分布式數據庫和Hadoop都不夠好,于是我們設計了分布式SQL計算系統
設計思想
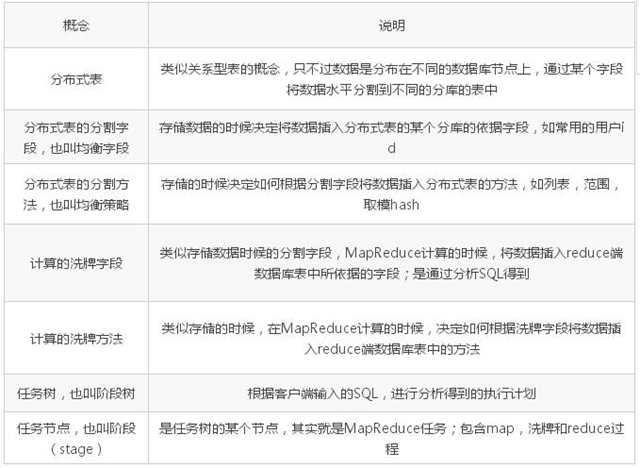
為了解決分布式數據庫下,復雜的 SQL(如全局性的排序、分組、join、子查詢,特別是非均衡字段的這些邏輯操作)難以實現的問題;在有了一些分布式數據庫和 Hadoop 實際應用經驗的基礎上,對比兩者的優點和不足,加上自己的一些提煉和思考, 設計了一套綜合兩者的系統,利用兩者的優點, 補充兩者的不足。具體的說, 使用數據庫水平分割的思想實現數據存儲,使用 MapReduce的思想實現 SQL 計算。
這里的數據庫水平分割的意思是只分庫不分表,對于不同數量級別的表,分庫的數量可以不一樣,例如 1 億的數據量分 10 個分庫,10 億的分 50 個分庫。對于使用 MapReduce的思想實現計算 ; 對于一個需求,轉換成一個或多個有依賴關系的SQL,其中的每個SQL分解成一個或多個 MapReduce任務,每個 MapReduce任務又包含 mapsql、洗牌(shuffle)、reducesql,這個過程可以理解為類似 hive,區別是連 MapReduce任務中的 map 和 reduce 操作也是通過 SQL 實現, 而非 Hadoop 中的 map 和 reduce 操作.
這是基本的 MapReduce的思想,但是在 Hadoop 的生態圈中, ***代的 MapReduce將結果存儲于磁盤,第二代的 MapReduce根據內存使用情況將結果存儲于內存或磁盤,類比一下用數據庫來存儲,那么 MapReduce 的結果就是存儲在表中,而數據庫的緩存機制天然支持根據內存情況決定存儲在內存還是磁盤 ; 另外,Hadoop 生態圈中, 計算模型也并非一種,這里的 MapReduce的計算思想,可以用類似 spark 的 RDD 迭代計算方式來替代 ; 本系統還是基于 MapReduce來說明的。
架構
根據以上的思想, 系統的架構如下:
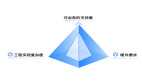
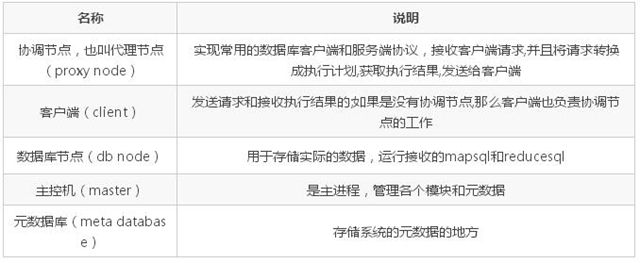
沒有代理節點
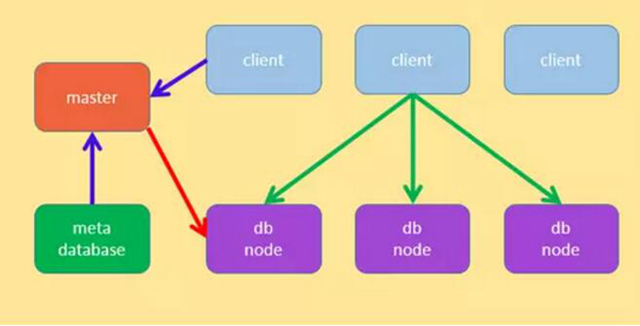
有代理節點
模塊說明
關于系統中的模塊,由于和絕大部分的分布式系統類似,這里僅做簡要說明:
兩種架構的區別
無代理節點的時候,客戶端擔負著比較大的工作,包括:發送請求、解析 SQL、生成執行計劃、申請資源、安排執行、獲取結果等;有代理節點的時候,代理節點擔負著接受請求、解析 SQL、生成執行計劃、申請資源、安排執行、返回結果給客戶端等大部分責任,另外代理節點提供支持外部協議的接口,如 mysql 的 c/s 協議,使用 mysql 的命令行可以直接連接進來執行 SQL,整個系統就像普通的 mysql server 一樣。
