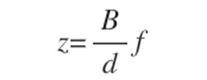卷積神經網絡CNN總結
從神經網絡到卷積神經網絡(CNN)
我們知道神經網絡的結構是這樣的:
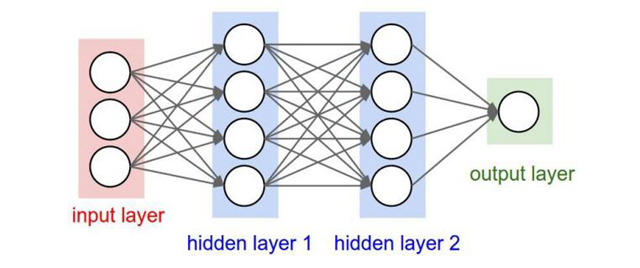
那卷積神經網絡跟它是什么關系呢?
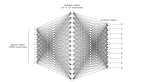
其實卷積神經網絡依舊是層級網絡,只是層的功能和形式做了變化,可以說是傳統神經網絡的一個改進。比如下圖中就多了許多傳統神經網絡沒有的層次。

卷積神經網絡的層級結構
- 數據輸入層/ Input layer
- 卷積計算層/ CONV layer
- ReLU激勵層 / ReLU layer
- 池化層 / Pooling layer
- 全連接層 / FC layer
1.數據輸入層
該層要做的處理主要是對原始圖像數據進行預處理,其中包括:
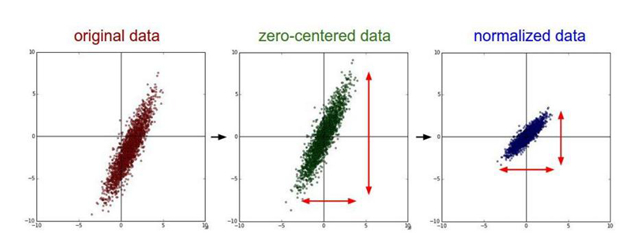
- 去均值:把輸入數據各個維度都中心化為0
- 歸一化:幅度歸一化到同樣的范圍
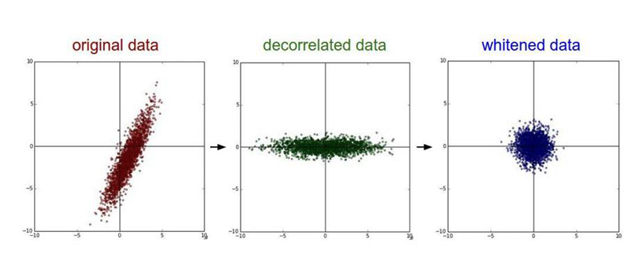
- PCA/白化:用PCA降維;白化是對數據各個特征軸上的幅度歸一化
去均值與歸一化效果圖:
去相關與白化效果圖:
2.卷積計算層
這一層就是卷積神經網絡最重要的一個層次,也是“卷積神經網絡”的名字來源。
在這個卷積層,有兩個關鍵操作:
- 局部關聯。每個神經元看做一個濾波器(filter)
