開源IndexR:如何對上千億的數(shù)據(jù)進(jìn)行秒級探索式分析
在當(dāng)前信息大爆炸的時代,“大數(shù)據(jù)”已成為互聯(lián)網(wǎng)行業(yè)人人談?wù)摰臒嵩~和話題,比如近幾年快速發(fā)展的基于大數(shù)據(jù)進(jìn)行精準(zhǔn)用戶定向的程序化廣告,以及去年馬云提出的利用大數(shù)據(jù)重塑商品的生產(chǎn) - 流量 - 銷售流程的“新零售”模式等。大數(shù)據(jù)已經(jīng)滲透到眾多的行業(yè),為許多企業(yè)帶來了變革性影響。那么,何為“大數(shù)據(jù)”呢?大數(shù)據(jù)(Big Data),可以簡單的理解為無法在一定時間范圍內(nèi)用常規(guī)手段進(jìn)行處理的海量數(shù)據(jù)集合。所有企業(yè)的業(yè)務(wù)分析都是基于數(shù)據(jù)的,每家企業(yè)對數(shù)據(jù)的收集、整合及處理能力在一定程度上決定了企業(yè)的業(yè)務(wù)發(fā)展水平。因此,提升數(shù)據(jù)分析性能也是當(dāng)前許多企業(yè)共同面臨的重大挑戰(zhàn)。
行業(yè)現(xiàn)狀
目前,行業(yè)中的大數(shù)據(jù)分析架構(gòu)一般使用基于 Hadoop 體系的分布式計算引擎 + 分布式存儲系統(tǒng)架構(gòu)(如下圖)。
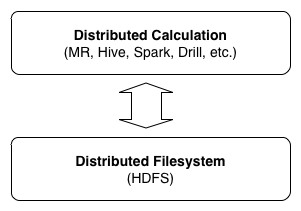
Hadoop 體系的架構(gòu)特點是上層解決計算問題,下層解決存儲問題。它可以讓開發(fā)者在不了解分布式底層細(xì)節(jié)的情況下,進(jìn)行分布式程序的開發(fā)。但是,這種架構(gòu)同時也存在一些問題:
1.整合工作量大
分布式存儲目前的標(biāo)準(zhǔn)比較統(tǒng)一,一般使用 HDFS。HDFS 能有效解決海量數(shù)據(jù)的存儲問題,并且有多種方便的工具鏈。但是,分布式計算引擎為了適應(yīng)不同場景,會有不同特性的數(shù)據(jù)倉庫工具,僅 Apache 就有 Hive、Spark、Drill、Impala、Presto 等產(chǎn)品,除此之外,還有獨(dú)立于 Hadoop 體系之外其它產(chǎn)品項目(如 ClickHouse、Kudu、Druid 等)。由于每個產(chǎn)品都有各自的特性,當(dāng)需要利用多個產(chǎn)品來解決不同問題時,就需要額外的整合工作,降低了工作效率。
2.數(shù)據(jù)交換速度慢
由于計算層必然是駐于內(nèi)存的,從存儲層到計算層的速度限制就成了系統(tǒng)的普遍瓶頸。有些系統(tǒng)為了加快速度全部使用內(nèi)存存儲(比如內(nèi)存數(shù)據(jù)庫、基于 Spark 的 SnappyData),這種方式在數(shù)據(jù)量較大時會造成巨大的成本壓力,因此目前還遠(yuǎn)未成為主流。
