微信分布式數據存儲協議對比——Paxos和Quorum
分布式系統是網絡化的計算機系統,海量數據的互聯網應用只能通過分布式系統協調大量計算機來支撐。微信后臺存儲大量使用了分布式數據存儲方式的NoSQL集群,比如核心業務:賬號、支付單據、關系鏈、朋友圈等。存儲設備出現異常是必然,分布式系統通過多節點分布及冗余,避免個別異常節點影響到系統的正常服務,同時提供平行擴展能力。微信自研的分布式存儲在發展的不同階段,分別依賴過Paxos和Quorum兩種方案維護一致性。Paxos和Quorum也是互聯網企業主要使用的分布式協議,這里向有興趣的讀者做些分布式算法的粗略介紹,以及為什么需要它們。
關于一致性
為什么需要Paxos或Quorum算法?分布式系統實現數據存儲,是通過多份數據副本來保證可靠,假設部分節點訪問數據失敗,還有其他節點提供一致的數據返回給用戶。對數據存儲而言,怎樣保證副本數據的一致性當屬分布式存儲最重要的問題。 一致性是分布式理論中的根本性問題,近半個世紀以來,科學家們圍繞著一致性問題提出了很多理論模型,依據這些理論模型,業界也出現了很多工程實踐投影。何為一致性問題?簡而言之,一致性問題就是相互獨立的節點之間,在可控的時間范圍內如何達成一項決議的問題。
強一致寫、多段式提交
強一致寫
解決這個問題最簡單的方法 ,就是強一致寫。在用戶提交寫請求后,完成所有副本更新再返回用戶,讀請求任意選擇某個節點。數據修改少節點少時,方案看起來很好,但操作頻繁則有寫操作延時問題,也無法處理節點宕機。
兩段式提交(2PC 、Three-Phase Commit)
既然實際系統中很難保證強一致,便只能通過兩段式提交分成兩個階段,先由Proposer(提議者)發起事物并收集Acceptor(接受者)的返回,再根據反饋決定提交或中止事務。
***階段:Proposer發起一個提議,詢問所有Acceptor是否接受;
第二階段:Proposer根據Acceptor的返回結果,提交或中止事務。如果Acceptor全部同意則提交,否則全部終止。
兩階段提交方案是實現分布式事務的關鍵;但是這個方案針對無反饋的情況,除了“死等”,缺乏合理的解決方案。 Proposer在發起提議后宕機,階段二的Acceptor資源將鎖定死等。如果部分參與者接受請求后異常,還可能存在數據不一致的腦裂問題。
三段式提交(3PC、Three-Phase Commit)
為了解決2PC的死等問題,3PC在提交前增加一次準備提交(prepare commit)的階段,使得系統不會因為提議者宕機不知所措。接受者接到準備提交指令后可以鎖資源,但要求相關操作必須可回滾。
但3PC并沒有被用在我們的工程實現上,因為3PC無法避免腦裂,同時有其他協議可以做到更多的特性又解決了死等的問題。

三段式提交,在二段式提交基礎上增加prepare commit階段
主流的Paxos算法
微信后臺近期開始主要推廣Paxos算法用于內部分布式存儲。Paxos是Leslie Lamport提出的基于消息傳遞的一致性算法,解決了分布式存儲中多個副本響應讀寫請求的一致性,Paxos在目前的分布式領域幾乎是一致性的代名詞(據傳Google Chubby的作者Mike Burrows曾說過這個世界上只有一種一致性算法, 那就是Paxos,其他算法都是殘次品)。Paxos算法在可能宕機或網絡異常的分布式環境中,快速且正確地在集群內部對某個數據的值達成一致,并且保證只要任意多數節點存活,都不會破壞整個系統的一致性。Paxos的核心能力就是多個節點確認一個值,少數服從多數,獲得可用性和一致性的均衡。

