,將受影響的包進行線上替換,重啟受影響的組件即可應(yīng)用上改后的代碼。如果在CDH環(huán)境,要注意所有YARN的節(jié)點都需進行包的替換,因為Hive的MR任務(wù)啟動后,節(jié)點上Container的啟動其核心包是加載的本地jar包,而不是HDFS上的jar包。
導(dǎo)入IDEA進行源碼閱讀修改
在Intellij里打開編譯后的工程,它是一個Maven工程,軟件會自動區(qū)分模塊并導(dǎo)入。導(dǎo)入后可以看到源碼,但我們會發(fā)現(xiàn),很多關(guān)于hadoop的地方標紅了,表示不可用,這是為什么呢?
這是因為版本依賴的原因,hive可編譯為依賴 hadoop1 或 hadoop2,在編譯源碼的時候就已提示過讓我們輸入支持哪個,否則不能編譯!
這里也一樣,需要我們選擇其依賴,才能正確的導(dǎo)入maven依賴包!
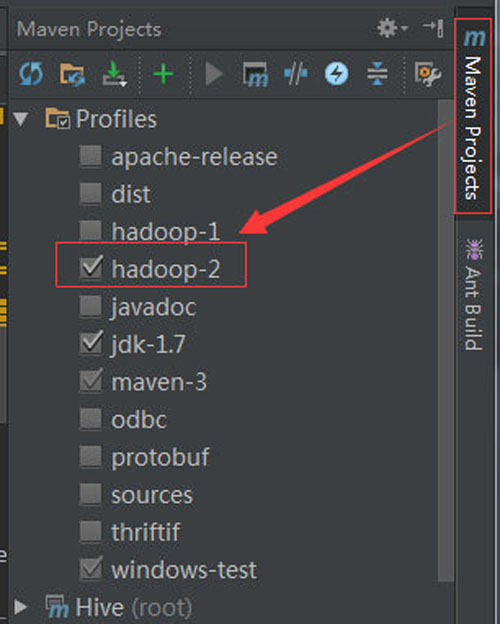
在Intellij的右側(cè),有個maven project的停靠欄,點擊它可以看到有個 profiles的子項,我們可以明顯看到hadoop-2是沒有勾選的,這里勾選上它,它所指定的相應(yīng)依賴就會被導(dǎo)入,源碼就不會標紅啦!就可以放心的改源碼啦!
如下圖
開啟調(diào)試之旅
調(diào)試前提
調(diào)試代碼時最好不執(zhí)行完全分布式任務(wù)(會分配到多臺節(jié)點機執(zhí)行的MR任務(wù)),代碼跑動控制在當前JVM范圍內(nèi)(可以是多線程的),否則代碼跟蹤超級麻煩。
如果需要執(zhí)行MR任務(wù),最好以local模式執(zhí)行,打開命令SET mapreduce.framework.name=local;
有些任務(wù)也不需要起MR,這樣更方便調(diào)試,盡可能不起MR:set hive.exec.mode.local.auto = true;,并調(diào)大hive.exec.mode.local.auto.tasks.max(默認4)和hive.exec.mode.local.auto.inputbytes.max(默認128M),當且僅當自動開啟本地模式設(shè)為true,并且輸入的文件數(shù)量和數(shù)據(jù)量大小分別都小于這兩個值的時候,才不會起MR任務(wù)。
1、Hive起完全分布式的MR任務(wù)也可追蹤,但是需要修改節(jié)點機上的MR啟動時Java參數(shù),而且Hive起一個MR任務(wù)時,只有當MR啟動后才能知道哪個節(jié)點機上啟動了該任務(wù),之后才能進行Remote debug連接,這在運行環(huán)境為完全分布式時會比較麻煩。但如果運行環(huán)境為偽分布式,那么追蹤可能會更方便些。
2、Hive調(diào)試,實際運行環(huán)境為偽分布式集群環(huán)境或完全分布式集群環(huán)境都可以。
Hive調(diào)試需保證調(diào)試代碼和運行環(huán)境的代碼一致,否則調(diào)試會出現(xiàn)斷點位置對不上的問題,影響我們調(diào)試。
如果是在Kerberos環(huán)境,運行Hive命令的用戶需具備Kerberos認證,因為調(diào)試跟正常執(zhí)行任務(wù)其實沒什么區(qū)別。調(diào)試端(如Windows上的IDEA)不需要認證,它只要能連通開啟的JVM端口即可。
調(diào)試原理
基于Sun Microsystem 的 Java Platform Debugger Architecture (JPDA) 技術(shù),它由兩個接口(分別是 JVM Tool Interface 和 JDI)、一個協(xié)議(Java Debug Wire Protocol)和兩個用于合并它們的軟件組件(后端和前端)組成,可以遠程調(diào)試任何基于JVM的程序。
要啟用調(diào)試,只需在軟件的JVM啟動時加載以下參數(shù):
