如何讓深度學習在手機應用上也能加速跑?看完這篇文章你就知道了
目前使用了深度學習技術的移動應用 通常都是直接依賴云服務器來完成DNN所有的計算操作,但這樣做的缺點在于移動設備與云服務器之間的數據傳輸帶來的代價并不小(表現在系統延遲時間和移動設備的電量消耗) ;目前移動設備對DNN通常都具備一定的計算能力,盡管計算性能不如云服務器但避免了數據傳輸的開銷。
論文作者提出了一種基于模型網絡層為粒度的切割方法,將DNN需要的計算量切分開并充分利用云服務器和移動設備的硬件資源進行延遲時間和電量消耗這兩方面的優化。 Neurosurgeon很形象地描述了這種切割方法:向外科醫生一樣對DNN模型進行切分處理。
對于所有使用深度學習技術來處理圖像、視頻、語音和文本數據的個人智能助手而言,目前工業界通常的做法是,利用云服務器上強大的GPU集群資源來完成應用程序的計算操作(以下簡稱為現有方法)。
目前運行在移動設備上的個人智能助手(例如Siri、Google Now和Cortana等)也都是采用這種做法。盡管如此,我們還是會思考,能不能也對移動設備本身的計算能力加以利用(而不是完全依靠云服務),同時確保應用程序的延遲時間以及移動設備的電量消耗處于合理范圍內。
目前的現狀是,智能應用程序的計算能力完全依賴于Web服務商所提供的高端云服務器。
而Neurosurgeon打破了這種常規做法(即智能應用的計算能力完全依托于云服務)!在這篇出色的論文中, 作者向我們展示了一種新思路:將應用程序所需的計算量“分割”開,并同時利用云服務和移動設備的硬件資源進行計算 。下面是使用Neurosurgeon方法后所取得的結果,這將會使我們所有人受益:
-
系統延遲時間平均降低了3.1倍(最高降低了40.7倍),從而應用程序的響應將更加迅速和靈敏。
-
移動設備的耗電量平均降低了59.5%(最高降低了94.7%);(也許你會質疑,真的能夠在移動設備上實施更多計算量的同時降低電量消耗嗎?答案是十分肯定的!)
-
云服務器上數據中心的吞吐量平均提高了1.5倍(最高能提高6.7倍),相較于現有方法這是一個巨大的超越。
下面我們會先舉個例子,來看看“對計算量進行分割”這件事情是多么的有趣,之后會了解到Neurosurgeon是如何在不同的DNN模型中自動檢測出“最佳分割點”的,最后會展示相應的實驗結果以證實Neurosurgeon所宣稱的能力。
(值得一提的是,目前主流的平臺已經支持并實現了在移動設備上進行深度學習方面的計算。Apple在iOS10系統中新增了深度學習相關的開發工具,Facebook去年發布了Caffe2Go使得深度學習模型能夠運行在移動設備上,而Google也在前不久發布了深度學習開發工具TensorFlow Lite以用于安卓系統。)
▌ 數據傳輸并不是沒有代價
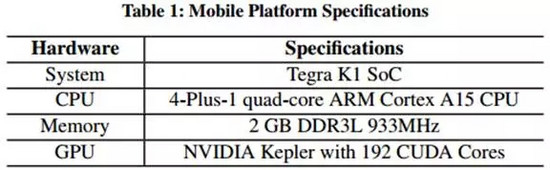
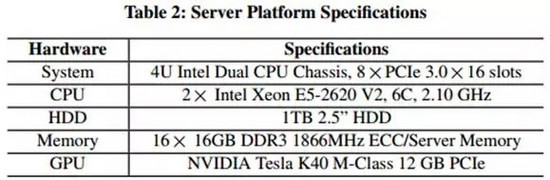
