做數據分析時,R 用戶如何學習 Python?
本文是幫助 R 用戶增強技能和為數據科學進階而學習 Python (從零開始)。畢竟,R 和 Python 是數據科學從業者必需掌握的兩門最重要的編程語言。

Python 是一門功能強大和多用途的編程語言,在過去幾年取得驚人發展。它過去用于 Web 開發和游戲開發,現在數據分析和機器學習也要用到它。數據分析和機器學習是 Python 應用上相對新的分支。
作為初學者,學習 Python 來做數據分析是比較痛苦的。為什么?
在谷歌上搜索“Learn Python ”,你會搜到海量教程,但內容只是關于學習 Python 做 Web 開發應用。那你如何找到方法?
在本教程,我們將探討 Python 在執行數據操作任務上的基礎知識。同時,我們還將對比在 R 上是如何操作的。這種并行比較有助于你將 R 和 Python 上的任務聯系起來。***,我們將采用一個數據集來練習我們新掌握的 Python 技能。
注意:閱讀這篇文章時***具備一定的 R 基礎知識。
內容概要
- 為什么學習 Python(即使你已經懂 R )
- 理解 Python 的數據類型和結構(與 R 對比)
- 用 Python 寫代碼(與 R 對比)
- 用一個數據集實踐 Python
為什么學習 Python(即使你已經懂R)
毫無疑問,R 在它自身的領域是極其強大的,實際上,它最初是用來做統計計算和操作。強大的社區支持使得初學者可以很快掌握 R .
但是, Python 正迎頭趕上,無論成熟公司還是初創公司對Python 的接受程度要遠遠大于 R 。
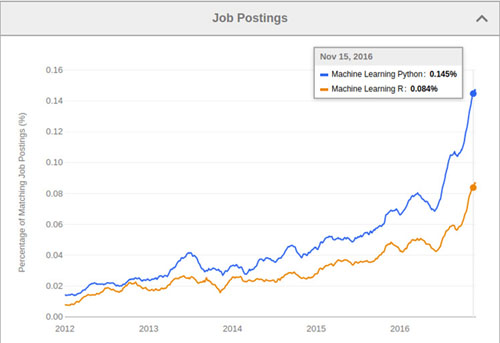
根據 indeed.com 提供的數據(2016年1月至2016年12月),“用 Python 做機器學習”的招聘信息數量要比“用 R 做機器學習” 增長快得多(約 123%)。這是因為:
Python 以更好的方式支持機器學習覆蓋的全部范圍。
Python 不僅支持模型構建,而且支持模型部署。
相比 R , Python 支持多種強大的諸如 keras、convnet,、theano 和 tensorflow 深度學習庫。
Python的庫相對獨立,每個庫都擁有數據科學工作者所需要的所有函數。你不需要像在 R 中一樣在各種包之間來回查找一個函數。
理解 Python 數據類型和結構(與 R 對比)
編程語言是基于它的變量和數據類型來理解復雜的數據集。是的,假設你有一個 100 萬行,50 列的數據集。編程語言會如何理解這些數據呢?
