千萬級日訂單下,餓了么異地多活數據實施DRC的應用實踐
今天,我主要分享餓了么多活的底層數據實施,和大家介紹在整個多活的設計和實施過程中,我們是怎么處理異地數據同步的,而這個數據同步組件在我們公司內部稱之為 DRC。
餓了么異地多活背景
在講 DRC 或者講數據復制之前,先跟大家回顧一下異地多活的背景。

去年,我們在做多活調研的時候,整個公司所有的業務服務都是部署在北京機房,服務器大概有四千多臺,災備的機器是在云端,都是虛擬機,大概有三千多臺。
當時,我們峰值的業務訂單數量已經接近了千萬級別,但是基本上北京機房(IDC)已經無法再擴容了,也就是說我們沒有空余的機架,沒有辦法添加新的服務器了,必須要再建一個新的機房。
于是,我們在上海新建一個機房,在今年的 4 月份投入使用,所以在上海機房建成之后,異地多活項目能具備在生產環境上進行灰度。
異地多活的底層數據同步實施
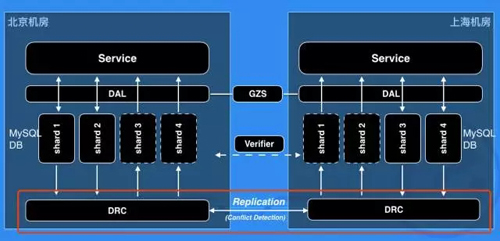
這是異地多活的底層數據同步實施的一個簡單的概要圖,大家可以看到,我們有兩個機房,一個是北京機房,一個是上海機房。
在這個時候,我們期望目標是北方所有的用戶請求、用戶流量全部進入北京機房,南方所有的用戶請求、用戶流量進入上海機房。
困難的地方是,這個用戶有可能今天在北方,明天在南方,因為他在出差,還有就是存在一些區域在我們劃分南北 shard 的時候,它是在邊界上面的,這種情況會加劇同一個用戶流量在南北機房來回漂移的發生。
還有個情況,當我們某個機房出現故障,如核心交換機壞掉導致整個機房服務不可用,我們希望可以把這個機房的所有流量快速切到另外的數據中心去,從而提高整個餓了么服務的高可用性。
以上所有的因素,都需要底層數據庫的數據之間是打通的。而今天我所要分享的 DRC 項目就是餓了么異地 MySQL 數據庫雙向復制的組件服務,即上圖中紅色框標記的部分。
異地多活對底層數據的要求
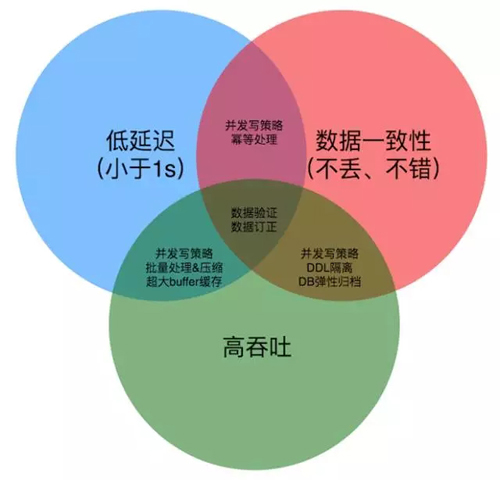
我們在前期調研 DRC 實現的時候,主要總結了的三點,而在后續的設計和實施當中,基本上也是圍繞這三點來去解決問題:
- 我們覺得是延遲要低,當時給自己定的目標是秒級的,我們希望在北京機房或上海機房寫入的數據,需要在 1 秒鐘之內同步到上海或者北京機房。整個延遲要小于 1 秒鐘。
- 我們要確保數據的一致性,數據是不能丟也不能錯的,如果出現數據的不一致性,可能會給上層的業務服務、甚至給產品帶來災難性的問題。
- 保證整個復制組件具備高吞吐處理能力,指的是它可以面對各種復雜的環境,比方說業務正在進行數據的批量操作、數據的維護、數據字典的變更情況。
這些會產生瞬間大量的變更數據,DRC 需要面對這種情況,需要具備高吞吐能力去扛住這些情況。
數據低延遲和一致性之間,我們認為主要從數據的并發復制這個策略上去解決,安全、可靠、高效的并發策略,才能保證數據是低延遲的復制,在大量數據需要復制時,DRC 并發處理才能快速在短時間內解決。