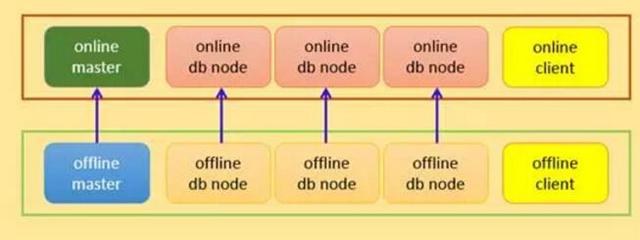
應用架構
實際應用環境可能是正式環境一套, 正式備份環境一套, 線下環境一套, 可以按照如下的架構進行部署。
基本概念 說明
下面針對架構中的一些概念做些說明
增刪改操作
當插入數據的時候,根據均衡字段和均衡策略將記錄插入到對應的數據庫節點中。
當更新數據的時候,需要根據均衡策略判斷數據更新前的和更新后的數據庫節點是否變化:如果沒有變化,直接更新;如果有變化,在更新前的數據庫節點中刪除老數據,在更新后的數據庫節點中插入新數據。
當刪除數據的時候,根據均衡策略在相應的數據庫節點中刪除。
這三種變更數據的操作,只要涉及到多個節點的數據變更,都需要使用分布式事務保證一致性、原子性等事務特性。
查詢操作
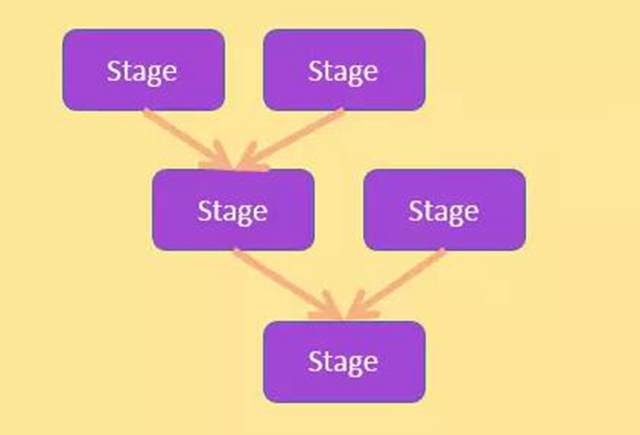
查詢操作的原理類似 hive,大家可以對比來理解 ; 為了方便解釋查詢操作, 首先來說明階段樹和階段的結構,如下圖所示:
階段樹
階段
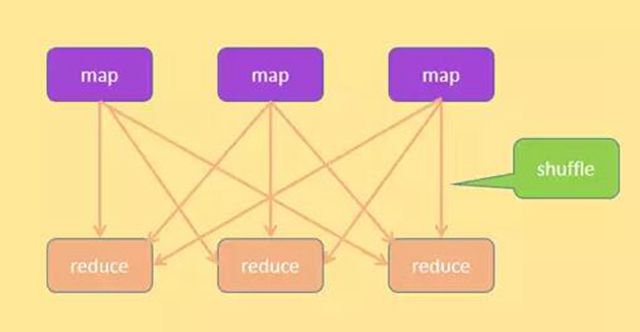
查詢步驟
結合上面的圖, 查詢操作的具體過程如下:
- 將輸入 SQL 經過詞法、語法、語義分析,集合表結構信息和數據分布信息,生成包含多個階段(簡稱 stage)的執行計劃,這些階段具有一定的依賴關系,形成多輸入單輸出的任務樹。
- 每個階段包括兩種 SQL,稱為 mapsql 和 reducesql,另外每個階段包括三個操作,map、數據洗牌和 reduce;map 和 reduce 分別執行 mapsql 和 reducesql。
- 先在不同的數據庫節點中執行 map 操作,map 操作執行 mapsql,它的輸入是每個數據庫節點上的表內部的數據,輸出根據某個字段按照一定的規則進行分割,放到不同的結果集中,結果集作為數據洗牌的輸入。
- 然后執行數據洗牌的過程,將不同結果集拷貝到不同的將要執行 reduce 的數據庫節點上。
- 在不同的數據庫節點中執行 reduce 操作,reduce 操作執行 reducesql;
- ***返回結果。
例子
由于系統核心在于存儲和計算, 下面對存儲和計算相關的概念舉例說明
均衡策略
舉例說明均衡策略,基本信息如下:表名字:tab_user_login表描述:用于存儲用戶登錄信息節點數:4,分為 0、1、2、3
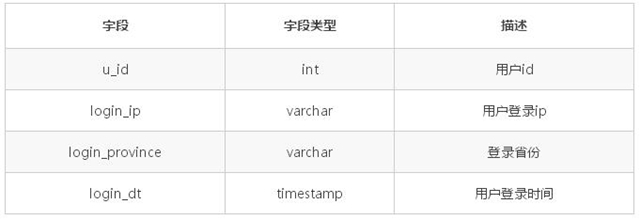
舉例說下如下的幾種策略:
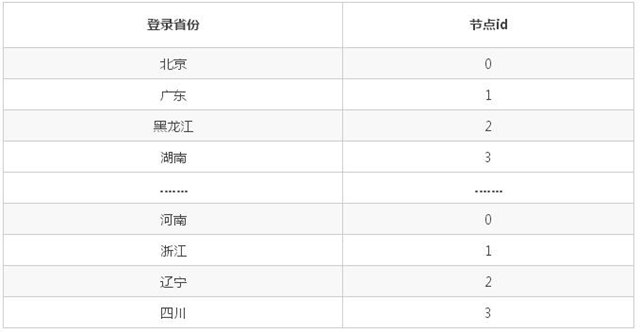
列表:以登錄省份作為均衡字段為例
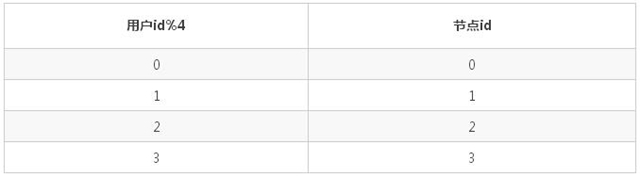
取模 hash:按 4 取模, 以用戶 id 作為均衡字段
范圍: 從 0 到一億,以用戶 id 作為均衡字段

取模 hash 和范圍結合:先范圍,再取模, 以用戶 id 作為均衡字段

查詢
