深度:阿里云分布式關系型數據庫DRDS解析
阿里云中間件產品經理鳳豪為本文中深度介紹了阿里云分布式關系型數據庫DRDS的發展歷史以及DRDS的優勢。下面是演講主要內容整理。
數據庫面臨的挑戰
單機數據庫在數據存儲容量、訪問容量、容災等方面都會隨著業務的增長而到達瓶頸,無論哪一個,對業務來說是一項相當艱巨的挑戰。存儲容量瓶頸問題,雖然可以通過在一個機器下面掛很多塊磁盤,做到10T、20T、30T容量,然后使用一個MySQL實例支撐,但是數據備份、數據管理(DDL)、數據檢索與更新性能(DML)都會出現大幅下滑。
單機數據庫的擴展方式通常有兩種:通過硬件升級的方式,或者采用分布式的存儲方案方式。但是單機數據庫使用分布式架構的同時,缺乏整體的長期的優化和產品化,對應用的侵入性非常大,造成開發和運維的成本大幅提高、降低產品穩定性。
DRDS 成熟的分布式架構,可以提供給用戶使用單機數據庫一致的體驗,底層通過分布式的架構輕松實現數據庫的高擴展性,降低開發成本的同時,也提升了數據庫存儲和服務擴展能力。
數據庫的挑戰也在于更高的數據容量承載,更高的數據庫服務性能支撐。數據庫關鍵能力在既要保持數據庫ACID特性和事務強一致性支持,又要具備***擴容和彈性擴展的能力。
DRDS與MySQL、NoSQL的區別
那我們怎么認識DRDS與MySQL、NoSQL之間的差異呢?具體來說,MySQL核心優勢是關系模型ACID特性和事務一致性,但MySQL在保持ACID特性一致性的原則下,單機數據庫的擴展給開發和運維帶來了巨大的成本。NOSQL則在拋棄關系模型特性的情況下,通過分布式的方式解決了數據庫的高擴展性,但是面對復雜多樣的關系模型的使用場景NOSQL不能作為一種通用的數據庫解決方案使用,且NOSQL推出的時間短,產品成熟度不高,系統穩定性和可運維行較差,對于正式生產環境使用風險仍舊很高。
分布式關系型數據庫DRDS則在保持關系模型的特性和數據庫高擴展性發做了很好的平衡,實現數據庫的高擴展性的同時,也***化的保持了關系型數據ACID特性和事務一致性。
DRDS產品在阿里巴巴集團內部的對應產品是TDDL,2008年開始大規模接入內部核心系統生產環境,是阿里巴巴近千核心應用***組件。DRDS在2014年6月開始公測,2014年12月DRDS正式上線時已穩定服務8年以上,是阿里巴巴8年技術沉淀的結晶。
