遞歸卷積神經(jīng)網(wǎng)絡(luò)在解析和實(shí)體識(shí)別中的應(yīng)用
解析用戶(hù)的真實(shí)意圖
人類(lèi)語(yǔ)言與計(jì)算機(jī)語(yǔ)言不同,人類(lèi)的語(yǔ)言是沒(méi)有結(jié)構(gòu)的,即使存在一些語(yǔ)法規(guī)則,這些規(guī)則往往也充滿著歧義。在有大量用戶(hù)輸入語(yǔ)料的情況下,我們需要根據(jù)用戶(hù)的輸入,分析用戶(hù)的意圖。比如我們想看看一個(gè)用戶(hù)有沒(méi)有購(gòu)買(mǎi)某商品的想法,此時(shí)就必須使用解析算法,將用戶(hù)的輸入轉(zhuǎn)換成結(jié)構(gòu)化的數(shù)據(jù),并且在此結(jié)構(gòu)上提取出有用的信息。
NLP 解析算法的一般步驟是分詞、標(biāo)記詞性、句法分析。分詞和標(biāo)記詞性等,可以用條件隨機(jī)場(chǎng) (Conditional Random Field),隱馬爾可夫模型 (Hidden Markov Model) 等模型解決,近年來(lái)也有用神經(jīng)網(wǎng)絡(luò)來(lái)做的,相對(duì)比較成熟,所以暫時(shí)不討論。本文主要討論一下最主要的一步,句法分析。
兩種句法分析工具
目前的句法分析工具,主要分為依存文法 (Dependency Grammar) 與成分分析 (Constituency Relation) 兩大類(lèi)。
成分分析將文本劃分為子短語(yǔ)。
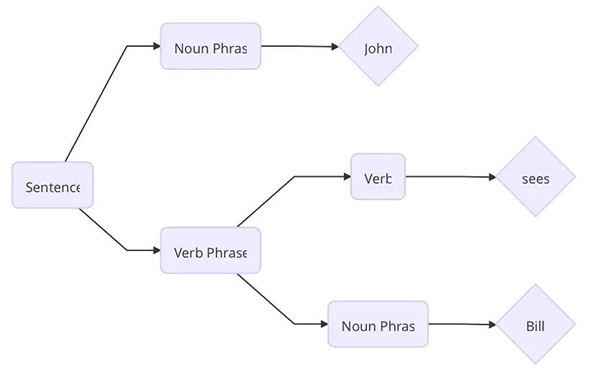
句子 John sees Bill 被劃分成了如上圖的結(jié)構(gòu)。首先單詞 Bill 是一個(gè)名詞短語(yǔ),sees 是一個(gè)動(dòng)詞,根據(jù)預(yù)先設(shè)置的語(yǔ)法規(guī)則,動(dòng)詞 + 名詞短語(yǔ)能構(gòu)成動(dòng)詞短語(yǔ),然后 名詞 + 動(dòng)詞短語(yǔ)能夠構(gòu)成一句完整的句子。
成分分析***的要數(shù)上下文無(wú)關(guān)文法 (Context Free Grammar) 及其各種變種,例如概率上下文文法 (Probabilistic Context Free Grammar)。
但是依存文法根據(jù)單詞之間的修飾關(guān)系將它們連接起來(lái)構(gòu)成一棵樹(shù),樹(shù)中的每個(gè)節(jié)點(diǎn)都代表一個(gè)單詞。
子節(jié)點(diǎn)的單詞是依賴(lài)于父節(jié)點(diǎn)的,每條邊標(biāo)準(zhǔn)了依賴(lài)關(guān)系的類(lèi)型。
單詞 John 是動(dòng)詞 sees 的主語(yǔ),單詞 Bill 是動(dòng)詞 sees 的賓語(yǔ)。
成分分析的缺點(diǎn)是搜索空間太大,構(gòu)建樹(shù)的時(shí)間往往和可供選擇的節(jié)點(diǎn)的數(shù)目相關(guān),成分分析需要在計(jì)算過(guò)程中不斷構(gòu)建新的節(jié)點(diǎn),而依存分析不需要構(gòu)建新的節(jié)點(diǎn)。自然語(yǔ)言中有歧義,例如上下文無(wú)關(guān)文法中有規(guī)則「C <- AB」,「D <- AB」, 那么在計(jì)算 AB 應(yīng)該合成什么節(jié)點(diǎn)的時(shí)候就出現(xiàn)了兩種選擇,多種歧義組合在一起,使成分分析的搜索空間爆炸增長(zhǎng),必須設(shè)計(jì)一些算法進(jìn)行剪枝等操作。而依存分析不會(huì)去創(chuàng)建節(jié)點(diǎn),因此沒(méi)有這些問(wèn)題。但是成分分析中保存的信息比依存分析更加多一點(diǎn),因此可以直接通過(guò)一些確定的規(guī)則將成分的樹(shù)轉(zhuǎn)化成依存樹(shù)。