舉例說明查詢操作,基本信息如下:
用戶表 tab_user_info 如下:
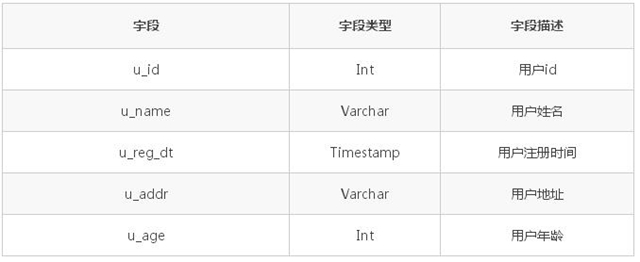
用戶登錄表 tab_login_info 的結構如下:
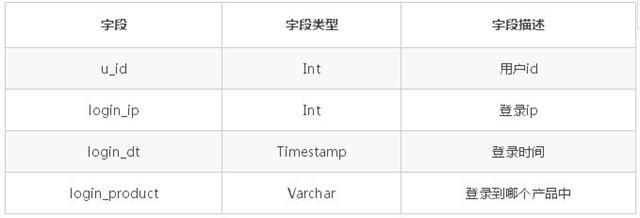
排序
排序的關鍵點是節點之間存在大小關系,大的 key 或者 key 范圍放到節點 id 大的節點上,然后在節點上排序,獲取數據的時候根據節點 id 大小依次獲取。
以如下 sql 為例,某一注冊時間范圍內的用戶信息,按照年齡和 id 排序:
- select * from tab_user_info t where u_reg_dt>=? and u_reg_dt<=? order by u_id
執行計劃可能為:
Map:
- select * from tab_user_info t where u_reg_dt>=? and u_reg_dt<=? order by u_id
Shuffle:
執行完成之后,這種情況下由于需要按照 u_id 進行數據洗牌,所以各個存儲節點上需要按照 u_id 進行劃分。例如有 N 個計算節點,那么按照(*** u_id- 最小 u_id)/N 平均劃分,將不同存儲節點上的同一范圍的 u_id,劃分到同一個計算節點上即可(這里的計算節點存在大小關系)。
Reduce:
- select * from tab_user_info t order by u_id
分組聚合
關鍵點和排序類似,節點之間存在大小關系,大的 key 或者 key 范圍放到節點 id 大的節點上,然后在節點上分組聚合,獲取數據的時候根據節點 id 大小依次獲取。
以如下 sql 為例,某一注冊時間范圍內的用戶,按照年齡分組,計算每個分組內的用戶數:
- select age,count(u_id) v from tab_user_info t where u_reg_dt>=? and u_reg_dt<=? group by age
執行計劃可能為:
Map:
- select age,count(u_id) v from tab_user_info t where u_reg_dt>=? and u_reg_dt<=? group by age
Shuffle:
執行完成之后,這種情況下由于需要按照 age 進行數據洗牌,考慮到 age 的唯一值比較少,所以數據洗牌可以將所有的記錄拷貝到同一個計算節點上。
Reduce:
- select age,sum(v) from t where group by age
連接
首先明確 join 的字段類型為數字類型和字符串類型,其他類型如日期可以轉換為這兩種。數字類型的排序很簡單,字符串類型的數據排序需要確定規則,類似 mysql 中的 collation,比較常用的是按照 unicode 編碼順序,按照實際存儲節點的大小等;其次 join 的方式有等值 join 和非等值 join;以如下常用且比較簡單的情況為例。
