













安全領域中機器學習的對抗和博弈
0x00 背景
最近,偶然看到一篇論文講如何利用機器學習從加密的網絡流量中識別出惡意軟件的網絡流量。一開始認為這個價值很高,畢竟現在越來越多的惡意軟件都開始使用TLS來躲避安全產品的檢測和過濾。但是看完論文之后又有些失望,雖然文章的實驗結果非常漂亮,但是有一點治標不治本的感覺,機器學習又被拿來作為一個噱頭。
回顧過去的幾年,機器學習在安全領域有不少應用,但其處境卻一直比較尷尬:一方面,機器學習技術在業內已有不少成功的應用,大量簡單的重復性勞動工作可以很好的由機器學習算法解決。但另一方面,面對一些“技術性”較高的工作,機器學習技術卻又遠遠達不到標準。
和其他行業不同,安全行業是一個比較敏感的行業。比如做一個推薦系統,效果不好的最多也就是給用戶推薦了一些他不感興趣的內容,并不會造成太大損失;而在安全行業,假如用機器學習技術做病毒查殺,效果不好的話后果就嚴重了,無論是誤報或漏報,對客戶來說都會造成實際的或潛在的損失。
與此同時,安全行業也是一個與人博弈的行業。我們在其他領域采用機器學習算法時,大部分情況下得到數據都是“正常人”在“正常的行為”中產生的數據,因此得到的模型能夠很好的投入實際應用中。而在安全領域,我們的實際對手都是一幫技術高超、思路猥瑣的黑客,費盡心思構建的機器學習模型在他們眼中往往是漏洞百出、不堪一擊。
如何讓機器學習從學術殿堂真正走進實際應用,是每個安全研究人員值得思考的問題。本文從我所了解的一些案例和研究成果談談個人的看法和思考。
0x01 從加密的網絡流量中識別惡意軟件?
既然文章的開頭提到了從加密的網絡流量中識別惡意軟件,我們先來看看這個論文的作者是如何考慮這個問題的,他們發現,在握手階段(該過程是不加密的),惡意軟件所表現出的特征與正常的應用有較大區別。典型的TLS握手過程如下圖所示:

在握手的第一階段,客戶端需要告訴服務端自身所支持的協議版本、加密和壓縮算法等信息,在這個過程中,正常的應用(用戶能夠按時更新)使用高強度加密算法和最新的TLS庫,而惡意軟件所使用的往往是一些較老版本協議或強度較低的加密算法。以此作為主要特征,加上網絡流量本身的信息如總字節數大小、源端口與目的端口、持續時間以及網絡流中包的長度和到達次序等作為輔助特征,利用機器學習算法即可訓練得到一個分類模型。
看完這段描述,我的內心是崩潰的,因為該方法是把TLS握手階段的信息作為主要特征來考慮的。道高一尺,魔高一丈。以其人之道,還治其人之身,這句話點中了機器學習的死穴,我相信凡是看到這個篇論文的黑客都會想到:以后寫木馬的時候一定要采用最新版本的TLS庫,和服務器通信時采用加密強度較高的算法,盡量選取和正常應用類似的參數……做到以上幾點,論文中提出的方法就可以當成擺設了。
0x02 域名生成算法中的博弈
早期的一些DGA算法所產生的域名有著比較高的辨識度,例如下面這些域名

給我們的直觀感受就是英文字母隨機出現,而且不是常見的單詞或拼音的組合,而且很難“念”出來。事實上這些特征可以用馬爾可夫模型和n-gram分布很好的描述出來,早就有相應的算法實現,識別的效果也非常不錯。然而,很快就出現了一些升級版的DGA算法,如下面的這個域名
indianbrewedsmk.rutwistedtransistoreekl.biz
這無非就是隨機找幾個單詞,然后拼湊在一起構成的域名,但是卻完美的騙過了我們剛才提到的機器學習方法,因為這個域名無論從馬爾可夫模型或是n-gram分布的角度來看,都和正常的域名沒有太大的區別。唯一可疑的地方就是這個域名的長度以及幾個毫無關聯拼湊在一起的單詞,所以額外從這兩個角度考慮仍然可以亡羊補牢。
更有甚者,在今年的BSidesLV 2016上,有人提出了一種基于深度學習的DGA算法——DeepDGA,將Alexa上收錄的知名網站域名作為訓練數據,送入LSTM模型和生成對抗網絡(GAN, Generative Adversarial Networks)訓練,最終生成的隨機域名效果拔群。如下圖所示(左側是給定的輸入)