3.數(shù)據(jù)實時分析性差
由于文件系統(tǒng)的天然限制,數(shù)據(jù)一般是批量導(dǎo)入系統(tǒng)的。導(dǎo)入的時間會依據(jù)數(shù)據(jù)量的大小而有所不同,在數(shù)據(jù)量較大時常會出現(xiàn)入庫滯后現(xiàn)象,從而影響了數(shù)據(jù)分析的及時性。
因此,我們需要一個可以充分解決以上問題的大數(shù)據(jù)儲存格式,也就是筆者接下來要為大家介紹的 IndexR 開源大數(shù)據(jù)存儲數(shù)據(jù)庫。
IndexR 簡介
IndexR 是一個開源的大數(shù)據(jù)存儲格式(下載地址 https://github.com/shunfei/indexr),于 2017 年 1 月初正式開源,目前已經(jīng)更新至 0.5.0 版本。IndexR 旨在通過添加索引、優(yōu)化編碼方式、提高 IO 效率等各種優(yōu)化方式來提高計算層和存儲層的數(shù)據(jù)交換效率,從而提升整體性能。同時,IndexR 可以接收實時數(shù)據(jù),并對上層提供統(tǒng)一的數(shù)據(jù)接口。數(shù)據(jù)一旦到達(dá) IndexR 系統(tǒng)即可立刻進(jìn)行數(shù)據(jù)分析。
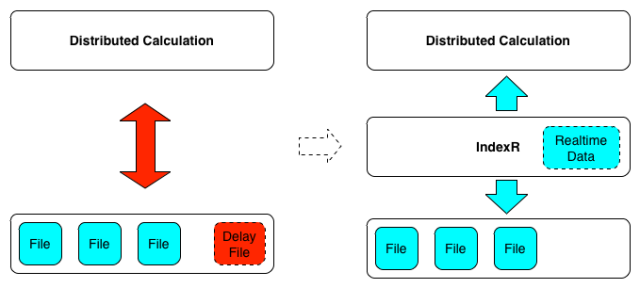
架構(gòu)剖析
基于 IndexR 系統(tǒng)的典型架構(gòu)示例如下:
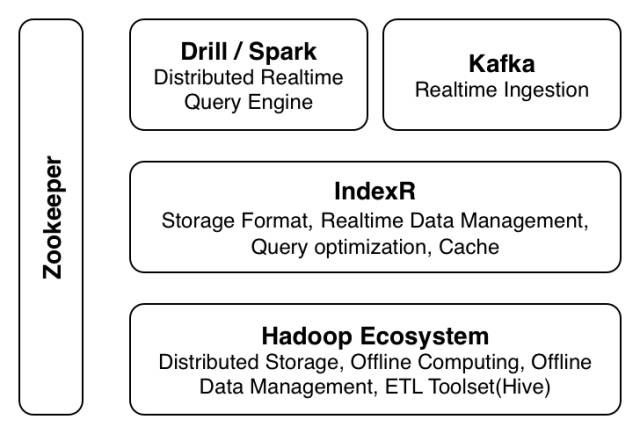
1.IndexR 為上層計算引擎提供數(shù)據(jù),相當(dāng)于對 IO 層做了整體的性能加速,提升了系統(tǒng)的分析能力。
2.IndexR 為下層數(shù)據(jù)存儲解決了在線分析和數(shù)據(jù)調(diào)用的問題,同時還能解決實時數(shù)據(jù)和歷史數(shù)據(jù)的分割問題。
- IndexR 能實時拉取 Kafka 的數(shù)據(jù)流,并打包上傳到 HDFS。整個數(shù)據(jù)層對于計算層是透明的。IndexR 通過結(jié)合實時數(shù)據(jù)和歷史數(shù)據(jù),保證了數(shù)據(jù)分析的實時性。
- 數(shù)據(jù)存放于 HDFS,不同的分析工具可同時分析同一份數(shù)據(jù)。
- 利用 Hadoop、Drill、Spark 等的分布式、高可用、可擴(kuò)展特點,解決海量數(shù)據(jù)場景的分析問題。
使用場景