句法分析算法
依存文法樹(shù)的構(gòu)建我們可以看成是一個(gè)狀態(tài)轉(zhuǎn)換的序列。當(dāng)前的狀態(tài)包括三部分,s 為當(dāng)前的棧,b 為剩余未解析的詞的數(shù)組,以及一個(gè)依存關(guān)系的集合 A。初始的狀態(tài)是
s=[ROOT], b=[w_1,...,w_n], A=∅ 。終止的狀態(tài)是 b 為空。S 只有一個(gè)節(jié)點(diǎn) ROOT , 解析出來(lái)的樹(shù)就是集合 A 。定義 s_i 為棧頂?shù)?i 個(gè)節(jié)點(diǎn)。b_i 為第 i 個(gè)未解析的詞。可以定義如下的狀態(tài)轉(zhuǎn)移:
- LEFT-ARC(l): 添加一個(gè) s_1—>s_2 的標(biāo)記為 l 的依賴(lài)關(guān)系,并且將 s_2 從棧里面移除。
- RIGHT-ARC(l): 添加一個(gè) s_2—>s_1 的標(biāo)記為 l 的依賴(lài)關(guān)系,并且將 s_1 從棧里面移除。
- SHIFT: 將 b_1 從未解析詞的數(shù)組中移出,放入棧。
假設(shè)我們需要解析句子「He wants a Mac.」.
解析的過(guò)程如下:
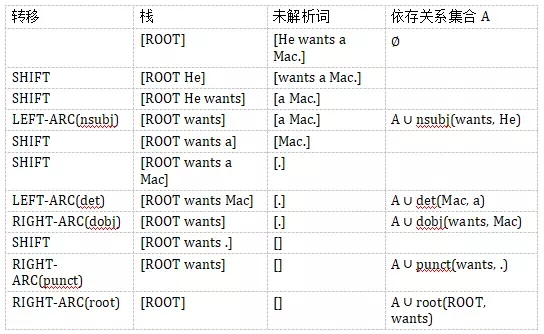
最終得到樹(shù)
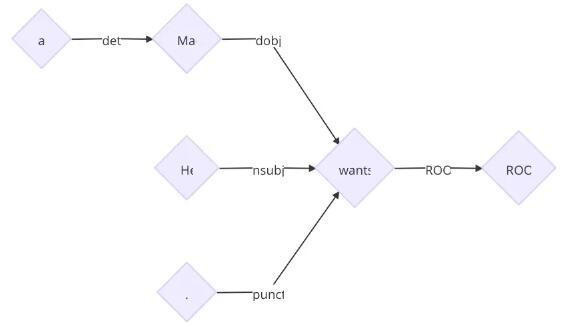
在每個(gè)狀態(tài)下,我們都有很多可選的轉(zhuǎn)移。關(guān)于如何選出正確的轉(zhuǎn)移,一般有貪心或者搜索兩種策略。目前的結(jié)果表明,盡管貪心比搜索的結(jié)果稍微差一點(diǎn),但是解析的速度快非常多,因此,日常使用基本采用貪心算法。
傳統(tǒng)解析算法的困境
傳統(tǒng)的解析算法需要根據(jù)當(dāng)前的狀態(tài)以及預(yù)先設(shè)置好的規(guī)則提取出特征。比如當(dāng)前棧頂?shù)那皟蓚€(gè)詞,當(dāng)前前幾個(gè)未解析的詞等。
但是這些特征有如下問(wèn)題:
- 稀疏。這些特征尤其是詞法特征,非常稀疏。依存文法的分析依賴(lài)于詞之間的關(guān)系,有可能兩個(gè)詞距離非常遠(yuǎn),那么僅僅提取棧頂前兩個(gè)詞作為特征已經(jīng)無(wú)法滿足需要,必須使用更高維度的特征,一旦維度高,勢(shì)必使得特征非常稀疏。
- 不完整。人的經(jīng)驗(yàn)是有偏差的,專(zhuān)家概括的特征提取規(guī)則,總是不完整的。
- 解析算法的絕大部分時(shí)間花費(fèi)在了提取特征中。據(jù)統(tǒng)計(jì)百分之九十幾的時(shí)間花費(fèi)是特征提取。
此時(shí)便需要神經(jīng)網(wǎng)絡(luò)出場(chǎng)來(lái)給我們估計(jì)哪個(gè)是***的狀態(tài)轉(zhuǎn)移了。
遞歸神經(jīng)網(wǎng)絡(luò) (Recursive Neural Network)