從字符的分布情況上來看,也與正常網站的域名基本一致
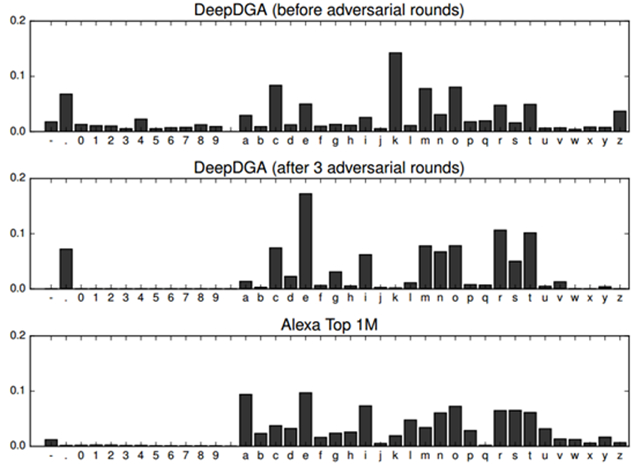
隨著深度學習技術的普及,或許在不久的將來安全研究人員就可以“驚喜的”發現某個勒索軟件家族開始采用這種高端的域名生成算法了……
0x03 來自恐怖分子的垃圾郵件
事實上類似域名生成算法的博弈早就出現了,2003年美國打擊塔利班武裝時,從一名恐怖分子手中繳獲了一臺筆記本電腦,發現里面用于通信的電子郵件的風格都是典型的垃圾郵件,而真正傳遞的消息暗藏于這樣的垃圾郵件中。因為面對NSA這樣無孔不入的情報機構,越是遮遮掩掩,越是采用高強度的加密,反而越容易被盯上。同樣因為NSA的無孔不入,他們每天需要處理的數據量也是天文數字,仔細檢查所有數據是不可能的,必須有所取舍,而這其中有一類數據恰恰是被NSA所忽視的,那就是每天成千上萬的垃圾郵件。在機器學習算法大行其道的今天,各大郵件服務提供商早就配備了一套成熟的垃圾郵件檢測系統,無論是采用邏輯回歸算法或是SVM算法,只要加上幾句諸如優惠代開各類發票或是想免費擁有自已的xxx這樣的垃圾郵件標配,妥妥的直接過濾掉。如果一封郵件都被郵件服務提供商認定為垃圾郵件,NSA又有什么理由去進一步懷疑呢?
退一步講,如果NSA想找出混在垃圾郵件中的有價值情報該怎么做呢?設關鍵詞嗎,上更復雜的機器學習算法嗎?要是恐怖分子采用類似“藏頭詩”這樣的信息隱藏手法怎么辦?
有的同學說還可以通過郵件的通連關系啊,如果你聽說過“死郵件”就不會這么想了。兩人共用一個賬號,利用郵箱的草稿箱傳遞消息,完全沒有郵件的發送與接收等通連關系,這又是不按套路出牌。
0x04 容易被騙的圖像識別
近幾年來,如果你稍有關注圖像識別領域,就知道基于深度學習技術的圖像識別技術在各大圖像識別比賽中大放異彩,甚至在某些任務上超過了人類。雖然目前人們仍然不能很好的解釋為什么深度學習技術如此有效,但這依然阻擋不住眾多數據科學家們孜孜不倦的搭建模型、調優參數。
但正當一票又一票研究小組努力“刷榜”的時候,另一些人總是能看的更遠一些。谷歌的Szegedy研究員就發現,基于深度學習的圖像識別技術可能并不如我們相像的那么靠譜,利用一些簡單的trick即可將其輕松欺騙。如下圖所示:

這兩幅圖在我們正常人眼中并沒有太大區別,但是對圖像識別系統,左圖能夠正確的識別為熊貓,右圖卻識別成了長臂猿,而且是99.3%的置信度
而更為詭異的是一些在我們人類看起來毫無意義的圖片,卻被圖像識別系統“正確”的識別了出來。比如下面這些例子