數據一致性,用戶的流量可能被路由到兩個機房的任何一個機房去,也就是說同樣一條記錄可能在兩個機房中被同時更改,所以 DRC 需要做數據沖突處理,最終保持數據一致性,也就是數據不能出錯。
如果出現沖突且 DRC 自身無法自動處理沖突,我們還提供了一套數據沖突訂正平臺,會要求業務方一道來制定數據訂正規則。
高吞吐剛才已經介紹了,正常情況用戶流量是平穩的,DRC 是能應對的,在 1 秒鐘之內將數據快速復制到對端機房。
當 DBA 對數據庫數據進行數據歸檔、大表 DDL 等操作時,這些操作會在短時間內快速產生大量的變更數據需要我們復制,這些數據可能遠遠超出了 DRC 的最大處理能力,最終會導致 DRC 復制出現延遲。
所以 DRC 與現有的 DBA 系統需要進行交互,提供一種彈性的數據歸檔機制,如當 DRC 出現大的復制延遲時,終止歸檔 JOB,控制每輪歸檔的數據規模。
如 DRC 識別屬于大表 DDL 產生的 binlog events,過濾掉這些 events,避免這些數據被傳輸到其他機房,占用機房間帶寬資源。
以上是我們在實施異地多活的數據層雙向復制時對 DRC 項目提出的主要要求。
數據集群規模(多活改造前)

這是我們在做多活之前的北京數據中心的數據規模,這個數據中心當時有超過 250 套 MySQL 的集群,一千多臺 MySQL 的實例,Redis 也超過四百個集群。
DRC 服務的目標對象就是這 250 套 MySQL 集群,因為在正在建設的第二個數據中心里未來也會有對應的 250 套 MySQL 集群,我們需要把兩個機房業務對等的集群進行數據打通。
多活下 MySQL 的用途分類
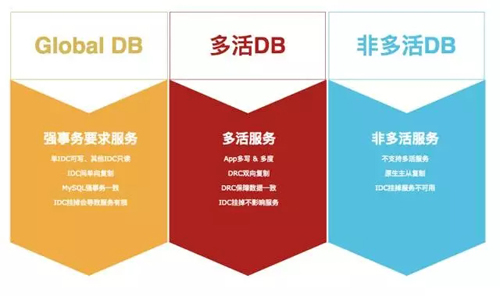
我們按照業務的用途,給它劃分了多種 DB 服務類型。為什么要總結這個呢?因為有一些類型,我們是不需要復制的,所以要甄別出來,首先第一個多活 DB,我們認為它的服務需要做多活的。
比方說支付、訂單、下單,一個機房掛了,用戶流量切到另外新的機房,這些業務服務在新的機房是工作的。
我們把這些多活服務依賴的 DB 稱為多活 DB,我們優先讓業務把 DB 改造成多活 DB,DRC 對多活 DB 進行數據雙向復制,保障數據一致性。
多活 DB 的優勢剛才已經講了,如果機房出現故障、核心交換機出問題,整個機房垮了,運維人員登不進機房機器,那么我們可以在云端就把用戶流量切到其它的機房。
有些業務對數據有強一致性要求,后面我會講到其實 DRC 是沒有辦法做到數據的強一致性要求的,它是有數據沖突發生的,需要引入數據訂正措施。
業務如果對數據有強一致性要求,比方說用戶注冊,要求用戶登錄名全局唯一(DB字段上可能加了唯一約束),兩個機房可能會在同一時間接收了相同用戶登錄名的注冊請求。
這種情況下,DRC 是無法自身解決掉這個沖突,而且業務方對這個結果也是無法接受的,這種 DB 我們會把它歸納到 GlobalDB 里面,它的特性是什么呢?