詞嵌入是將單詞表示成低維的稠密的實(shí)數(shù)向量。自從詞向量技術(shù)的提出,到目前為止已經(jīng)有很多方法來(lái)得到句法和語(yǔ)義方面的向量表示,這種技術(shù)在 NLP 領(lǐng)域發(fā)揮著重要的作用。
如何用稠密的向量表示短語(yǔ),這是使用詞向量的一個(gè)難題。在成分分析中,業(yè)界使用遞歸神經(jīng)網(wǎng)絡(luò) (Recursive Neural Network, RNN) 來(lái)解決這個(gè)問(wèn)題。RNN 是一種通用的模型,用來(lái)對(duì)句子進(jìn)行建模。句子的語(yǔ)法樹(shù)中的左右子節(jié)點(diǎn)通過(guò)一層線性神經(jīng)網(wǎng)絡(luò)結(jié)合起來(lái),根節(jié)點(diǎn)的這層神經(jīng)網(wǎng)絡(luò)的參數(shù)就表示整句句子。RNN 能夠給語(yǔ)法樹(shù)中的所有葉子節(jié)點(diǎn)一個(gè)固定長(zhǎng)度的向量表示,然后遞歸地給中間節(jié)點(diǎn)建立向量的表示。
假設(shè)我們的語(yǔ)法二叉樹(shù)是 p_2—>ap_1 , p_1—>bc ,即 p_2 有子節(jié)點(diǎn)a、p_1,p_1 有子節(jié)點(diǎn) b、c 。那么節(jié)點(diǎn)表示成
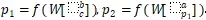
其中 W 是 RNN 的參數(shù)矩陣。為了計(jì)算一個(gè)父節(jié)點(diǎn)是否合理,我們可以用一個(gè)線性層來(lái)打分, score(p_i)=vp_i 。v是需要被訓(xùn)練的參數(shù)向量。在構(gòu)建樹(shù)的過(guò)程中,我們采用這種方法來(lái)評(píng)估各種可能的構(gòu)建,選出***的構(gòu)建。
基于神經(jīng)網(wǎng)絡(luò)的依存解析
但是 RNN 只能處理二元的組合,不適合依存分析。因?yàn)橐来娣治龅哪硞€(gè)節(jié)點(diǎn)可能會(huì)有非常多的子節(jié)點(diǎn)。于是有學(xué)者提出用遞歸卷積神經(jīng)網(wǎng)絡(luò) (Recursive Convolutional Neural Network, RCNN) 來(lái)解決這個(gè)問(wèn)題。通過(guò)使用 RCNN,我們能夠捕捉到單詞和短語(yǔ)的句法和組合語(yǔ)義的表示。RCNN 的架構(gòu)能夠處理任意 k 分叉的解析樹(shù)。RCNN 是一個(gè)通用的架構(gòu),不僅能夠用于依存分析,還能對(duì)于文章的語(yǔ)義進(jìn)行建模,將任意長(zhǎng)度的文本轉(zhuǎn)化成固定長(zhǎng)度的向量。
1. RCNN 單元
對(duì)于依存樹(shù)上的每個(gè)節(jié)點(diǎn),我們用一個(gè) RCNN 單元來(lái)表示改節(jié)點(diǎn)與其子節(jié)點(diǎn)之間的關(guān)系,然后用一層 Pooling 層來(lái)獲得***信息量的表示。每個(gè) RCNN 單元又是其父節(jié)點(diǎn)的 RCNN 單元的輸入。
下圖展示的是 RCNN 如何來(lái)表示短語(yǔ)「He wants a Mac」。
- graph LR
- a{"W(a)"} --> RCNN_UNit_mac[RCNN UNit]
- mac{"W(mac)"} --> RCNN_UNit_mac[RCNN Unit]
- RCNN_UNit_mac --> X_mac{"X(mac)"}