DRDS突破數據庫極限
數據庫的***個極限就是高擴展性。
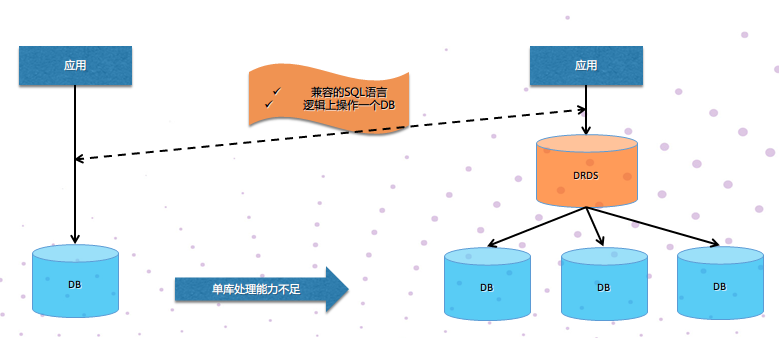
基于2008年左右分布式數據庫領域比較流行的數據拆分理論,淘寶開始自主研發分布式關系型數據庫服務來解決數據庫擴展的問題,并于2008年上線TDDL/DRDS服務,DRDS底層采用分布式的架構,通過“分而治之”拆分原理,將單機數據庫實例進行多實例拆分,依據拆分緯度將業務的數據拆分到單機數據庫實例集群上,同時保持對應用層使用邏輯上完全透明,應用層仍舊保持單機數據一致的使用方式,但是擴展性卻大大提升。
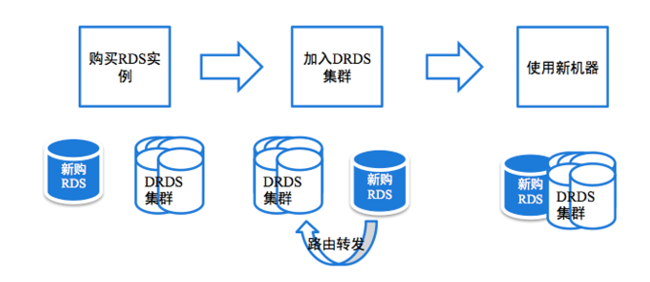
目前DRDS已經可以做到完全平滑的擴容,當數據庫的容量或者處理能力不足的時候,只需要簡單的“加機器”就能夠實現數據庫能力的線性擴展,而整個過程可以做到應用透明無感知。
分布式關系型數據庫的另外一個極大挑戰,在于分布式環境下跨庫SQL查詢效率。分布式架構下邏輯單庫單表數據會分拆到不同的物理分庫分表上,當分庫分表和業務源信息小表JOIN的時候,必然需要將分庫分表和小表數據先讀取然后做合并JOIN,這就造成存在大量的跨物理單庫的IO操作,分布式SQL的執行效率會大大降低,而DRDS的小表復制功能可以通過簡單的小表廣播配置,將JOIN的驅動小表配置成廣播表,將廣播表的數據實時廣播到分庫分表上,這樣就將跨庫的JOIN變成單機JOIN操作,系統的性能就得到了極大的提升。

分布式關系型數據庫的另外一個巨大極限挑戰在分布式數據庫的數據拆分緯度是單一的,而實際數據使用緯度多樣的。當數據拆分緯度和數據使用緯度不一致的時候,單條SQL會下發到多個物理的分庫執行,當分庫分表數量達到百甚至千級別的時候,大量的SQL下發和歸并操作也會造成巨大的IO性能消耗,造成系統的整體性能直線下降。
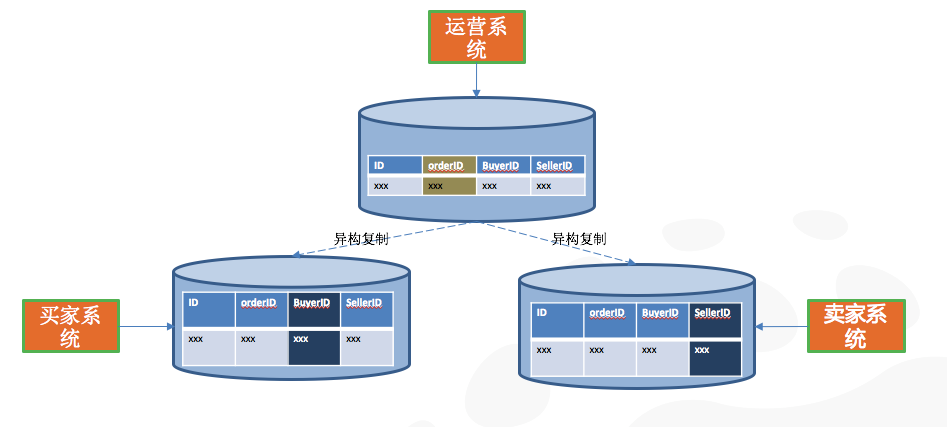
DRDS能夠通過異構復制的功能,使用“空間換性能”的方式將同一份數據冗余多份,多份數據按照不同的業務使用場景進行拆分,保持了業務使用緯度和數據拆分緯度的一致性,SQL跨庫查詢變成了物理單庫查詢,避免了大量IO操作,系統性能大幅提升。