最新的SoC芯片讓人印象深刻。這篇論文使用了NVIDIA的Jetson TK1平臺(擁有4核心的ARM處理器和一個Kepler GPU)(如下表1),數十萬個設備的組合的計算量是驚人的。
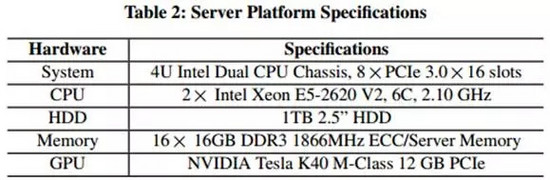
如果你對比一下服務器上的配置(如下表2),你會發現移動設備的配置還是遠比不上服務器的。
接下來我們來分析一個常用于圖片分類任務的AlexNet模型(一個深層次的CNN網絡模型),該模型的輸入是一張大小為152KB的圖片。首先對比一下模型在兩種環境下的運行情況:在云服務器上實施全部的計算操作和在移動設備上實施全部的計算操作。
如果我們僅僅看應用的延遲時間這一指標,(如下圖3)可以發現只要移動設備擁有可用的GPU,在本地GPU上實施所有的計算操作能夠帶來最佳的體驗(延遲時間最短)。而使用云服務器進行全部的計算時,統計表明計算所消耗的時間僅占全部時間的6%,而剩余的94%都消耗在數據傳輸上。
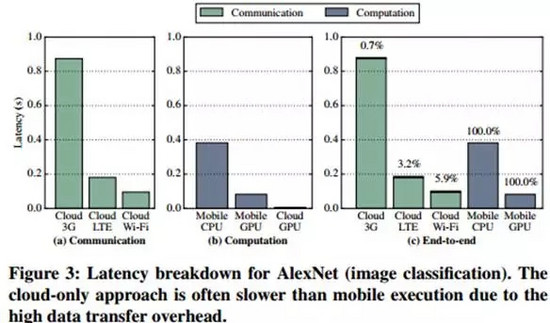
相較于現有方法,在LTE和3G網絡條件下,使用移動設備自身的GPU進行全部的計算能夠取得更低的系統延遲時間;同時,在LTE和Wi-Fi網絡條件下,現有方法要比單純僅用移動設備CPU進行全部的計算操作要更好(系統延遲時間更少)。
下圖4是不同網絡條件下,使用云服務器和手機CPU/GPU下的電量消耗情況:
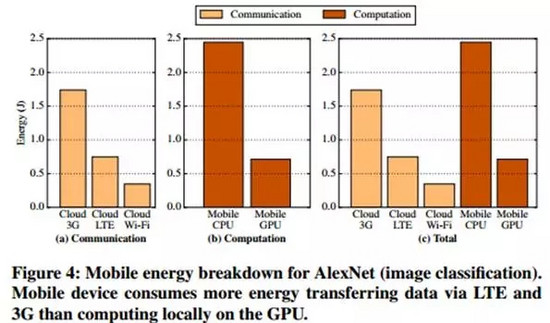
如果移動設備連接的是Wi-Fi網絡,最低的電量損耗方案是發送相應的數據到云服務器并讓其進行全部的計算操作。但如果連接的是3G或LTE網絡,如果該移動設備有可用的GPU,那么在本地GPU上實施全部的計算操作這一方案所導致的電量消耗,會比需要進行數據傳輸且在云服務器上實施全部的計算操作這一方案更低。
盡管云服務器的計算能力要強于移動設備,但由于其需要進行數據的傳輸(在有的網絡環境下的所帶來的系統延遲時間和電量消耗量并不小),所以從系統的角度,完全使用云服務器進行計算的方法并不一定是最優的。
▌ 各種網絡層的數據傳輸和計算需求并不相同
那么,在所有計算都實施在云服務器或移動設備上這兩種“相對極端”的方法之間,是否存在某個最優切分點呢?換言之,在數據傳輸和實施計算兩者之間或許存在一種折中。下圖是一張簡單的草圖,以方便理解接下來要做的事情。
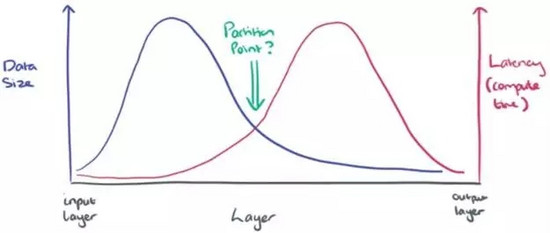
一種直觀的切分方法是基于DNN中網絡層作為邊界。以AlexNet為例,如果我們能夠計算出每一層的輸出數據量和計算量,將得到如下的統計圖(下圖5):
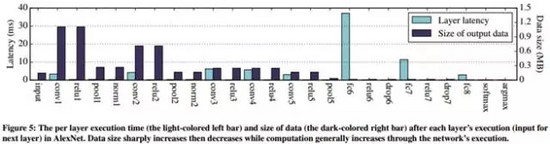
從圖5中可以看出,對于AlexNet模型較前的卷積層而言,數據輸出量隨著層數增加而迅速遞減。然而,計算量在模型的中后部分開始逐步遞增,在全連接層的計算量達到了最高的幅度。
