圖算法在阿里風控系統中的實踐

一、電商風控場景中的圖算法介紹
首先簡單概述下阿里電商風險特點、圖算法的應用歷史與現狀。
1、阿里電商風險特點
阿里電商風險的主要特點:對抗性 & 排列組合式的復雜性。
風險一定存在對抗性,同時阿里電商的風險還具有排列組合的復雜性。做風險識別主要是用 X(數據)去預測 Y(風險):P(Y|X)。而在阿里電商 X 非常復雜,因為阿里電商是一個非常高維的經濟生態:
① 多樣的市場 -- 淘寶、閑魚、天貓、1688、Lazada 等,不同市場的風險特點不一樣;
② 多樣的業務場景-- 賬號,商品,促銷等,且隨著業務的迭代與創新會產生新的風險;
③ 多樣的應用端 -- PC、H5、APP 等,每個端都需要做防控;
④ 多樣的數據源,需要有能力處理和整合不同模態的數據。

同時 Y 也很復雜,主要體現在三方面,第一是風險種類很多,常見的內容風險、行為風險等只是眾多風險中的滄海一粟;第二是這些風險是有關聯的,比如賣家欺詐跟注冊、被盜、商品內容都有關系;第三是風險會轉移,當一類風險防得比較好了,作案成本高了,又轉移到其他風險或者產生新的風險。
所以整個的風險防控非常復雜,具有排列組合式的復雜性。
2、圖算法的重要性
圖算法可以提升風險識別模型的對抗能力。平臺上大部分的“壞事”只是少數人干的,“壞人”有很多馬甲,我們可以通過“關系”找出蛛絲馬跡,提前識別和處置。比如下圖中黃色的點,假設它是一個有異常行為的用戶,僅憑他自身的行為很難判斷他是一個欺詐用戶,但是可以通過分析和他關聯的其他三個欺詐用戶(黑點)來確定他是一個欺詐用戶。同時我們把這四個賬戶關聯緊密的賬戶都找出來,發現是一個團伙,提前的批量處置這些賬號,可以提升作惡的成本。

此外,異質圖可以自然的全局融合各模態、各風險對象數據,計算出各個不同對象的表征,進而進行不同風險的識別,來應對排列組合式的復雜性
3、圖算法的歷史與現狀
基于圖算法的重要性,阿里電商風控從 2013 年就使用圖算法。
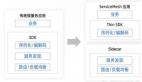
起初圖算法被用來構建整個賬號庫的關系網絡。這個關系數據是欺詐、賬戶安全、反作弊、假貨等所有風險防控場景所需的基礎數據,主要使用的數據有設備信息、手機號等媒介數據。它主要是刻畫賬戶與賬戶之間的相關性、關系類型和群體識別等。目前已對該關系網絡建立了從生產到應用的閉環反饋通道。
底層的關系數據非常多,整體的進行一次關系數據的匯總、清洗、圖計算和存儲,成本是很高的,而且后面還要保持不斷的更新,所以構建關系網絡的成本很高,但因為我們有很多風險的模型、策略依賴這個關系網絡,所以還是很值得的。

而對于圖神經網絡,我們在 2016 年就開始探索應用,那時我們還叫 GGL(Geometric Graph Learning,幾何圖學習),當時還沒有直接可用的圖神經網絡算法框架,所以我們用 C++ 實現了一個 GGL 算法框架。在 2018 年的時候轉移到了阿里計算平臺提供的 Graph learn 上,這個框架目前也是開源的,我們也在這個框架中貢獻了一些圖算法代碼。

電商風控場景豐富,在圖算法驗證階段選擇合適的場景也尤為重要。風險場景中占比較大的行為風險“判斷標準”不直觀,在工業場景里行為風險白樣本混雜著很多還未被發現的黑樣本,當圖算法將白樣本判斷為黑樣本時很難判斷是誤召回還是增益召回,這會影響模型的調優和上線效果的判斷。相反,內容安全場景,比如垃圾消息、辱罵,是一個有“直觀判斷標準”的場景,更適合驗證圖算法有效性。所以我們先在內容安全場景探索算法,驗證有效和沉淀最佳實踐后,鋪開應用到行為風險場景。
目前為止,阿里電商各類風險業務都會用到圖算法。整個圖算法應用框架如下圖,首先在底層維護一個關系數據層,匯集和清洗各類關系數據,便于上層的應用;在數據層之上,沉淀常用的圖算法;再上一層利用關系數據層和算法層構建了賬號關系網絡,它橫向支撐業務層的各類風險場景的防控;在最上層的業務層,結合具體風險的特點,我們利用這些圖算法和關系數據構建圖模型,識別各類業務風險。