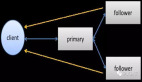
Paxos模型,節點間的交互關系
Paxos可以說是多節點交互的二段提交算法,Basic Paxos內的角色有Proposer(提議者)、Acceptor(接受提議者)、Learner(學習提議者),以提出Proposal(提議)的方式尋求確定一致的值。
***階段(Prepare):Proposer對所有Acceptor廣播自己的Proposal(值+編號)。Acceptor如果收到的Proposal編號是***的就接受,否則Acceptor必須拒絕。如果Proposer之前已經接受過某個Proposal,就把這個Proposal返回給Proposer。在Prepare階段Acceptor始終接受編號***的Proposal,多個Proposer為了盡快達成一致,收到Acceptor返回的Proposal編號比自己的大,就修改為自己的Proposal。因此為了唯一標識每個Proposal,編號必須唯一。如果Proposer收到過半數的Acceptor返回的結果是接受,算法進入第二階段。
第二階段(Accept):Proposer收到的答復中,如果過半數的Acceptor已經接受,Proposer把***階段的Proposal廣播給所有Acceptor。而大多Acceptor已經接受了其他編號更大的Proposal時,Proposer把這個Proposal作為自己的Proposal提交。Acceptor接到請求后,如果Proposal編號***則確認并返回結果給所有Proposer,如果Proposer得到多數派回復,則認為最終一致的值已經確定(Chosen)。Learner不參與提議,完成后學習這個最終Proposal。
嚴格證明是通過數學歸納法,本文只做了直觀判斷。Paxos確認這個值利用的是“抽屜原理”,固定數量的節點選取任意兩次過半數的節點集合,兩次集合交集必定有節點是重復的。所以***階段任何已經接受的提議,在第二階段任意節點宕機或失聯,都有某節點已經接受提議,而編號***的提議和確定的值是一致的。遞增的編號還能減少消息交互次數,允許消息亂序的情況下正常運行。就一個值達成一致的方式(Basic Paxos)已經明確了,但實際環境中并不是達成一次一致,而是持續尋求一致,讀者可以自己思考和推導,想深入研究建議閱讀Leslie Lamport的三篇論文《Paxos made simple》、《The Part-Time Parliament》、《Fast Paxos》。實現多值方式(原文為Multi Paxos),通過增加Leader角色統一發起提議Proposal,還能節約多次網絡交互的消耗。Paxos協議本身不復雜,難點在如何將Paxos協議工程化。
我們實現Paxos存儲做了一些改進,使用了無租約版Paxos分布式協議,參考Google MegaStore做了寫優化,并通過限制單次Paxos寫觸發Prepare的次數避免活鎖問題。雖然Paxos算法下只要多數派存在,就可以在分布式環境下達到嚴格的一致性。但是犧牲的性能代價可觀,在大部分應用場景中,對一致性的要求并不是那么嚴格,這個時候有不少簡化的一致性算法,比如Quorum。
簡化的Quorum(NWR)算法
Quorum借鑒了Paxos的思想,實現上更加簡潔,同樣解決了在多個節點并發寫入時的數據一致性問題。比如Amazon的Dynamo云存儲系統中,就應用NWR來控制一致性。微信也有大量分布式存儲使用這個協議保證一致性。Quorum最初的思路來自“鴿巢原理”,同一份數據雖然在多個節點擁有多份副本,但是同一時刻這些副本只能用于讀或者只能用于寫。

Quorum模型:微信改進的版本、數據分離結構
Quorum控制同一份數據不會同時讀寫,寫請求需要的副本數要求超過半數,寫操作時就沒有足夠的副本給讀操作;
Quorum控制同一份數據的串行化修改,因為副本數要求,同一份數據不會被兩個寫請求同時修改。
Quorum又被稱為NWR協議:R表示讀取副本的數量;W表示寫入副本的數量;N表示總的節點數量。
假設N=2,R=1,W=1,R+W=N=2,在節點1寫入,節點2讀取,無法得到一致性的數據;
假設N=2,R=2,W=1,R+W>N,任意寫入某個節點,則必須同時讀取所有節點;
假設N=2,W=2,R=1,R+W>N,同時寫入所有節點,則讀取任意節點就可以得到結果。
要滿足一致性,必須滿足R+W>N。NWR值的不同組合有不同效果,當W+R>N時能實現強一致性。所以工程實現上需要N>=3,因為冗余數據是保證可靠性的手段,如果N=2,損失一個節點就退化為單節點。寫操作必須更新所有副本數據才能操作完成,對于寫頻繁的系統,少數節點被寫入的數據副本可以異步同步,但是只更新部分節點,讀取則需要訪問多個節點,讀寫總和超過總節點數才能保證讀到***數據。可以根據請求類型調整BWR,需要可靠性則加大NR,需要平衡讀寫性能則調整RW。
微信有大量分布式存儲(QuorumKV)使用這個算法保證一致性,我們對這個算法做了改進,創造性地把數據副本分離出版本編號和數據存到不同設備,其中N=3(數據只有2份,版本編號有3份),在R=W=2時仍然可以保證強一致性。因為版本編號存放3份,對版本編號使用Quorum方式,通過版本編號協商,只有版本序號達成一致的情況下讀寫單機數據,從而在保證強一致性的同時實現高讀寫性能。實際數據只寫入一臺數據節點,使用流水日志的方式進行同步,并更新版本編號。但是我們的分布式存儲(QuorumKV)仍存在數據可靠性比Paxos低的問題,因為數據只寫一份副本,依靠異步同步。如果數據節點故障,故障節點上沒有同步到另一個節點,數據將無法訪問。版本節點故障時,如果Quorum協議沒有設置W=3,也可能無法訪問正確的數據節點副本。
后記
分布式存儲選用不同的一致性算法,和業務的具體情況相關。我們的分布式存儲在發展的不同階段,使用過不同的算法:業務的發展初期使用Quorum算法,成本壓力減少而業務穩定需求變大后,就開始使用Paxos算法。如果業務模型對數據一致性要求不高,使用Quorum則具有一定的成本和開發資源優勢。