基本上,R 和 Python 都有未定義數據類型。獨立和非獨立變量都有著不同的數據類型。解釋器根據數據類型分配內存。Python 支持的數據類型包括:
1.數值型(Numbers)——存儲數值。這些數值可以存儲為4種類型:整型,長整型,浮點型,復數型。讓我們分別理解。
- 整型(Integer)—— 它指的是整數類型,比如 10 、13 、91、102 等。相當于 R 中的整型(integer)。
- 長整型(Long)——它指的是用八進制或者十六進制表示的長整數,在 R 中,用 64 位包讀取十六進制值。
- 浮點型(Float)——指的是小數值,比如 1.23 , 9.89 等, R 中浮點數包含在數值型(numeric)。
- 復數型(Complex)——它指的是復數值,比如 as 2 + 3i, 5i 等。不過這種數據類型在數據中不太常見。
2.布爾型(Boolean)——布爾型只存儲兩個值(True 和 False)。在 R 中,它可以存儲為因子(factor)類型或字符(character)類型。R 和 Python 的布爾值之間存在著微小的差別。在 R 中,布爾型存儲為 TRUE 和 FALSE。在 Python 中,它們存儲為 True 和 False 。字母的情況有差異。
3.字符串(Strings)——它存儲文本(字符)數據,如“elephant,”lotus,”等,相當于R的字符型(character)。
4.列表——它與 R 的列表數據類型相同。它能夠存儲多種變量類型的值,如字符串、整數、布爾值等。
5.元組—— R 中沒有元組類型,把元組看成是 R 中的向量,它的值不能改變。即它是不可變的。
6.字典—— 它提供支持 key-value 對的二維結構。簡而言之,把鍵(key )看作是列名,對(pair)看作是列值。
因為 R 是統計計算語言,所有操作數據和讀取變量的函數都是固有的。而另一方面,Python 數據的分析、處理、可視化函數都是從外部庫調用。Python 有多個用于數據操作和機器學習的庫。以下列舉最重要的幾個:
- Numpy——在Python中它用于進行數值計算。它提供了龐大的諸如線性代數、統計等的數學函數庫。它主要用于創建數組。在 R 中,把數組看作列表。它包含一個類(數字或字符串或布爾)或多個類。它可以是一維或多維的。
- Scipy ——在Python中它用于進行科學計算。
- Matplotlib——在 Python 中它用于進行數據可視化。在 R,我們使用著名的 ggplot2 庫。
- Pandas ——對于數據處理任務它極其強大。在 R 中,我們使用 dplyr,data.table 等包。
- Scikit Learn—— 它是實現機器學習算法的強大工具。實際上,它也是 python 中用來做機器學習的***工具。它包含建模所需的所有函數。
在某種程度上,對于數據科學工作者來說,最主要的是要掌握上面提到的 Python 庫。但人們正開始使用的高級 Python 庫有太多。因此,為了實際目標,你應該記住以下這些:
- 數組(Array)——這與 R 的列表類似。它可以是多維的。它可以包含相同或多個類的數據。在多個類的情況下,會發生強制類型轉換。
- 列表(List)—— 相當于 R 中的列表。
- 數據框(Data Frame)——它是一個包含多個列表的二維結構。R中有內置函數 data.frame,Python則從 pandas庫中調用 Dataframe 函數。
- 矩陣(Matrix)——它是二維(或多維)結構,包含同一類(或多個類)的所有值。把矩陣看成是向量的二維版。在R中,我們使用 matrix 函數。在Python中,我們使用 numpy.column_stack 函數。
到這里,我希望你已經明白了R和Python中數據類型和數據結構的基本知識。現在,讓我們開始應用它們。
用Python寫代碼(對比R)
我們現在來使用在前面部分學到的知識,明白它們實際的含義。但在此之前,你要先通過Anaconda的 jupyter notebook 安裝 Python(之前稱為ipython notebook)。你可以點擊這里下載。我希望你已經在電腦上安裝了 R Studio 。
創建列表
在 R 中,創建列表使用的是 list 函數
- my_list <- list ('monday','specter',24,TRUE)
- typeof(my_list)
- [1] "list"
在 Python 中,創建列表使用的是方括號 [ ] 。
- my_list = ['monday','specter',24,True]
- type(my_list)
- list
在 pandas 庫中也可以得到相同的輸出,在 pandas 中,列表稱為序列。在 Python 中安裝 pandas,寫下:
- #importing pandas library as pd notation (you can use any notation) #調用 pandas 庫
- import pandas as pd
- pd_list = pd.Series(my_list)
- pd_list
- 0 monday
- 1 specter
- 2 24
- 3 True
數字(0,1,2,3)表示數組索引。你注意到什么了嗎?Python 索引是從 0 開始,而 R 的索引從 1 開始。讓我們繼續了解列表子集在 R 和 Python 的區別。
- #create a list # 創建一個列表
- new_list <- list(roll_number = 1:10, Start_Name = LETTERS[1:10])
把 new_list 看作一列火車。這列火車有兩個名為 roll_number 和 Start_Name 的車廂 。在每個車廂中,有10人。所以,在列表構建子集中,我們可以提取車廂的值,車廂中的人等,等等。
- #extract first coach information #提取***個車廂信息