- He{"W(He)"} --> RCNN_UNit_wants["RCNN Unit"]
- wants{"W(wants)"} --> RCNN_UNit_wants
- X_mac --> RCNN_UNit_wants
- P{"W(.)"} --> RCNN_UNit_wants
- RCNN_UNit_wants --> X_wants{"X(wants)"}
- X_wants --> RCNN_Unit_root["RCNN Unit"]
- root{"W(root)"} --> RCNN_Unit_root
- RCNN_Unit_root --> X_root{"X(root)"}
RCNN 單元內(nèi)部結(jié)構(gòu)如下圖所示:
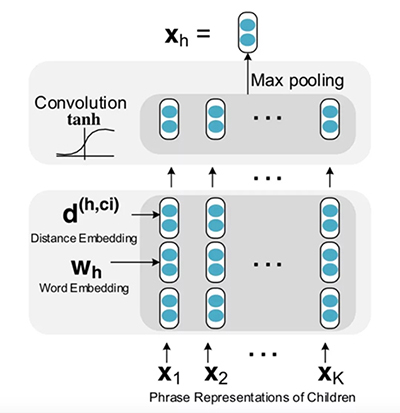
2. RCNN 單元的構(gòu)建
- 首先對(duì)于每個(gè)詞,我們需要將其轉(zhuǎn)換成向量。這一步一開(kāi)始可以用已經(jīng)訓(xùn)練好的向量,然后在訓(xùn)練的時(shí)候根據(jù)反向傳播來(lái)進(jìn)行更新。
- 距離嵌入 (Distance Embedding),除了詞需要嵌入,我們還需要將一個(gè)詞和該詞的子節(jié)點(diǎn)之間的距離進(jìn)行編碼。很直覺(jué)的是距離近的詞更有可能發(fā)生修飾關(guān)系。例如上面的例子中,Mac 到 a 的距離是-1,到 wants 的距離是 -2。距離嵌入編碼了子樹(shù)的更多信息。
- ***將詞向量和距離向量作為卷積層的輸入。
與一般的解析樹(shù)不同,依存分析的樹(shù)的每個(gè)節(jié)點(diǎn)都有兩個(gè)向量表示。一個(gè)是該節(jié)點(diǎn)的單詞的詞向量表示w,另一個(gè)是該節(jié)點(diǎn)的短語(yǔ)向量表示x。
對(duì)于父節(jié)點(diǎn) h,以及某個(gè)子節(jié)點(diǎn) c_i,用卷積隱層來(lái)計(jì)算他們組合起來(lái)的表示向量
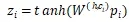
其中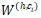 是組合矩陣,
是組合矩陣,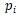 是
是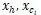 以及距離嵌入
以及距離嵌入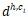 連接起來(lái)的向量。tanh是用來(lái)當(dāng)做激發(fā)層。
連接起來(lái)的向量。tanh是用來(lái)當(dāng)做激發(fā)層。
在計(jì)算卷積后,對(duì)于有 K 個(gè)子節(jié)點(diǎn)的節(jié)點(diǎn)而言,我們得到 K 個(gè)向量
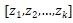
對(duì)于 Z 的每一行我們用 Max Pooling 選出最有用的信息。
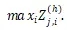
最終得到了該短語(yǔ)的向量表示。
得到向量表示后,計(jì)算哪個(gè)子樹(shù)更加合理,這時(shí)就也可以用線性層來(lái)打分了。
3. 訓(xùn)練
對(duì)于 RCNN 可以用***間距的標(biāo)準(zhǔn)來(lái)訓(xùn)練。我們選取打分***的解析樹(shù)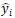 和給定的標(biāo)準(zhǔn)解析樹(shù)