- 窗口(receptive field)滑動, filter對局部數據計算
先介紹卷積層遇到的幾個名詞:
- 深度/depth(解釋見下圖)
- 步長/stride (窗口一次滑動的長度)
- 填充值/zero-padding
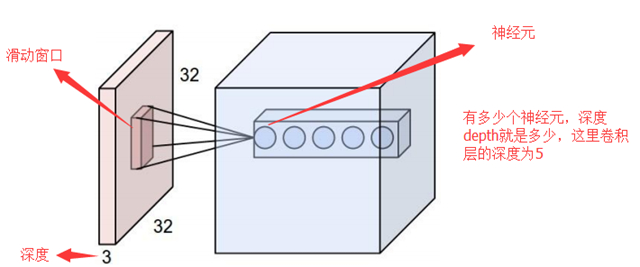
填充值是什么呢?以下圖為例子,比如有這么一個5*5的圖片(一個格子一個像素),我們滑動窗口取2*2,步長取2,那么我們發現還剩下1個像素沒法滑完,那怎么辦呢?
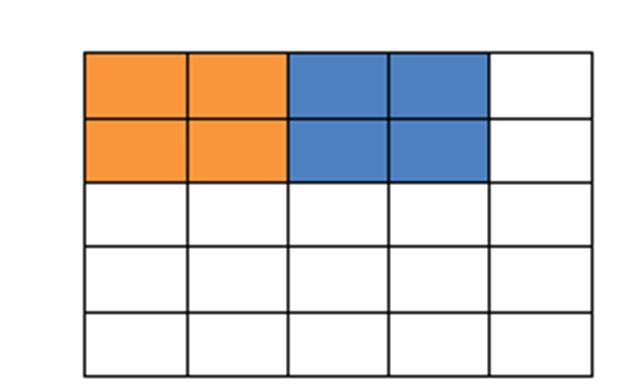
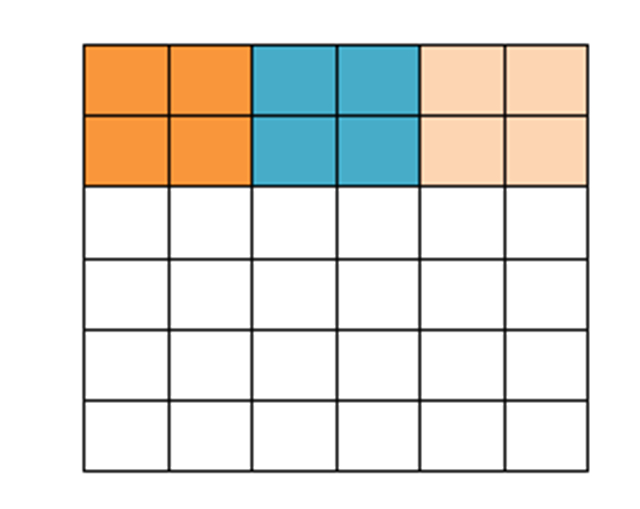
那我們在原先的矩陣加了一層填充值,使得變成6*6的矩陣,那么窗口就可以剛好把所有像素遍歷完。這就是填充值的作用。
卷積的計算(注意,下面藍色矩陣周圍有一圈灰色的框,那些就是上面所說到的填充值)
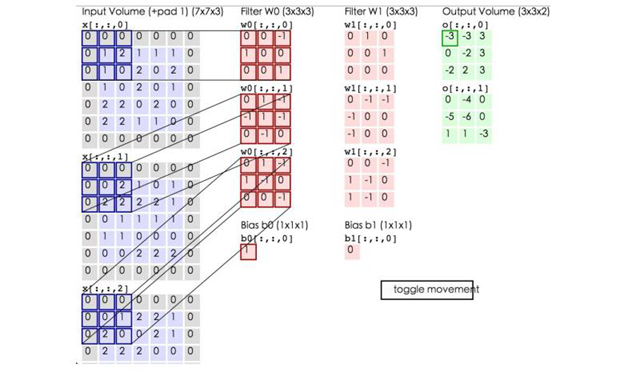
這里的藍色矩陣就是輸入的圖像,粉色矩陣就是卷積層的神經元,這里表示了有兩個神經元(w0,w1)。綠色矩陣就是經過卷積運算后的輸出矩陣,這里的步長設置為2。
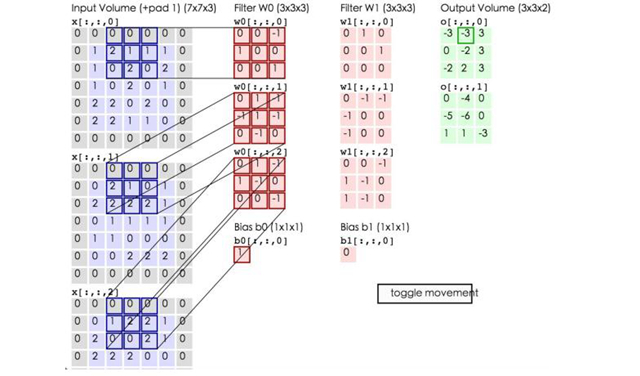
藍色的矩陣(輸入圖像)對粉色的矩陣(filter)進行矩陣內積計算并將三個內積運算的結果與偏置值b相加(比如上面圖的計算:2+(-2+1-2)+(1-2-2) + 1= 2 – 3 – 3 + 1 = -3),計算后的值就是綠框矩陣的一個元素。