以如下 sql 為例,某一注冊時間范圍內的用戶的所有登錄信息:
- select t1.u_id,t1.u_name,t2.login_product
- from tab_user_info t1 join tab_login_info t2
- on (t1.u_id=t2.u_id and t1.u_reg_dt>=? and t1.u_reg_dt<=?)
執行計劃可能為:
Map:
由于是 join,所有的表都要進行查詢操作,并且為每張表打上自己的標簽,具體實施的時候可以加個表名字字段,在所有存儲節點上執行
- select u_id,u_name from tab_user_info t where u_reg_dt>=? and t1.u_reg_dt<=?
- select u_id, login_product from tab_login_info t
Shuffle:這種情況下由于需要按照 u_id 進行數據洗牌,考慮到 u_id 的唯一值比較多,所以各個存儲節點上需要按照 u_id 進行劃分,例如有 N 個計算節點,那么按照(*** u_id- 最小 u_id)/N 平均劃分,將不同存儲節點上的同一范圍的 u_id,劃分到同一個計算節點上。
Reduce:
- select t1.u_id,t1.u_name,t2.login_product
- from tab_user_info t1 join tab_login_info t2
- on (t1.u_id=t2.u_id)
子查詢
由于子查詢可以分解成具有依賴關系的不包含子查詢的 SQL,所以生成的執行計劃,就是多個 SQL 的執行計劃按照一定的依賴關系進行依次執行。
與已有系統的區別和優點
- 相比 hdfs 來說,數據的分布是有規則的,hdfs 需要啟動之后執行命令去查詢文件具體在什么節點上;元數據的較小,記錄規則即可,管理成本較低,在啟動速度方面很快。
- 數據是放在數據庫中的,可以很好的使用索引和數據庫本身的緩存機制,大大提高數據查詢的效率,特別是在大量數據的情況下,利用索引查詢返回少量的數據。
- 數據可以進行刪除和修改,這在基于 hdfs 的系統中一般比較麻煩和低效。
- 在計算方面,和 MapReduce 或者其他的分布式計算框架(如 spark)并沒有本質的區別(需要進行 shuffle)。但是由于數據的分布是有規則的,在有些地方可以做的更好,在分布式全文索引體現。
- 由于線上系統一般使用數據庫作為最終的存儲位置,而把數據庫同步到 hdfs 中是比較麻煩的,并且對于有刪除和更新的情況,同步數據麻煩低效,速度較慢;相比之下,這個方案可以使用數據庫本身提供的鏡像復制功能來同步,基本沒有額外的麻煩和低效的工作。
- 基于以上,可以把線上系統(主系統)和線下的數據分析挖掘(從系統)做成統一的方案, 參見應用架構圖。
應用場景
***列舉一些應用場景