0x05 一起躺槍的自動駕駛
關于自動駕駛汽車的安全問題,國內外眾多安全公司和研究人員已經做了很多次詳細的分析和現場演示。例如在今年的ISC 2016上,來自浙大的徐文淵教授團隊和360汽車信息安全實驗室共同演示的針對特斯拉Model S汽車自動駕駛技術的攻擊,通過干擾特斯拉汽車的三種傳感器(超聲波傳感器、毫米波雷達和前置高清攝像頭),可以實現強制停車、誤判距離、致盲等多種不安全的情況。
以上都是黑客主動發起的攻擊,自動駕駛自身也存在著缺陷。今年5月發生在美國發生的自動駕駛系統致人死亡的案例也引發了社會的大量關注:
按照特斯拉的解釋,這起事故發生時,車主布朗正駕駛Model S行駛在一條雙向、有中央隔離帶的公路上,自動駕駛處于開啟模式,此時一輛牽引式掛車與Model S垂直的方向穿越公路。特斯拉表示,在強烈的日照條件下,駕駛員和自動駕駛系統都未能注意到牽引式掛車的白色車身,因此未能及時啟動剎車系統。而由于牽引式掛車正在橫穿公路,且車身較高,這一特殊情況導致Model S從掛車底部通過時,其前擋風玻璃與掛車底部發生撞擊,導致駕駛員不幸遇難。
正如這起事件暴露出來的問題,當車身周圍傳感器和車前的毫米波雷達都失靈時(當然該案例中這傳感器和毫米波雷達并未失靈,而是由于毫米波雷達安裝過低,未能感知到底盤較高的卡車),唯一能依靠的輸入就是車窗前方的高清攝像頭。我們來看看事發當時的街景現場
以及被撞的卡車樣式(注意白色車身上什么標致都沒有)
由于車前的高清攝像頭為長焦鏡頭,當白色拖掛卡車進入視覺區域內的時候,攝像頭只能看到懸浮在地面上的卡車中部,而無法看見整個車輛,加上當時陽光強烈(藍天白云),使得自動駕駛統無法識別出障礙物是一輛卡車,而更像是飄在天上的云。再加上當時特斯拉車主正在玩游戲,完全沒有注意到前方的這個卡車,最終導致悲劇發生。
結合剛才的圖像識別對抗樣本和浙大徐文淵教授團隊的研究成果,我們完全有可能設計一個讓自動駕駛系統發生車禍的陷阱,例如在某個車輛上噴涂吸收雷達波的涂料以及帶有迷惑性的圖案,讓自動駕駛系統無法識別出前方的物體;再比如,找個夜深人靜的夜晚在道路標識上加一些“噪音”,人類可以正常識別,而自動駕駛系統卻會誤判等等。
0x06 邪惡的噪音與隱藏的指令
除了容易被騙的圖像識別系統,我們每個人手機上的語音助手同樣不靠譜,也許未來某天你正在使用語音助手時,旁邊突然傳來一串奇怪的聲音,你的手機就詭異的打開了某個掛馬網站或者給一個完全不認識的人轉賬。
來自加州大學伯克利分校的Carlini等人發現一些語言助手如Google Now和Siri都有可能理解一些人類無法辨識的“噪音”,并將其解析為指令進行執行。其實原理并不難理解,人工生成這種邪惡的噪音流程如下
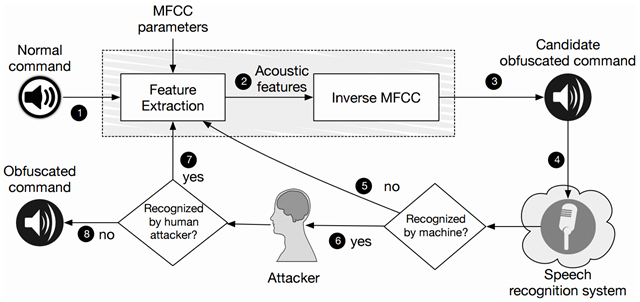
如圖所示,這是一個反復迭代的過程。我們首先通過抽取正常語音中關鍵特征,再做一次“逆向特征”合成語音并加入一些噪音作為候選,并將其分別給語音識別系統和正常人播放試聽,直到得到一個語音識別系統可以識別而人類無法辨識的邪惡噪音。
0x07 思考與對策
看完上文中提到的這些案例和分析,相信同學們有自己看法和認識。我也簡單談談我個人的一些思考。
最基本的一點是不要迷信機器學習,不要覺得機器學習是解決一切問題的銀彈。有的同學總覺得自己懂機器學習,那些靠人工上規則的辦法就是low,這種就是典型的學術思維,真正在業務系統中純粹靠機器學習算法硬上的遲早是要栽跟頭的。只有拋開這種觀念,從實際角度出發才能想出切實可行的方法。
盡量從多個數據來源或者多個特征維度綜合分析。以隨機域名生成算法為例,單靠域名本身的特征很難判斷其是否為C&C域名時,就應該從多個數據渠道入手進一步分析,如惡意軟件家族的域名關聯關系以及和某個可疑進程的通信行為等。
要有未雨綢繆的思維,在用機器學習算法解決一個問題的同時,應該從黑客猥瑣的角度思考如何攻擊這個算法,而不是簡單的回避,為了解決問題而解決問題。
本文提到了對抗樣本現象(圖像識別、語音識別都有涉及),目前學術界稱之為生成對抗網絡(GAN, Generative Adversarial Networks),雖然目前還沒有實際的攻擊案例,但特斯拉的車禍其實已經敲響了警鐘。就像著名黑客Barnaby Jack在Black Hat USA 2010上演示的針對ATM機的攻擊,當時人們覺得非常科幻,現實中不一定存在這樣的威脅,而今年發生的幾起黑客攻擊ATM機事件(臺灣第一銀行ATM機遭黑客入侵 吐出7000萬臺幣、泰國ATM機被入侵導致1200萬泰銖被盜)才讓人們真正意識到原來這些看似只在電影的中發生的情節在真實世界中同樣存在。
當黑客都開始研究機器學習技術了,我們又有什么理由落后呢?