DRDS提供的另外一個重要核心特性就是“透明讀寫分離”功能。讀寫分離是關系型數據庫使用頻度非常高的功能,但是傳統單機數據庫的讀寫分離和應用的耦合性非常高,應用需要從代碼層面分別操作讀實例和主實例、讀寫分離的讀寫流量分配、讀實例的擴容以及特定SQL讀寫路由也需要修改代碼的來實現,這就造成了很大運維成本,應用的代碼復雜度增加。同時,在面對突然暴增的業務流量情況下數據庫不能夠提供快速的讀寫分離擴容機制,對業務來說是非常大的不穩定因素。
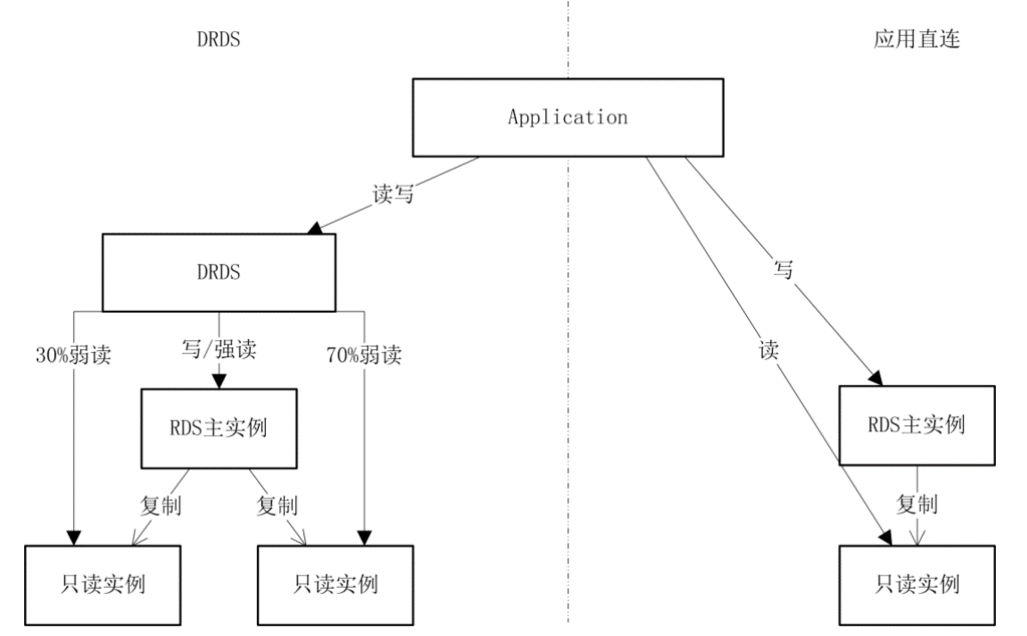
DRDS能夠做到對應用完全透明的讀寫分離,將數據庫和應用層完全解耦,應用不需要關心底層的讀寫分離的路由具體實現,數據庫的連接串不需要修改。只需要在控制臺增加只讀實例和配置讀寫流量分配比例,DRDS就可以依據SQL進行讀寫路由,同時可以實時在控制臺變更和查詢讀寫流量的分配比例,對于一些特殊的SQL如果需要強制路由到讀實例或者主實例執行,也可以通過DRDS特性的hint語法實現差異化的路由規則,這對于數據庫的運維效率是質的提升。
透明的讀寫分離功能無論對于初創企業還是復雜業務場景的大型企業,都可以大大降低數據庫運維成本,降低應用代碼復雜度,短期內就可以具備專業的數據庫運維能力,系統的穩定性也得到很好的保證。
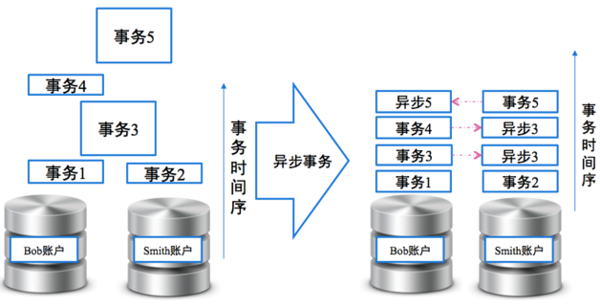
DRDS具有完整的分布式事務套件、***的支持分布式事務,DRDS可以做到“讀提交”級別的分布式事務支持,能夠滿足90%以上的事務需求場景。同時基于阿里云長期對事務的實踐得出的經驗,大部分的事務場景都不是真正的強一致的事務場景,建議通過異步的事務解耦,將強事務轉換為異步的事務序列,可以獲得系統擴展性和系統性能的大幅提升。
DRDS優勢
總體來講,DRDS突破了單機數據關系型數據庫強依賴硬件且擴展能力有限的困境,通過分布式集群架構方案真正實現了“***平滑擴容”。
DRDS具備高擴展性和專業的運維能力的同時保持了簡單易用的優勢,DRDS全面兼容MySQL協議和語法,支持大部分MySQL Client,通過DRDS提供的一鍵擴容,一鍵數據遷移,透明的讀寫分離功能可以幫助企業迅速獲得大型互聯網企業多年積累的專業數據庫運維能力。http://click.aliyun.com/m/24591/