IndexR 從開源至今,歷經(jīng)不同團(tuán)隊從調(diào)研、測試到***部署生產(chǎn)環(huán)境的實踐,已獲得了國內(nèi)外數(shù)十家團(tuán)隊的認(rèn)可(如尼爾森、佰安信息等),包括廣告、電商、AI 等領(lǐng)域的大型互聯(lián)網(wǎng)公司和創(chuàng)業(yè)團(tuán)隊以及政府、咨詢、物流等擁有超大數(shù)據(jù)集且對數(shù)據(jù)質(zhì)量有極高要求的行業(yè)。其中:尼爾森(Nielsen-CCData)使用 IndexR 產(chǎn)品服務(wù)全面支撐了其六大產(chǎn)品線的核心業(yè)務(wù),應(yīng)對海量數(shù)據(jù)的在線監(jiān)測、治理、分析以及復(fù)雜多變的智能化數(shù)據(jù)產(chǎn)品輸出,專注于全媒體與受眾研究業(yè)務(wù)。佰安信息則使用 IndexR 產(chǎn)品服務(wù)進(jìn)行公共信息的明細(xì)查詢與統(tǒng)計分析,單表數(shù)據(jù)量近 2 千億,每日入庫近 4 億條數(shù)據(jù)。
下面列舉幾種常見的使用場景:
- 替換 Parquet 等存儲格式:利用 IndexR 的性能和索引優(yōu)勢,加速查詢系統(tǒng)。
- 替換 Druid 等分布式系統(tǒng):利用 IndexR 實現(xiàn)實時入庫,進(jìn)行多維數(shù)據(jù)分析。
- 替換 MySQL、Oracle 等業(yè)務(wù)數(shù)據(jù)庫,或 ES、Solr 等搜索引擎:把統(tǒng)計分析工作移交到 IndexR 系統(tǒng),通過模塊分離,提高服務(wù)能力。
- 結(jié)合其他開源工具(如 Drill,搭建 OLAP 查詢系統(tǒng)):IndexR 基于 Hadoop 生態(tài)的特點及支持實時入庫、高效查詢的優(yōu)勢,能夠滿足當(dāng)前或未來對于 OLAP 系統(tǒng)的實時分析海量數(shù)據(jù)、線性擴(kuò)展、高可用、多功能、業(yè)務(wù)靈活等多種需求。數(shù)據(jù)分析不再被純預(yù)計算的局限性所困擾,且在線分析和離線分析可以使用同一份數(shù)據(jù),提高了數(shù)據(jù)利用率并降低了成本。
- 作為數(shù)據(jù)倉庫的存儲格式:利用 IndexR 存放海量歷史數(shù)據(jù),同時支持海量數(shù)據(jù)的實時入庫。數(shù)據(jù)使用方式包括明細(xì)查詢、在原始數(shù)據(jù)上做分析查詢和定期的預(yù)處理腳本。
IndexR 特性
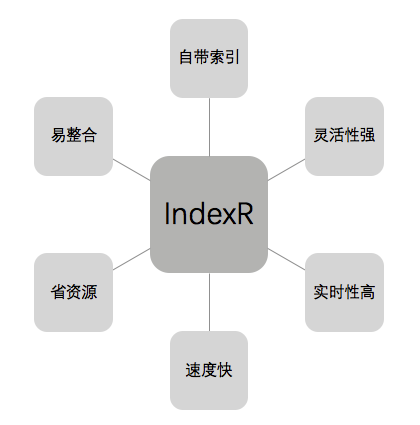
IndexR 具有六大特性:自帶索引、靈活性強(qiáng)、實時性高、速度快、省資源、預(yù)聚合。
1. 自帶索引:存儲格式自帶索引。
IndexR 包含三層索引,即粗糙集索引(Rough Set Index)、內(nèi)索引(Inner Index)和可選的外索引(Outer Index)。