它的特性是單機房可寫,多機房可讀,因為你要保證數據的強一致性的話,必須讓所有機房的請求處理結果,最終寫到固定的一個機房中。
這種 DB 的上層業務服務,在機房掛掉之后是有損的。比方說機房掛了,用戶注冊功能可能就不能使用了。
最后一個非多活 DB,它是很少的,主要集中于一些后端的管理平臺,這種項目本身基本上不是多活的,所以這種 DB 我們不動它,還是采用原生的主備方式。
DRC 總體架構設計
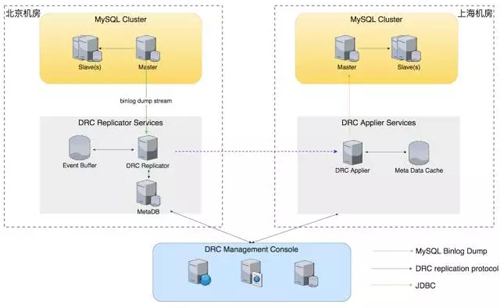
這是 DRC 復制組件的總體架構設計。我們有一個組件叫 Replicator,它會從 MySQL 集群的 Master 上把 binlog 日志記錄抽取出來,解析 binlog 記錄并轉換成我們自定義的數據,存放到一個超大的 event buffer 里面,event buffer 支持 TB 級別的容量。
在目標機房里,我們會部署一個 Applier 服務,這個服務啟一個 TCP 長連接到 Replicator 服務,Replicator 會不斷的推送數據到 Applier,Applier 通過 JDBC 最終把數據寫入到目標數據庫。
我們會通過一個 Console 控制節點來進行配置管理、部署管理以及進行各個組件的 HA 協調工作。
DRC Replicator Server
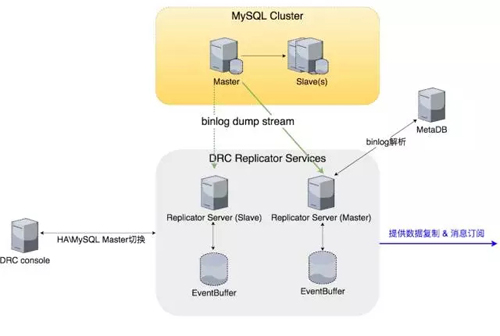
這是 DRC Replicator Server 組件比較細的結構描述,主要是包含了一個 MetaDB 模塊,MetaDB 主要用來解決歷史的 Binlog 的解析問題。
我們成功解析 Binlog 記錄之后,會把它轉換成我們自己定義的一種數據結構,這種結構相對于原生的結構,Size 更小,MySQL binlog event 的定義在 Size 角度上考慮事實上已經很極致了。
但是可以結合我們自己的特性,我們會把不需要的 event 全部過濾掉(如table_map_event),把可以忽略的數據全部忽略掉。我們比對的結果是需要復制的 event 數據只有原始數據 Size 的 70%。
DRC Applier Server
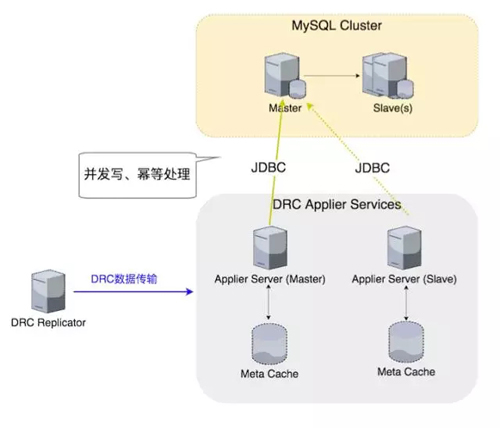
往目標的 MySQL 集群復制寫的時候,由 DRC Applier Server 負責,它會建一個長連接到 Replicator 上去,Replicator PUSH 數據給 Applier。
Applier 把數據拿到之后做事務的還原,最后通過 JDBC 把事務重新寫到目標 DB 里面,寫的過程當中,我們應用了并發的策略。
并發策略在提供復制吞吐能力,降低復制延遲上起到決定的作用,還有冪等也是非常重要的,后面有很多運維操作,還有一些 Failover 回退操作,會導致發生數據被重復處理的情況,冪等操作保障重復處理數據不會發生問題。
DRC 防止循環復制

在做復制的時候,大家肯定會碰到解決循環復制的問題。我們在考慮這個問題的時候,查了很多資料,也問了很多一些做過類似項目的前輩,當時我們認為有兩大類辦法。
第一大類辦法一開始否決了,因為我們對 MySQL 的內核原碼不熟悉,而且時間上也來不及,雖然我們知道通過 MySQL 的內核解決回路復制是最佳的、最優的。
靠 DRC 自身解決這個問題,也有兩種辦法:
- 一種辦法是我們在 Apply 數據到目標 DB 的時候把 binlog 關閉掉。