接下來值得思考的是,如果我們將AlexNet模型中的各個網絡層分割開會發生什么呢?(也就是說,在移動設備上處理模型的前n層得到第n層的輸出結果,再將該輸出結果傳輸至云服務器上進行之后的計算,最后再將輸出結果傳輸至移動設備上。)
下圖6中你能看到AlexNet模型各層的延遲時間和電量消耗情況,最佳的分割點以星星符號表示。
以網絡層為粒度的分割算法能夠大大改善模型的延遲時間和電量消耗量。對于AlexNet模型,在移動設備GPU可用和Wi-Fi網絡條件下,最佳的分割點處于模型的中部。
以上只是針對AlexNet模型的分割方法。然而,這種分割方法是否同樣適用于其他的用于處理圖像、視頻、語音和文本的DNN模型們?文章作者在多種DNN模型上做了相應的分析如下表3:
對于應用于計算機視覺 (Computer Vision, CV) 領域的具有卷積層的模型,通常最佳的分割點在模型的中部。而對于通常只有全連接層和激活層的ASR, POS, NER和CHK網絡模型(主要應用在語音識別(Automatic Speech Recognition, ASR)和自然語言處理領域(Natural Language Process, NLP))而言,只能說有找到最佳的分割點的可能。
在DNN模型上進行分割的最佳方法取決于模型中的拓撲層和結構層。CV領域的DNN模型有時在模型的中部進行分割是最好的,而對于ASR和NLP領域的DNN模型,在模型的開始部分或者結尾部分進行分割往往更好一點。可以看出,最佳分割點隨著模型的不同而變化著,因此我們需要一種系統能夠對模型進行自動的分割并利用云服務器和設備GPU進行相應的計算操作。
▌Neurosurgeon的工作原理
對于一個DNN模型,影響最佳的分割點位置的因素主要有兩種:一種是靜態的因素,例如模型的結構;一種是動態的因素,例如網絡層的可連接數量、云服務器上數據中心的負載以及設備剩余可用的電量等。
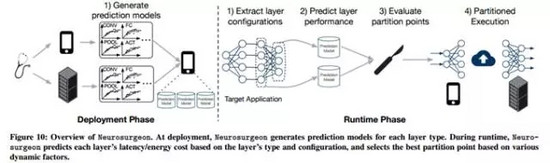
由于以上動態因素的存在,我們需要一種智能系統來自動地選擇出DNN中的最佳分割點,以保證最終系統延遲時間和移動設備的電池消耗量達到最優的狀態。因此,我們設計了出這樣一種智能切分DNN模型的系統,也就是Neurosurgeon。
Neurosurgeon由以下兩個部分組成:一部分是在移動設備上一次性地創建和部署用于預測性能(包括延遲時間和電量消耗量)的模型,另一部分是在服務器上對各種網絡層類型和參數(包括卷積層、池化層、全連接層、激活函數和正則化項)進行配置。前一部分與所用的具體DNN模型結構無關,預測模型主要是根據DNN模型中網絡層的數量和類型來預測延遲時間和電量消耗,而不需要去執行具體的DNN模型。
預測模型會存儲在移動設備中,之后會被用于預測DNN模型中各層的延遲時間和電量消耗。