目前的 On Hadoop 存儲格式如 ORC、Parquet 等都沒有真正的索引,只靠分區(qū)和利用一些簡單的統(tǒng)計特征如***最小值等大概滿足離線分析的需求。在服務(wù)在線業(yè)務(wù)時 On Hadoop 就顯得非常力不從心,需要從磁盤中讀取大量無用數(shù)據(jù)。事實上并不是每次查詢都需要獲取全部數(shù)據(jù),特別是 Ad-hoc 類型的查詢。而 IndexR 通過多層索引的設(shè)計,不僅極大地提高了 IO 效率,只讀取部分有效數(shù)據(jù),而且把索引的額外開銷降到了***。
一般傳統(tǒng)數(shù)據(jù)庫系統(tǒng)的索引設(shè)計是通過索引直接***具體的數(shù)據(jù)行,但這種方式只適用于 OLTP 場景,即每次查詢只獲取少量數(shù)據(jù),在 OLAP 場景下并不適合。OLAP 場景下每次查詢可能要涉及上萬甚至上億行數(shù)據(jù),這樣的索引設(shè)計開銷極大(內(nèi)存、IO、CPU),并會帶來磁盤隨機(jī)讀的問題,很多時候還不如直接對原始數(shù)據(jù)進(jìn)行掃描更加快速。
IndexR 的索引設(shè)計是分層的。打個比喻,如果要定位全國具體的某個街道,傳統(tǒng)的方式是把“省市 - 街道”組成一個索引,而 IndexR 是通過把“街道”映射在相應(yīng)的“省市”的集合(Pack)里,然后再在具體的集合了里做細(xì)致的索引。
- Rough Set Index - 粗糙集索引的工作方式類似于熟知的 Bloom Filter,它的特點是成本極低,速度超快,幾乎不會對查詢有性能損耗。IndexR 數(shù)據(jù)格式通過粗糙集索引快速定位區(qū)域塊,所以并不依賴分區(qū)。
- Outer Index - 外索引目前使用倒排索引和 Bitmap,它的優(yōu)點是支持豐富的過濾條件,并且非常適合做交、并運(yùn)算。IndexR 對倒排索引的使用方式做了優(yōu)化,避免了在 Scan 場景下大量隨機(jī)讀或者巨大內(nèi)存使用的問題,并且把 Bitmap 的 merge 操作做了加速處理,不會出現(xiàn)范圍條件(大于、小于)下的大量 merge 問題。
- Inner Index - 內(nèi)索引由具體的 Pack 內(nèi)部編碼特性決定,支持在壓縮狀態(tài)下對數(shù)據(jù)進(jìn)行過濾。具體查詢時 IndexR 先進(jìn)行粗糙集索引過濾,再對剩下的數(shù)據(jù)集進(jìn)行倒排索引過濾,然后把***的 Pack 直接加載入內(nèi)存,對其進(jìn)行高效的細(xì)致查詢。這種方式解決了分布式架構(gòu)、海量數(shù)據(jù)場景下索引困難的問題,避免了隨機(jī)讀問題,不管是在需要大范圍掃描還是少量數(shù)據(jù)查詢都更加高效。
2. 靈活性強(qiáng):雙存儲模式,適應(yīng)不同場景。