下面的動態圖形象地展示了卷積層的計算過程:

參數共享機制
- 在卷積層中每個神經元連接數據窗的權重是固定的,每個神經元只關注一個特性
- 需要估算的權重個數減少: AlexNet 1億 => 3.5w
- 一組固定的權重和不同窗口內數據做內積: 卷積

3.激勵層
把卷積層輸出結果做非線性映射。
CNN采用的激勵函數一般為ReLU(The Rectified Linear Unit/修正線性單元),它的特點是收斂快,求梯度簡單,但較脆弱,圖像如下。
激勵層的實踐經驗:
①不要用sigmoid!不要用sigmoid!不要用sigmoid!
② 首先試RELU,因為快,但要小心點
③ 如果2失效,請用Leaky ReLU或者Maxout
④ 某些情況下tanh倒是有不錯的結果,但是很少
4.池化層
池化層夾在連續的卷積層中間, 用于壓縮數據和參數的量,減小過擬合。
簡而言之,如果輸入是圖像的話,那么池化層的作用就是壓縮圖像。

池化層用的方法有Max pooling 和 average pooling,而實際用的較多的是Max pooling。
這里就說一下Max pooling,其實思想非常簡單。
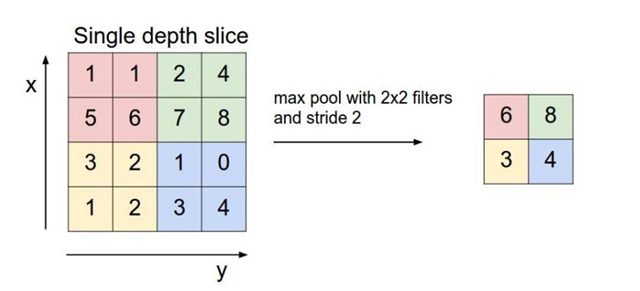
對于每個2*2的窗口選出最大的數作為輸出矩陣的相應元素的值,比如輸入矩陣第一個2*2窗口中最大的數是6,那么輸出矩陣的第一個元素就是6,如此類推。
5.全連接層
兩層之間所有神經元都有權重連接,通常全連接層在卷積神經網絡尾部。也就是跟傳統的神經網絡神經元的連接方式是一樣的:

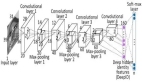
一般CNN結構依次為
1). INPUT
2). [[CONV -> RELU]*N -> POOL?]*M
3). [FC -> RELU]*K
4. FC
卷積神經網絡之訓練算法
1. 同一般機器學習算法,先定義Loss function,衡量和實際結果之間差距。
2. 找到最小化損失函數的W和b, CNN中用的算法是SGD(隨機梯度下降)。
卷積神經網絡之優缺點
優點
- 共享卷積核,對高維數據處理無壓力
- 無需手動選取特征,訓練好權重,即得特征分類效果好
缺點
- 需要調參,需要大樣本量,訓練最好要GPU
- 物理含義不明確(也就說,我們并不知道沒個卷積層到底提取到的是什么特征,而且神經網絡本身就是一種難以解釋的“黑箱模型”)
卷積神經網絡之典型CNN
- LeNet,這是最早用于數字識別的CNN
- AlexNet, 2012 ILSVRC比賽遠超第2名的CNN,比
- LeNet更深,用多層小卷積層疊加替換單大卷積層。
- ZF Net, 2013 ILSVRC比賽冠軍
- GoogLeNet, 2014 ILSVRC比賽冠軍
- VGGNet, 2014 ILSVRC比賽中的模型,圖像識別略差于GoogLeNet,但是在很多圖像轉化學習問題(比如object detection)上效果奇好
卷積神經網絡之 fine-tuning
何謂fine-tuning?
fine-tuning就是使用已用于其他目標、預訓練好模型的權重或者部分權重,作為初始值開始訓練。
那為什么我們不用隨機選取選幾個數作為權重初始值?原因很簡單,第一,自己從頭訓練卷積神經網絡容易出現問題;第二,fine-tuning能很快收斂到一個較理想的狀態,省時又省心。
那fine-tuning的具體做法是?
- 復用相同層的權重,新定義層取隨機權重初始值
- 調大新定義層的的學習率,調小復用層學習率
卷積神經網絡的常用框架
Caffe
- 源于Berkeley的主流CV工具包,支持C++,python,matlab
- Model Zoo中有大量預訓練好的模型供使用
Torch
- Facebook用的卷積神經網絡工具包
- 通過時域卷積的本地接口,使用非常直觀
- 定義新網絡層簡單
TensorFlow
- Google的深度學習框架
- TensorBoard可視化很方便
- 數據和模型并行化好,速度快
總結
卷積網絡在本質上是一種輸入到輸出的映射,它能夠學習大量的輸入與輸出之間的映射關系,而不需要任何輸入和輸出之間的精確的數學表達式,只要用已知的模式對卷積網絡加以訓練,網絡就具有輸入輸出對之間的映射能力。
CNN一個非常重要的特點就是頭重腳輕(越往輸入權值越小,越往輸出權值越多),呈現出一個倒三角的形態,這就很好地避免了BP神經網絡中反向傳播的時候梯度損失得太快。
卷積神經網絡CNN主要用來識別位移、縮放及其他形式扭曲不變性的二維圖形。由于CNN的特征檢測層通過訓練數據進行學習,所以在使用CNN時,避免了顯式的特征抽取,而隱式地從訓練數據中進行學習;再者由于同一特征映射面上的神經元權值相同,所以網絡可以并行學習,這也是卷積網絡相對于神經元彼此相連網絡的一大優勢。卷積神經網絡以其局部權值共享的特殊結構在語音識別和圖像處理方面有著獨特的優越性,其布局更接近于實際的生物神經網絡,權值共享降低了網絡的復雜性,特別是多維輸入向量的圖像可以直接輸入網絡這一特點避免了特征提取和分類過程中數據重建的復雜度。