和給定的標(biāo)準(zhǔn)解析樹(shù)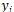 。定義兩棵樹(shù)之間的距離
。定義兩棵樹(shù)之間的距離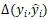 為樹(shù)中依賴(lài)標(biāo)記不一致的節(jié)點(diǎn)的數(shù)目。損失函數(shù)就是
為樹(shù)中依賴(lài)標(biāo)記不一致的節(jié)點(diǎn)的數(shù)目。損失函數(shù)就是
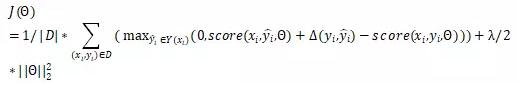
其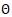 是神經(jīng)網(wǎng)絡(luò)的參數(shù),D是訓(xùn)練集,score如前面的定義,采用
是神經(jīng)網(wǎng)絡(luò)的參數(shù),D是訓(xùn)練集,score如前面的定義,采用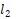 正則項(xiàng)
正則項(xiàng)
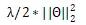
最小化損失的時(shí)候,正確的樹(shù)的打分被提高,錯(cuò)誤的樹(shù)的打分被降低。
實(shí)體識(shí)別
在使用依存分析得到解析樹(shù)后,我們就能從樹(shù)中提取出任意我們想要的短語(yǔ)。
比如我們想要提取出「wants sth」的短語(yǔ)。就可以用如下的算法得到。
- def want_phrase(sentence):
- result = defaultdict(list)
- for token in sentence: # 遍歷所有的token
- if token.head.lemma == 'want' and token.dep == dobj:
- # 如果當(dāng)前token的依賴(lài)指向want及其變形,而且依賴(lài)的關(guān)系是dobj。那么這是潛在的目標(biāo)短語(yǔ)
- result[token.head].append(token)
- for token in sentence: # 遍歷所有的token
- if token.head in result and token.text == "n't" and token.dep == neg:
- # 如果當(dāng)前的token 是 n't, 依賴(lài)指向的詞在潛在的目標(biāo)短語(yǔ)中,而且依賴(lài)關(guān)系是neg,其實(shí)表示的意思是不想要,因此需要從目標(biāo)短語(yǔ)的集合中剔除。
- del result[token.head] # 這是不喜歡的情況
- return result
結(jié)語(yǔ)
本文介紹了如何在傳統(tǒng)的解析算法中用上深度學(xué)習(xí)的技術(shù)。在實(shí)踐中,深度學(xué)習(xí)減少了數(shù)據(jù)工程師大量的編碼特征的時(shí)間,而且效果比人工提取特征好很多。在解析算法中應(yīng)用神經(jīng)網(wǎng)絡(luò)是一個(gè)非常有前景的方向。
【本文是51CTO專(zhuān)欄機(jī)構(gòu)“機(jī)器之心”的原創(chuàng)文章,微信公眾號(hào)“機(jī)器之心( id: almosthuman2014)”】