- vlt 模式 - 默認(rèn)模式,適用于絕大部分場景。特點是速度極快,遍歷速度比 Parquet 快 2~4 倍,支持倒排索引,且隨機(jī)查詢性能優(yōu)越。默認(rèn)情況下文件大小是 Parquet 的 75%。
- basic 模式 - 壓縮率極高,可達(dá) 10:1,一般文件大小是 Parquet 的 1/3。并且仍然保持非常高的讀取性能,優(yōu)于其他開源格式。適用于存放超大量歷史數(shù)據(jù),并支持隨時快速訪問。
3. 實時性高:支持流式導(dǎo)入,實時分析。
目前的 Hadoop 生態(tài)對于實時的數(shù)據(jù)分析還是比較困難。Storm、Spark Streaming 等系統(tǒng)屬于對數(shù)據(jù)進(jìn)行預(yù)計算,在業(yè)務(wù)頻繁改動或需要對原始數(shù)據(jù)進(jìn)行啟發(fā)式分析(Ad-hoc)的情況下沒法滿足需求。而 Druid、Kudu 等系統(tǒng)雖然支持實時寫入,但其體系自成,在實際運(yùn)用中常會出現(xiàn)部署、整合甚至性能方面的問題。
IndexR 支持實時數(shù)據(jù)寫入,比如從 Kafka 導(dǎo)入,并且數(shù)據(jù)到達(dá)系統(tǒng)之后可以立刻被分析。它與 Hadoop 生態(tài)的無縫整合也使得它在業(yè)務(wù)設(shè)計上非常靈活。目前 IndexR 單表單節(jié)點入庫速度每秒超過 3w 條數(shù)據(jù),入庫速度會隨著節(jié)點數(shù)量呈線性增加,每個表使用單獨(dú)線程,表間互不影響。此外,對于 OLAP 型的多維分析場景,IndexR 還支持實時、離線預(yù)聚合處理,將指標(biāo)基于維度進(jìn)行預(yù)先組織,大大減少了數(shù)據(jù)量,數(shù)據(jù)分析更加快速。
4. 速度快:媲美內(nèi)存數(shù)據(jù)庫。
IndexR 使用深度優(yōu)化的編碼方式,大大加快了數(shù)據(jù)解析,甚至可以媲美一些內(nèi)存數(shù)據(jù)庫。它的數(shù)據(jù)組織形式根據(jù)向量化執(zhí)行的特點定制,把全部數(shù)據(jù)存放于堆外內(nèi)存,并且優(yōu)化到各個 byte 的組織方式,把 JVM 的 GC 和虛函數(shù)開銷降到***。
IndexR 是基于 Hadoop 的數(shù)據(jù)格式,意味著文件存放于 HDFS,這樣可以非常方便地利用 HDFS 本身的高可用特性保證數(shù)據(jù)安全,并且可以方便的使用 Hadoop 生態(tài)上的所有分析工具。IndexR 對基于 HDFS 的文件讀取做了大量的優(yōu)化,把計算盡量分發(fā)到離數(shù)據(jù)最近的本地節(jié)點,HDFS 層的開銷基本被剔除,與直接讀取本地數(shù)據(jù)無異。