- new_list[1] #or
- df['roll_number']
- $roll_number
- [1] 1 2 3 4 5 6 7 8 9 10
- #extract only people sitting in first coach #提取坐在***個車廂中的人
- new_list[[1]] #or
- df$roll_number
- #[1] 1 2 3 4 5 6 7 8 9 10
如果你查詢一下 new_list [ 1 ] 的類型,你會發現它是一個列表,而 new_list [ [ 1 ] ] 類型是一個字符。類似地,在 Python 中,你可以提取列表組件:
- #create a new list #創建一個新列表
- new_list = pd.Series({'Roll_number' : range(1,10),
- 'Start_Name' : map(chr, range(65,70))})
- Roll_number [1, 2, 3, 4, 5, 6, 7, 8, 9]
- Start_Name [A, B, C, D, E]
- dtype: object
- #extracting first coach #提取***個車廂
- new_list[['Roll_number']] #or
- new_list[[0]]
- Roll_number [1, 2, 3, 4, 5, 6, 7, 8, 9]
- dtype: object
- #extract people sitting in first coach #提取坐在***個車廂中的人
- new_list['Roll_number'] #or
- new_list.Roll_number
- [1, 2, 3, 4, 5, 6, 7, 8, 9]
R 和 Python 的列表索引有一個讓人困惑的區別。如果你注意到在 R 中 [[ ]] 表示獲取車廂的元素, 然而[[ ]] 在 Python 中表示獲取車廂本身。
2. Matrix 矩陣
矩陣是由向量(或數組)組合而成的二維結構。一般來說,矩陣包含同一類的元素。然而,即使你混合不同的類(字符串,布爾,數字等)中的元素,它仍會運行。R 和 Python 在矩陣中構建子集的方法很相似,除了索引編號。重申,Python 索引編號從 0 開始,R 索引編號從 1 開始。
在 R 中,矩陣可以這么創建:
- my_mat <- matrix(1:10,nrow = 5)
- my_mat
- #to select first row #選取***行
- my_mat[1,]
- #to select second column #選取第二列
- my_mat[,2]
在Python中,我們會借助 NumPy 數組創建一個矩陣。因此,我們先要加載 NumPy 庫。
- import numpy as np
- a=np.array(range(10,15))
- b=np.array(range(20,25))
- c=np.array(range(30,35))
- my_mat = np.column_stack([a,b,c])
- #to select first row #選取***行
- my_mat[0,]
- #to select second column #選取第二列
- my_mat[:,1]
3. 數據框(Data Frames)
數據框為從多來源收集而來的松散的數據提供了一個急需的骨架。它類似電子表格的結構給數據科學工作者提供了一個很好的圖片來展示數據集是什么樣子。在R中,我們使用data.frame() 函數創建一個數據框。
- data_set <- data.frame(Name = c("Sam","Paul","Tracy","Peter"),
- Hair_Colour = c("Brown","White","Black","Black"),
- Score = c(45,89,34,39))
那么,我們知道一個數據框是由向量(列表)的組合創建的。在 Python 中創建數據框,我們將創建一個字典(數組的組合),并且在 pandas 庫的 Dataframe()函數中附上字典。
- data_set = pd.DataFrame({'Name' : ["Sam","Paul","Tracy","Peter"],
- 'Hair_Colour' : ["Brown","White","Black","Black"],
- 'Score' : [45,89,34,39]})
現在,讓我們看下操作 dataframe 最關鍵的部分,構建子集。實際上,大部分數據操作都包含從各個可能的角度切割數據框。讓我們逐個看下任務:
- #select first column in R #在 R 中選取***行
- data_set$Name # or
- data_set[["Name]] #or
- data_set[1]
- #select first column in Python #在 Python 中選取***列
- data_set['Name'] #or
- data_set.Name #or
- data_set[[0]]
- #select multiple columns in R # 在 R 中選取多列
- data_set[c('Name','Hair_Colour')] #or
- data_set[,c('Name','Hair_Colour')]
- #select multiple columns in Python #在 Python 中選取多行
- data_set[['Name','Hair_Colour']] #or
- data_set.loc[:,['Name','Hair_Colour']]
.loc 函數用于基于標簽的索引
到這里我們大致明白了 R 和 Python 中的數據類型、結構和格式。讓我們用一個數據集來探索 python 中數據的其他面。