在DNN模型的運行時,Neurosurgeon就能夠動態地找到最佳的分割點。首先,它會分析DNN模型中各網絡層的類型和參數情況并執行之,然后利用預測模型來預測各網絡層在移動設備和云服務器上的延遲時間和電量消耗情況。根據所預測的結果,結合當前網絡層自身及數據中心的負載情況,Neurosurgeon選擇出最佳的分割點,調整該分割點能夠實現端到端延遲時間或者電量消耗的最優化。
▌Neurosurgeon的實際應用
之前的表3展示了用于評測Neurosurgeon的8種DNN模型,另外,實驗用到的網絡環境有3種(Wi-Fi,LTE和3G網絡)和2種移動設備硬件(CPU和GPU)。在這些模型和配置下,Neurosurgeon能夠找到一種分割方法以加速應用的響應時間至最優的98.5%。
實驗結果表明,相比于目前使用僅使用云服務器的方法,Neurosurgeon能夠將應用的延遲時間平均降低了3.1倍(最高能達到40.7倍)。
在電量消耗方面,相比于現有方法,Neurosurgeon能夠使得移動設備的電量消耗量平均降低至59.5%,最高能降低至94.7%。
下圖14展示了Neurosurgeon隨著網絡環境的變化(即LTE帶寬變化)自適應進行分割和優化的結果(下圖中的藍色實線部分),可以看出比起現有方法(下圖中的紅色虛線部分)能夠大幅度地降低延遲時間。
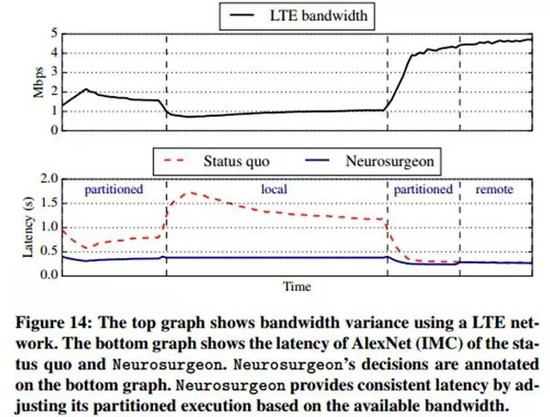
Neurosurgeon也會與云服務器保持周期性的通訊,以獲得其數據中心的負載情況。當服務器的數據中心負載較大時,它會減少往服務器上傳輸的數據量而增加移動設備本地的計算量。總之,Neurosurgeon能夠根據服務器的負載情況作出適當的調整已達到最低的系統延遲時間。
我們利用 BigHouse (一種服務器數據中心的仿真系統)來對比現有方法和Neurosurgeon。實驗中將query數據均勻地分配到之前表3中8種DNN模型之上,使用所測量的所有模型的平均響應時間,并結合Google網頁搜索中query的分布來得到query的完成率(query inter-arrival rate)。
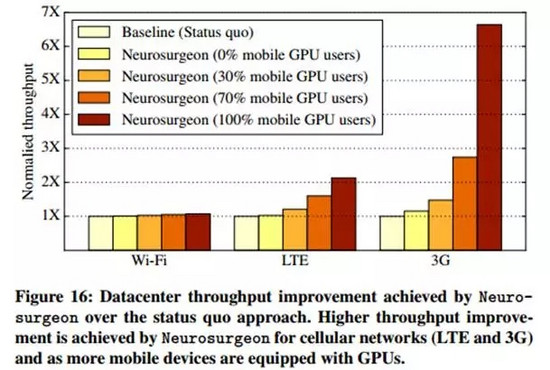
上圖16表明,在移動設備使用Wi-Fi網絡的條件下,Neurosurgeon所帶來的的數據吞吐量是現有方法的1.04倍。而隨著連接網絡質量的變差,Neurosurgeon會讓移動設備承擔更多的計算量,此時云服務器上數據中心的吞吐量將增加:較現有方法,連接LTE網絡的情況下數據中心的吞吐量增加至1.43倍,而3G網絡條件下則增加至2.36倍。
論文出處
Neurosurgeon:collaborative intelligence between the cloud and mobile edge Kang et al.,ASPLOS’17
http://web.eecs.umich.edu/~jahausw/publications/kang2017neurosurgeon.pdf