接下來的分享將主要介紹“交互內容風險”、“商品禁限售”、“假貨治理”這三類風險應用的一些圖算法。
二、交互內容風控的圖算法
阿里電商平臺有豐富的交互內容場景,比如商品評價、評論、問大家,以及手淘逛逛、閑魚社區等,下面以閑魚留言垃圾廣告的識別為例來介紹內容風控圖算法。

在閑魚 APP 里的商品留言里很容易出現“垃圾廣告”這類的內容風險,比如兼職、刷單、賣減肥藥等,且對抗性很強,比如上面截圖里的“兄弟看看我”,其真正的廣告不在文字本身,而在該用戶的首頁。
閑魚留言的垃圾廣告識別是我們圖神經網絡算法第一個落地應用的場景,這個識別模型我們簡稱為 GAS。整個模型由一個異質圖和一個同質圖構成。異質圖學習每個節點的局部表征,包含商品、留言和用戶,同質圖則是一個 comment graph 學習不同留言的全局表征,最后將這四個表征融合在一起進行二分類模型訓練。

訓練整體數據集包括留言有 3kw+,商品 2kw+, 用戶 900w+,上線后相比原來的 MLP 模型識別多召回了 30% 的風險。此外,通過消融實驗也證實,加入全局信息提升也很顯著,這是由于垃圾廣告本身的特點——需要大量轉發才有較好的收益。這個工作最終整理并發表于 paper[1],獲得了 CIKM2019 的 Best Applied Research Paper。

三、商品內容風控的圖算法
這里主要介紹兩類商品內容風控的圖算法:一類是商品圖結構學習,一類是商品圖結構與專業知識圖譜的融合。

商品風險管控主要是管控“禁限售”風險,很多種類的商品是國家法律法規規定不能售賣的,比如國家保護動植物、作弊造假、管制醫療器械等。
商品的管控很復雜,商品數據是多數據流、多通道、多模態的:
① 多數據流:標題、描述、主圖、副圖、詳情圖、SKU;
② 多通道:文字的音、形、意,圖片的 RGB;
③ 多模態:文字、圖片、元信息(價格、銷量) 。
同時商品內容風險也是復雜多樣且對抗激烈的,比如上圖中看上去是賣串珠,但實際上是賣象牙。
商品內容風控圖算法主要有兩類 :一種是多模態融合的模型,用深度模型構建一個商品的神經網絡,通過多模態的融合進行多任務的學習,這是商品局部信息的學習;另一種是為了提升對風險的召回,用異質圖建立商品和商品、商品和賣家、賣家和賣家之間的關系,進行全局信息的融合學習。
1、商品圖的圖結構學習
GCN 的本質是融合鄰居特征的特征平滑,因此圖神經網絡的學習對圖結構的質量有一定要求,好的網絡圖是稠密且同質率高的。然而,風險商品圖稀疏且同質率比較低(0.15,對公開數據集統計發現 0.6 以上才比較好),所以我們必須對圖結構進行學習。

商品圖里面有三種邊分別構成三種圖,如下圖右邊框架圖所示:一類是兩個商品是同一賣家賣的同賣家圖,第二類是兩個商品被同消費者瀏覽過的同瀏覽圖,第三類是兩個商品的賣家有很強關聯的關聯賣家圖。
商品圖結構學習本質是加邊和刪邊的過程:首先根據商品 embedding 用 KNN Graph 構建一個 KNN 圖,之后將以上四類邊和商品 embedding 一起放入 HGT 學習商品新 embedding 并對 attention 值較低的邊作為噪聲進行刪除,新的商品 embedding 可以用來更新 KNN Graph,如此往返迭代直到 loss 收斂。在真實數據中的實踐表明該圖結構學習框架相比同質圖/異質圖,達到了 SOTA 的效果。

2、圖計算與風險知識圖譜的融合
商品圖算法的提升算法是圖計算與風險知識圖譜的融合。有些商品風險很難通過常識判斷,需要結合一定的專業領域知識。所以針對這些具體的風險領域知識點構建了特定的知識圖譜,以此來輔助模型識別和人工審核。
比如下圖左側顯示的兩個商品,直觀看是賣簡單的飾品,實際上是賣藏羚羊角,而藏羚羊是國家一級保護動物,它的相關產品是禁售的,我們通過該商品和藏羚羊相關知識進行匹配可識別出該商品風險。融合算法框架如下圖右側所示:模型目標是判斷候選商品和風險知識點是否匹配。Item p 是商品圖文表征,Risk-Point R 是知識點表征,通過實體識別、實體鏈接和關系抽取等得到商品和該知識點的子圖,再用 GNN 計算子圖的表征 ,最后用該表征進行風險的分類識別。其中,CPR 是商品表征和知識點表征的融合,它主要用來指導圖表征學習一些全局信息。實踐表明,相比商品多模態識別,加入風險知識圖譜對長尾風險的召回提升 10 個點以上。

