HBase在阿里搜索中的應(yīng)用實踐
原創(chuàng)【51CTO.com原創(chuàng)稿件】李鈺,花名絕頂,WOTA全球架構(gòu)與運維技術(shù)峰會分享嘉賓,現(xiàn)任阿里巴巴搜索事業(yè)部高級技術(shù)專家,HBase開源社區(qū)PMC & committer。開源技術(shù)愛好者,主要關(guān)注分布式系統(tǒng)設(shè)計、大數(shù)據(jù)基礎(chǔ)平臺建設(shè)等領(lǐng)域。連續(xù)3年基于HBase/HDFS設(shè)計和開發(fā)存儲系統(tǒng)應(yīng)對雙十一訪問壓力,具備豐富的大規(guī)模集群生產(chǎn)實戰(zhàn)經(jīng)驗。
HBase作為淘寶全網(wǎng)索引構(gòu)建以及在線機器學習平臺的核心存儲系統(tǒng),是阿里搜索基礎(chǔ)架構(gòu)的重要組成部分。本文我們將介紹HBase在阿里搜索的歷史、規(guī)模,應(yīng)用的場景以及在實際應(yīng)用當中遇到的問題和優(yōu)化。
HBase在阿里搜索的歷史、規(guī)模和服務(wù)能力
歷史:阿里搜索于2010年開始使用HBase,從最早到目前已經(jīng)有十余個版本。目前使用的版本是在社區(qū)版本的基礎(chǔ)上經(jīng)過大量優(yōu)化而成。社區(qū)版本建議不要使用1.1.2版本,有較嚴重的性能問題, 1.1.3以后的版本體驗會好很多。
集群規(guī)模:目前,僅在阿里搜索節(jié)點數(shù)就超過3000個,***集群超過1500個。阿里集團節(jié)點數(shù)遠遠超過這個數(shù)量。
服務(wù)能力:去年雙十一,阿里搜索離線集群的吞吐峰值一秒鐘訪問超過4000萬次,單機一秒鐘吞吐峰值達到10萬次。還有在CPU使用量超過70%的情況下,單cpu core還可支撐 8000+ QPS。
HBase在阿里搜索的角色和主要應(yīng)用場景
角色:HBase是阿里搜索的核心存儲系統(tǒng),它和計算引擎緊密結(jié)合,主要服務(wù)搜索和推薦的業(yè)務(wù)。
用實踐")
HBase在搜索和推薦的應(yīng)用流程
如上圖,是HBase在搜索和推薦的應(yīng)用流程。在索引構(gòu)建流程中會從線上MySQL等數(shù)據(jù)庫中存儲的商品和用戶產(chǎn)生的所有線上數(shù)據(jù)通過流式的方式導入到HBaes中,并提供給搜索引擎構(gòu)建索引。在推薦流程中,機器學習平臺Porshe會將模型和特征數(shù)據(jù)存儲在HBase里,并將用戶點擊數(shù)據(jù)實時的存入HBase,通過在線training更新模型,提高線上推薦的準確度和效果。
應(yīng)用場景一:索引構(gòu)建。淘寶和天貓有各種各樣的的線上數(shù)據(jù)源,這取決于淘寶有非常多不同的線上店鋪和各種用戶訪問。
用流程")
索引構(gòu)建應(yīng)用場景
如上圖,在夜間我們會將數(shù)據(jù)從HBase批量導出,供給搜索引擎來構(gòu)建全量索引。而在白天,線上商品、用戶信息等都在不停的變化,這些動態(tài)的變化數(shù)據(jù)也會從線上存儲實時的更新到HBase并觸發(fā)增量索引構(gòu)建,進而保證搜索結(jié)果的實時性。
目前,可以做到端到端的延時控制在秒級,即庫存變化,產(chǎn)品上架等信息在服務(wù)端更新后,迅速的可在用戶終端搜索到。
用實踐")
索引構(gòu)建應(yīng)用場景抽象圖
如上圖,整個索引構(gòu)建過程可以抽象成一個持續(xù)更新的流程。如把全量和增量看做是一個Join,線上有不同的數(shù)據(jù)源且實時處于更新狀態(tài),整個過程是長期持續(xù)的過程。這里,就凸顯出HBase和流式計算引擎相結(jié)合的特點。
應(yīng)用場景二:機器學習。這里舉一個簡單的機器學習示例:用戶想買一款三千元的手機,于是在淘寶按照三千元的條件篩選下來,但是沒有中意的。之后 ,用戶會從頭搜索,這時就會利用機器學習模型把三千塊錢左右的手機排在搜索結(jié)果的靠前位置,也就是用前一個搜索結(jié)果來影響后一個搜索結(jié)果的排序。
用實踐")
分析線上日志
如上圖,分析線上日志,歸結(jié)為商品和用戶兩個緯度,導入分布式、持久化消息隊列,存放到HBase上。隨線上用戶的點擊行為日志來產(chǎn)生數(shù)據(jù)更新,對應(yīng)模型隨之更新,進行機器學習訓練,這是一個反復迭代的過程。
HBase在阿里搜索應(yīng)用中遇到的問題和優(yōu)化
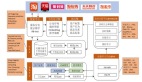
HBase架構(gòu)分層。在說問題和優(yōu)化之前,先來看HBase的架構(gòu)圖,大致分為如下幾個部分:
用實踐")
HBase的架構(gòu)圖