- -Xdebug -Xrunjdwp:transport=dt_socket,address=5005,server=y,suspend=n
或
- -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
參數(shù)含義:

Hive Cli 調(diào)試
在運行環(huán)境開啟Hive Cli命令行,執(zhí)行: bin/hive --debug -hiveconf hive.root.logger=DEBUG,console,此時界面會顯示 Listening for transport dt_socket at address: 8000,表明遠程調(diào)試模式已開。
然后在IntelliJ里配置遠程調(diào)試模式,Run -> Debug -> Edit Configurations,然后點左上角 + 號按鈕,選擇 Remote,配好Host為運行Hive Cli命令的主機,Port為8000,然后起個方便識別的名字,點擊Debug就可以開始調(diào)試源碼了。
一旦這邊遠程連接上了集群環(huán)境的調(diào)試端口,集群那邊就會打日志并出現(xiàn)hive >這樣的輸入光標,在IDEA里打斷點,然后在Hive Cli里執(zhí)行HQL語句,我們就可以看到IDEA這邊的斷點信息,然后逐步調(diào)試。
HiveServer2 調(diào)試
以下以CDH集群環(huán)境做說明,路徑與你安裝的CDH路徑有關(guān),Apache開源環(huán)境找到對應(yīng)配置文件即可。
修改hiveserver2所在機器的/opt/cloudera/parcels/CDH/lib/hive/bin/hive-config.sh文件,在最后加上
- export HADOOP_OPTS="$HADOOP_OPTS -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005"
- export HADOOP_VERSION="2.6.0-cdh5.5.1"
其中HADOOP_VERSION由命令hadoop version可得到。
改完配置后在CM里重啟Hiveserver2,這時在HiveServer2所在機器上查看5005端口,會發(fā)現(xiàn)處于監(jiān)聽狀態(tài),然后利用Intellij如上面的debug一樣,即可連接上遠程的hiveserver2。
打好斷點,之后在某一節(jié)點上啟動beeline,連接上該hiveserver2,執(zhí)行hql,這邊就可以源碼追蹤。
1、注意端口別占用了,否則會報: JDWP No transports initialized, jvmtiError=AGENT_ERROR_TRANSPORT_INIT
2、如果整個Hive需要重啟,需把上面更改注釋掉,待Hive重啟完畢后,再把注釋改回來然后單獨重啟HiveServer2。這是因為Hive MetaStore啟動時也會用到該腳本,而MetaStore先啟動,會進入MetaStore的調(diào)試。之后啟動HiveServer2時就會出現(xiàn)端口占用的情況
Beeline 調(diào)試
以下以CDH集群環(huán)境做說明,自己的安裝環(huán)境尋找相應(yīng)配置即可
修改需要運行beeline的機器上的beeline腳本的執(zhí)行腳本,我的位置為:/opt/cloudera/parcels/CDH/lib/hive/bin/ext/beeline.sh,在腳本最后的export HADOOP_CLIENT_OPTS后加上 -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=5005。
如下:
![]()
改完后,在該機器上執(zhí)行beeline即可進入監(jiān)聽狀態(tài),IDEA進行遠程連接即可