在此基礎上,我們還嘗試引入了全局商品圖。當商品內容直接關聯知識圖譜也不能識別風險時,可以進一步引入商品和商品之間的關聯輔助判斷,比如下圖中某個標有“幼崽也有”的商品和“紅腹松鼠”知識沒有強匹配關系,但這個商品同賣家的另一個商品“紅腹”和“紅腹松鼠”知識匹配,因此可推理該商品實際上賣的是紅腹松鼠(二級保護動物,禁售)。實踐表明,做知識推理時引入整個大的商品圖能再提高長尾風險召回 3% 以上。

四、動態異質圖的風控實踐
前面介紹的圖算法主要還是靜態圖的挖掘應用,但是很多的風險場景存在動態圖的風險模式。
比如售假商家先注冊,再批量發布大量商品,炒作吸引流量,然后快速進行售假,在這一系列動作中時間維度的圖結構變化對我們的風險識別很重要,因此動態圖也是圖算法探索與應用的重點方向。
動態圖最大的挑戰是如何設計和搜索到好的圖結構。一方面,動態圖在原有的異質圖基礎上引入了時間維度,比如有 30 個時刻,那么動態圖的參數(信息量)是異質圖的 30 倍,這給學習帶來很大壓力;另一方面,由于風險的對抗性,動態圖需要有較強的魯棒性。

1、動態圖自動學習
據此,我們提出了基于 Attention 的動態 GNN + AutoML,在限定一定參數空間下,選擇最好的模型結構(DHGAS)。該模型的核心是通過自動學習對模型結構尋優,如下圖所示:首選將動態圖分解成不同時刻的異質圖,并對不同時刻和不同節點設置不同的函數空間來表示商品表征的變化空間 (N*T 種,N:節點種類;T:時間空間),對不同時刻和不同邊類型也設置不同的函數空間來表示信息傳播的路徑空間(R*T 種,R:邊種類;T:時間空間),最后節點和鄰居聚合的時候有 R*T*T 種聚合的方式(兩個 T 分別是邊兩端節點的時間戳。
顯然整個搜索空間龐大,我們嘗試限定參數空間,借助自動機器學習技術構建 supernet,讓模型自動搜索到最優網絡架構。具體做法:限制 N*T 的函數空間數目為 K_N,R*T 函數空間數據為 K_R,R*T*T 的模長為 K_Lo,比如 N=6,T=30,理論有 N*T=180 個函數空間,實際限制到 K_N=10。
該算法當前已落地到“假貨賣家識別”,“商品禁限售的惡意商家識別”等場景,且和業界主流算法對比都得到了 SOTA 的結果,具體可以查閱論文[2]。

2、動態圖魯棒學習
由于風險的對抗性,動態圖需要有較強的魯棒性,其本質是希望動態圖能學到一些本質的 pattern,比如下圖中示例子圖的本質 pattern 是冰激凌銷量上升是由于天氣變熱了,而不是溺水人數增加。
我們希望魯棒性學習解決電商風控動態圖的一些分布偏移問題:
(1)特征偏移:比如如果過度依賴歷史違規信息這類特征,對新注冊的問題會員召回會不佳;
(2)結構偏移:比如過度依賴垃圾廣告會員的度密集子結構,會把很活躍的正常會員誤召回;
(3)時間偏移:惡意用戶隨著防控會發生明顯的行為變異。

對此,我們提出了一個算法 DIDA,核心思想如下圖所示:在學習動態圖時學習兩個 pattern——橙色代表的本質 pattern 和綠色代表的非本質 pattern,僅用本質 pattern 的 loss(L)+ 非本質 patterns 組合的 loss 方差(Ldo)作為模型最終學習的 loss。非本質 patterns 組合的 loss 方差(Ldo)的設計思想是:假設圖中綠色的 a3 是非本質的 pattern,那么把這個綠色的 a3 換成其他非本質 patterns 如 b3、c3 等應該對模型的 loss(判別能力)影響不大。因此我們可以將非本質 patterns 的 loss 方差加入模型學習,最終預測階段則只用本質 pattern 來進行分類。目前該算法已經落地到商品內容風控場景中,也整理出 paper[3]。