用一個數據集實踐 Python
強大的 scikit-learn 庫包含一個內建的數據集庫。為了我們實踐的目的,我們將采用波士頓住房數據集(Boston housing data set)。做數據分析時,它是一個很流行的數據集。
- #import libraries #調用庫
- import numpy as np
- import pandas as pd
- from sklearn.datasets import load_boston
- #store in a variable #存儲在一個變量中
- boston = load_boston()
變量boston是一個字典。回顧一下,字典是key-value對的組合,讓我看下鍵(key)的信息:
- boston.keys()
- ['data', 'feature_names', 'DESCR', 'target']
現在我們知道我們需要的數據集駐留在key數據中。我們也看到,對于功能名稱有一個單獨的key。我認為數據集不會分配列名。讓我們來檢查下我們要處理的列名。
- print(boston['feature_names'])
- ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO' 'B' 'LSTAT']
你能明白這些名稱嗎?我也不明白。現在,讓我們檢查下數據描述和理解每個變量的意義。
- print(boston['DESCR'])
這個數據集有506行,13列。它包含幫助確定波士頓房價的多種特征。現在,讓我們創建一個數據框:
- bos_data = pd.DataFrame(boston['data'])
類似于 R , python 也有一個 head()函數讀入數據:
- bos_data.head()
輸出顯示數據集沒有列名(如上所述)。將列名分配到數據框中是容易的。
- bos_data.columns = boston['feature_names']
- bos_data.head()
就像R中的 dim() 函數,Python 有檢查數據集維數的 shape() 函數。為得到數據集的統計匯總,我們寫下:
- bos_data.describe()
它顯示了數據中列的統計匯總。讓我們快速探索這個數據的其他方面。
- #get first 10 rows #得到***10行
- bos_data.iloc[:10]
- #select first 5 columns #選取***個5列
- bos_data.loc[:,'CRIM':'NOX'] #or
- bos_data.iloc[:,:5]
- #filter columns based on a condition #基于條件篩選列
- bos_data.query("CRIM > 0.05 & CHAS == 0")
- #sample the data set #構建數據集樣本
- bos_data.sample(n=10)
- #sort values - default is ascending #分類上升的默認值
- bos_data.sort_values(['CRIM']).head() #or
- bos_data.sort_values(['CRIM'],ascending=False).head()
- #rename a column #重命名一個列
- bos_data.rename(columns={'CRIM' : 'CRIM_NEW'})
- #find mean of selected columns #查找選定列的平均值
- bos_data[['ZN','RM']].mean()
- #transform a numeric data into categorical #將數字數據轉換成分類
- bos_data['ZN_Cat'] = pd.cut(bos_data['ZN'],bins=5,labels=['a','b','c','d','e'])
- #calculate the mean age for ZN_Cat variable #計算ZN_Cat變量的平均年齡
- bos_data.groupby('ZN_Cat')['AGE'].sum()
此外,Python 還允許我們創建透視表。是的! 就像 MS Excel 或任何其他電子表格軟件,你可以創建一個數據透視表,更密切地了解數據。不幸的是,在 R 中創建一個數據透視表是一個相當復雜的過程。在 Python 中,一個透視表需要行名、列名和要計算的值。如果我們不通過任何列名稱,得到的結果只會像你使用 groupby 函數得到的。因此,讓我們創建另一個分類變量。
- #create a new categorical variable #創建一個新的分類變量
- bos_data['NEW_AGE'] = pd.cut(bos_data['AGE'],bins=3,labels=['Young','Old','Very_Old'])
- #create a pivot table calculating mean age per ZN_Cat variable #創建一個透視表計算每個 ZN_Cat 變量的年齡
- bos_data.pivot_table(values='DIS',index='ZN_Cat',columns= 'NEW_AGE',aggfunc='mean')
這只是冰山一角。下一步怎么做?就像我們使用波士頓住房數據集,現在你可以試試安德森鳶尾花卉數據集(iris data)。它在sklearn_datasets 庫是可用的。嘗試深入探討。記住,你練習越多,花費的時間越多,你就會變得越好。
總結
總體來說,學習這兩門語言會給你足夠的自信去處理任何類型的數據集。事實上,學習python***的一面是它有完善的文檔可以用在numpy,pandas,scikit learn 庫,這足夠幫你跨越所有最初的障礙。