首先是API,一些應(yīng)用程序編程接口。RPC,這里把遠程過程調(diào)用協(xié)議分為客戶端會發(fā)起訪問與服務(wù)端來處理訪問兩部分。MTTR故障恢復、Replication數(shù)據(jù)復制、表處理等,這些都是分布式管理的范疇。中間Core是核心的數(shù)據(jù)處理流程部分,像寫入、查詢等,***層是HDFS(分布式文件系統(tǒng))。HBase在阿里搜索應(yīng)用中遇到的問題和優(yōu)化有很多,下面挑選近期比較重點的RPC的瓶頸和優(yōu)化、異步與吞吐、GC與毛刺、IO隔離與優(yōu)化、IO利用這五方面進行展開。
問題與優(yōu)化一:RPC的瓶頸和優(yōu)化
用實踐")
RPC Server線程模型
PPC服務(wù)端的實際問題是原有RpcServer線程模型效率較低,如上圖,可以看到整個過程通常很快,但會由不同的線程來處理,效率非常低。基于Netty重寫之后,可以更高效的復用線程,實現(xiàn)HBase RpcServer。使得RPC平均響應(yīng)時間從0.92ms下降到0.25ms,吞吐能力提高接近2倍。
問題與優(yōu)化二:異步與吞吐
RPC的客戶端存在的實際問題是流式計算對于實時性的要求很高、分布式系統(tǒng)無法避免秒級毛刺、同步模式對毛刺敏感,吞吐存在瓶頸。優(yōu)化手段就是基于netty實現(xiàn)non-blocking client,基于protobuf的non-blocking Stub/RpcCallback實現(xiàn)callback回調(diào),當和flink集成后實測吞吐較同步模式提高2倍。
問題與優(yōu)化三: GC與毛刺
用實踐")
如上圖,這部分的實際問題是PCIe-SSD的高IO吞吐能力下,讀cache的換入換出速率大幅提高、堆上的cache內(nèi)存回收不及時,導致頻繁的CMS gc甚至fullGC。優(yōu)化手段是實現(xiàn)讀路徑E2E的offheap,使得Full和CMS gc頻率降低200%以上、讀吞吐提高20%以上。
用實踐")
如上圖,是線上的一個結(jié)果,QPS之前是17.86M,優(yōu)化之后是25.31M。
問題與優(yōu)化四: IO隔離與優(yōu)化
HBase本身對IO非常敏感,磁盤打滿會造成大量毛刺。在計算存儲混合部署環(huán)境下,MapReduce作業(yè)產(chǎn)生的shuffle數(shù)據(jù)和HBase自身Flush/Compaction這兩方面都是大IO來源。
如何規(guī)避這些影響呢?利用HDFS的Heterogeneous Storage功能,對WAL(write-ahead-log)和重要業(yè)務(wù)表的HFile使用ALL_SSD策略、普通業(yè)務(wù)表的HFile使用ONE_SSD策略,保證Bulkload支持指定storage policy。同時,確保MR臨時數(shù)據(jù)目錄(mapreduce.cluster.local.dir)只使用SATA盤。
用實踐")
HBase集群IO隔離后的毛刺優(yōu)化效果
對于HBase自身的IO帶來的影響,采用Compaction限流、Flush限流和Per-CF flush三大手段。上圖為線上效果,綠線從左到右分別是響應(yīng)時間、處理時間和等待時間的p999數(shù)據(jù),以響應(yīng)時間為例,99.9%的請求不會超過250ms。
問題與優(yōu)化五: IO利用
用實踐")
HDFS寫3份副本、通用機型有12塊HDD盤、SSD的IO能力遠超HDD。如上圖,實際問題是單WAL無法充分使用磁盤IO。
用實踐")
如上圖,為了充分利用IO,我們可以通過合理映射對region進行分組,來實現(xiàn)多WAL。基于Namespace的WAL分組,支持App間IO隔離。從上線效果來看,全HDD盤下寫吞吐提高20%,全SSD盤下寫吞吐提高40%。線上寫入平均響應(yīng)延時從0.5ms下降到0.3ms。
開源&未來
為什么要擁抱開源?其一,試想如果大家做了優(yōu)化都不拿出來,認為這是自己強于別人的優(yōu)勢,結(jié)果會怎樣?如果大家把自己的優(yōu)勢都拿出來分享,得到的會是正向的反饋。其二, HBase的團隊一般都比較小,人員流失會產(chǎn)生很大的損失。如把內(nèi)容貢獻給社區(qū),代碼的維護成本可以大大降低。開源一起做,比一個公司一個人做要好很多,所以我們要有貢獻精神。
未來,一方面,阿里搜索會進一步把PPC服務(wù)端也做異步,把HBase內(nèi)核用在流式計算、為HBase提供嵌入式的模式。另一方面,嘗試更換HBase內(nèi)核,用新的DB來替代,達到更高的性能。
讓我們共同期待, 2017年8月4號于深圳舉行的HBaseCon Asia,現(xiàn)場見!!!
以上內(nèi)容根據(jù)絕頂老師在WOTA2017 “大數(shù)據(jù)系統(tǒng)架構(gòu)”專場的演講內(nèi)容整理。
【51CTO原創(chuàng)稿件,合作站點轉(zhuǎn)載請注明原文作者和出處為51CTO.com】