五、ICDM2022 比賽:大規模電商圖上的風險商品檢測
“ICDM2022 比賽:大規模電商圖上的風險商品檢測”是我們今年主辦的算法比賽,提供的數據是真實場景的脫敏數據。最終從提交的技術代碼和報告中也收獲了一些啟發:
(1)自監督預訓練對于效果提升有比較大幫助,但是需要選擇合適的自監督任務;
(2)GNN 結合標簽傳播可以帶來顯著提升 ,在之前的圖算法應用中由于擔心標簽泄露而丟棄了該部分數據,但在真實數據中實踐后發現并不明顯。猜測原因是現在的圖形網絡只是做到了信息融合,還沒做到推理或者推理能力較弱;
(3)解耦深度和層數有普遍提升, 可以傳播一次的同時聚合好幾次。

六、圖算法落地方式總結和展望
結合我們的經驗,總結了以下圖算法落地方式:
(1)圖算法框架/平臺:應該有個圖算法框架沉淀技術和最佳實踐,提升技術的復用性。
(2) 半自動化建模:為了提高建模的效率,在數據層面我們最好對底層的關系媒介數據做個清洗和匯總,在建模層面可以提供一些組件(MetaPath/MetaGraph 選擇組件,圖采樣組件,向量檢索組件等)提高建模效率。
(3)自動化調用:可以自動化調用只依賴輸入樣本的圖算法或圖模型,不需要了解圖模型,方便其他不熟悉圖算法的風險控制同學進行模型優化使用,比如團伙識別,商品回撈,風險用戶回撈等。
(4) 生產(自監督)圖表征:作為單獨的模態輸入到模型中使用,不影響原來的建模方式,大幅提升圖的應用場景。

后續工作展望:
(1)大規模的圖自監督表征學習。我們有上千個風險模型,其中還有很多沒應用上圖算法,因此我們下一步是做大規模的圖自監督表征,以擴大圖特征的應用范圍,幫助提升業務效果。該工作存在工程和算法上的雙重挑戰:首先是工程上,我們至少有數十億節點和數百億的邊供大規模學習,其次是算法上,圖表征不僅要能覆蓋常用的關系表征,還要學到更高階的圖的結構的特征,具有很強的通用性,能應用到各個場景。
(2)在具體的風控場景中探索實現圖的推理能力,目前圖算法更多的還是知識的融合,推理能力比較薄弱,無法應對風險的高對抗性。從客觀上我們需要我們的模型具備很強的智能 所以圖的推理能力很重要。目前擬依靠閑魚社區的豐富交互場景和內容來進行算法的探索。
(3)在動態異質圖的頻域研究、可解釋性方面有更多探索落地。頻域研究的目的是在動態圖中學到更多的圖結構變化的細節。可解釋則幫助我們了解算法是否真正學到了本質的特征,一方面幫助我們完善算法,另一方面也可以更好的提供給業務同學進行應用落地。

以上探索方向我們也在尋求學術合作,特別是圖推理方向。同時,我們現在也在招聘圖算法的同學,有興趣的同學可以聯系我。
七、Reference
1. Spam Review Detection with Graph Convolutional Networks. CIKM2019 Best Applied Research Paper.
2. Dynamic Heterogeneous Graph Attention Neural Architecture Search. AAAI2023.
3. Dynamic Graph Neural Networks Under Spatio-Temporal Distribution Shift. NeurIPS2022.
八、問答環節
Q1:風控場景的圖表征有什么特殊的挑戰,相比其他領域的圖表征?
A1:三個最主要的挑戰:首先圖結構比較差,同質率較低;其次是圖的魯棒性問題,在我們的場景里面特別是動態圖,它的分布漂移還是很嚴重的,還有另外一個問題黑樣本的風險濃度很低,并不是說 1:10 或者 1:20 之類的,在我們的圖算法里面有些風險的濃度是 1:1w+ 以上的,所以我們的樣本是極度極度不均衡的,這也是我們需要去解決的。
Q2:圖聯邦學習目前算法模型如何,行業是否有比較成熟的解決方案?你們對圖聯邦學習有沒有一些應用和一些考慮?
A2:我們現在主要還是用在我們電商場景里面 ,當然我們還有一些非電商業務,不過這些數據都是我們自己的數據我們還是可以直接使用進行風控的,所以現在還沒有用到聯邦學習 ,但是圖聯邦學習后面還是有必要用的,因為現在為了信息安全都在做數據切割和隔離,不同域的數據是不能打通來使用的,所以后面圖聯邦學習后面應該會成為我們一個探索應用方向。