以下是使用 TPC-H 數(shù)據(jù)集,IndexR 與 Parquet 格式在相同的 Drill 集群上做的一個性能對比。
***表 lineitem 數(shù)據(jù)總量 6 億,5 個節(jié)點,節(jié)點配置 [Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz] x 2, RAM 64G(實際使用約 12G), HDD STATA with 7200RPM。
IndexR 與 Parquet 的 Hive 表 schema 都沒有設(shè)置 TBLPROPERTIES,使用默認(rèn)參數(shù)。
- 單項性能對比
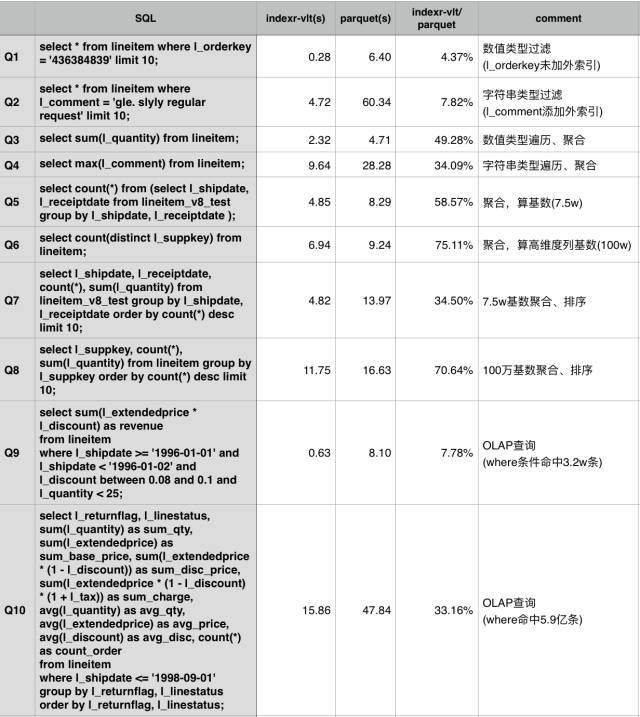
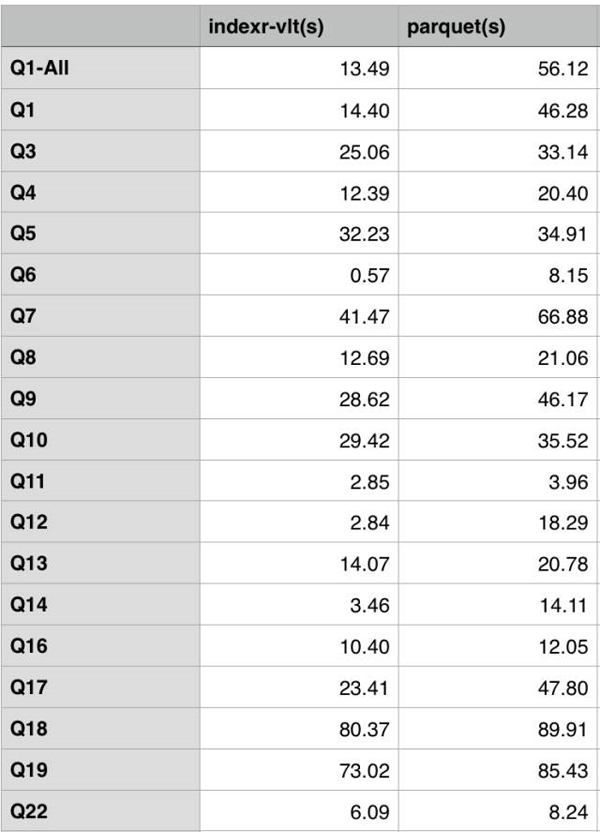
柱狀圖:
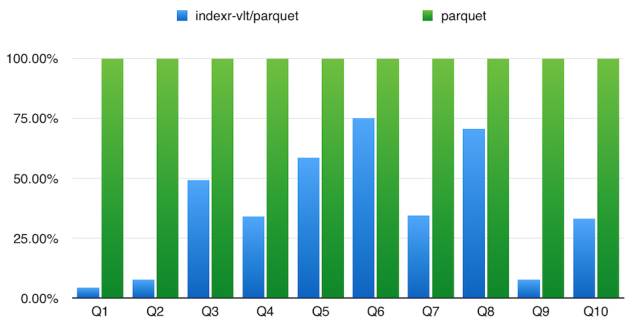
- 使用 TPC-H 標(biāo)準(zhǔn)測試 SQL,SQL 內(nèi)容可以在 http://www.tpc.org/tpch/ 上獲取(貼出來太長了),覆蓋了包 Join、子查詢等常見統(tǒng)計分析查詢 SQL,where 條件***的數(shù)據(jù)量一般超過***表的 50%。其中 Q2,Q15 等 SQL 由于 Drill 不支持沒有顯示。
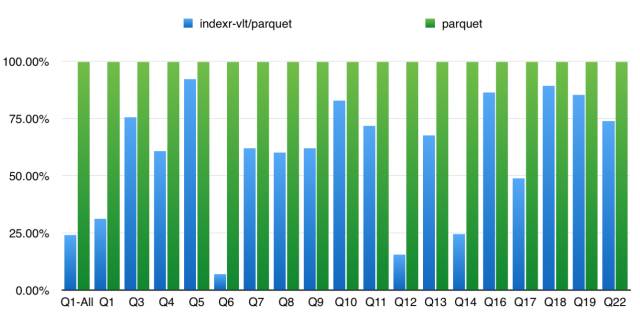
柱狀圖:
5. 省資源:減少內(nèi)存使用量
為了避免 Java 中對象和抽象的開銷,IndexR 的代碼大量使用了 Code C In Java 的編程風(fēng)格(調(diào)侃),通過內(nèi)存結(jié)構(gòu)而非接口進(jìn)行解耦。緊湊的內(nèi)存結(jié)構(gòu)減少了尋址開銷,且非常利于優(yōu)化 JVM 的運(yùn)行。IndexR 在保證了高性能、有效索引的基礎(chǔ)上極大地節(jié)省了內(nèi)存,與使用 Parquet 格式查詢時的內(nèi)存使用量差不多,不會出現(xiàn)像 CarbonData 需要配置超大內(nèi)存的情況。但是為什么不直接使用 C 或者 C++ 呢?因為目前 Hadoop 生態(tài)最適合的開發(fā)語言還是基于 JVM,JVM 語言可與其他系統(tǒng)無縫集成,在工具鏈支持方面也是最全面的。
6. 易整合:深度整合 Hadoop 生態(tài)。
IndexR 通過與 Hadoop 生態(tài)的深度整合,適合用來搭建海量數(shù)據(jù)場景下的數(shù)據(jù)倉庫。
IndexR 與行業(yè)通用方案對比:
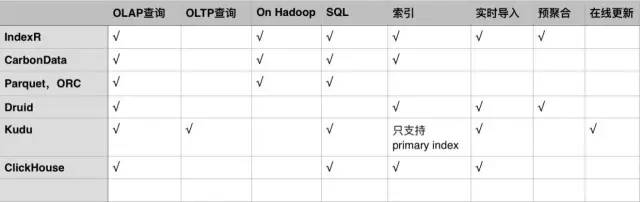
- Parquet,ORC - 他們與 IndexR 一樣都屬于存儲格式,功能上比較類似。目前 IndexR 還不支持較復(fù)雜的數(shù)據(jù)格式,但額外支持索引、實時導(dǎo)入、預(yù)聚合等特性。
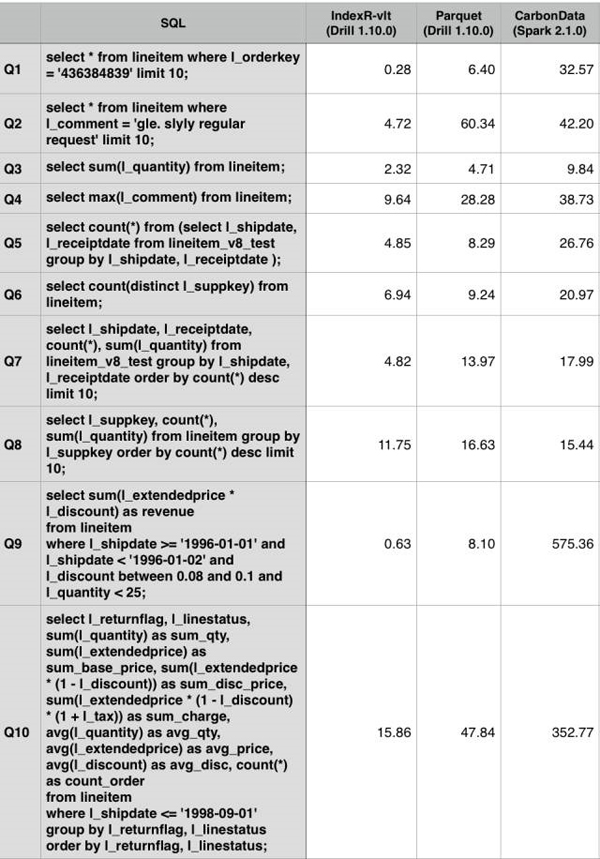
- CarbonData - CarbonData 也是用于大數(shù)據(jù)分析場景的數(shù)據(jù)格式,并且支持索引,官方文檔稱適用于大量數(shù)據(jù)掃描和少量數(shù)據(jù)查詢的場景,與 IndexR 在存儲格式上的定位非常相近。同樣 IndexR 還額外支持實時導(dǎo)入、預(yù)聚合等特性。筆者嘗試使用 CarbonData 與 IndexR 在相同的 Hadoop 集群上做性能對比,發(fā)現(xiàn) CarbonData 的表現(xiàn)不穩(wěn)定,特別是 Q9 和 Q10,以下是測試結(jié)果,歡迎同行討論。
使用以上測試相同集群,CarbonData 1.1.0, Hadoop 2.5.2, Spark 2.1.0. Spark 啟動參數(shù):bin/spark-submit --class org.apache.carbondata.spark.thriftserver.CarbonThriftServer --num-executors 5 --executor-cores 10 --executor-memory 31G carbonlib/carbondata_2.11-1.1.0-shade-hadoop2.2.0.jar hdfs://rttest/user/hive/warehouse/carbon.storeCarbonData 表 schema 沒有設(shè)置 TBLPROPERTIES,使用默認(rèn)參數(shù)。
- Druid - Druid 屬于時間序列數(shù)據(jù)庫,支持流式導(dǎo)入、實時預(yù)聚合,適用于 OLAP 場景。從架構(gòu)上,IndexR 基于 Hadoop,上層使用第三方查詢引擎,而 Druid 只是把文件備份到 Hadoop,數(shù)據(jù)讀取并不經(jīng)過 Hadoop。IndexR 系統(tǒng)支持完整的 SQL,而 Druid 使用自定義 JSON 查詢語句,不支持 SQL(目前有實驗 feature,但是支持非常有限),無法做 JOIN、UNION 等操作。此外,IndexR 還額外支持表結(jié)構(gòu)更新,且過期數(shù)據(jù)不會丟棄,在運(yùn)維方面也更加簡單。
- Kudu、ClickHouse - IndexR 和他們都可以用來做 OLAP 分析。Kudu 支持 OLTP 的大部分操作,包括數(shù)據(jù)插入、更新、刪除等;IndexR 和 ClickHouse 數(shù)據(jù)只能使用 append 的模式,并且不支持在線更新,目前只能使用分區(qū)管理。Kudu 和 ClickHouse 都獨(dú)立于 Hadoop 生態(tài)之外。