- 另外一種辦法就是寫目標 DB 的時候在事物中額外增加 checkpoint 表的數據,用于記錄源 DB的server_id。
后來我們比較了一下,第一個辦法是比較簡單,實現容易,但是因為 Binlog 記錄沒有產生,導致不支持級聯復制,也對后續的運維帶來麻煩。
所以我們最后選擇的是第二個辦法,通過把事務往目標 DB 復制的時候,在事務中 hack 一條 checkpoint 的數據來標識事務產生的原始 server,DRC 在解析 MySQL binlog 記錄時就能正確分辨出數據的真正來源。
DRC 數據一致性保障
在剛開始研發、設計的時候,數據一致性保障是我們很頭疼的問題。并不是在一開始就把所有的點都想全了,是在做的過程當中出現了問題,一步步解決的,回顧一下,我們大概從三個方面去保證數據的一致性:

首先,因為數據庫是多活的,我們必須從數據中心層面盡可能把數據沖突發生的概率降到最低,避免沖突,怎么避免呢?就是合理的流量切分,你可以按照用戶的維度,按照地域的維度,對流量進行拆分。
剛才我們講的,北方用戶的所有數據在北京機房,這些北方用戶的下單、支付等的所有操作數據都是在北方機房產生的,所以用戶在同一個機房中發生的數據變更操作絕對是安全的。
我們最怕的是同一個數據同時或者是在相近的時間里同時在兩個機房被修改,我們怕的是這個問題,因為這種情況就會引發數據沖突。所以我們通過合理的流量切分,保證絕大部分時候數據是不會沖突的。
第二個我們認為你要保障數據一致性,首先你要確保數據不丟,一旦發生可能數據丟失的情況,我們會做一個比較保險的策略,就是把數據復制的時間位置回退,即使重復處理數據,也避免丟數據的可能。
但是這個時候會帶來數據重復處理的問題,所以數據的冪等操作特別重要。
這些都是我們避免數據發生沖突的方法,那沖突實際上是不可避免的,沖突發生后,我們怎么解決?
最終采用的辦法是在數據庫表上隱含地加一個時間字段(數據最后更新時間),這個字段對業務是透明的,主要用來輔助 DRC 復制。
一旦數據發生沖突,DRC 復制組件可以通過這個時間來判斷兩個機房或者三個機房中的哪條數據是最后被更新的,最新優先的原則,誰最后的修改時間是最新的,就以它為準。
DRC 數據復制低延遲保障

剛才我們講的是數據的一致性,還有一個點非常重要,就是數據復制的低延遲保障。我們現在延遲包括用戶高峰時間也是小于 1 秒的,只有在凌晨之后,各種歸檔、批量數據處理、DDL 變更等操作會導致 DRC 延遲出現毛刺和抖動。
如果你的延遲很高的話,第一在做流量切換時,因為運維優先保障產品服務的可用性,在不得以的情況會不考慮你的復制延遲,不會等數據復制追平之后再切流量,所以你的數據沖突的概率就變的很大。
為了保證復制低延遲,我們認為主要策略、或者你在實施時主要的做法還是并發,因為你只有用高效的安全的并發復制策略,服務才有足夠的吞吐處理能力,而不至于你的復制通道因為遇到“海量”數據而導致數據積壓,從而加劇了復制延遲的產生。
我們一開始采用的基于表級別的并發,但是表級別的并發在很多情況下,并發策略沒辦法被有效的利用。
比方說有的業務線的數據庫可能 90% 的數據集中在一張表或者是幾個表里面,而大部分表數據量很小,那基于表的并發策略就并發不起來了。我們現在跑的是基于行級別的并發,這種并發它更能容忍和適應很多場景。
DRC & MySQL Master切換
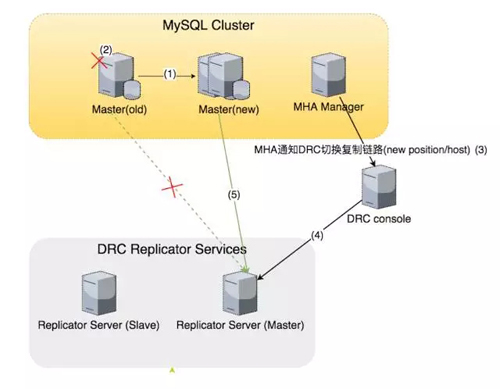
這個是 DRC 復制組件與 MySQL 集群的關系關聯圖,一旦 MySQL 集群里面的 Master 發生了主備切換,原來的 Master 掛了,DRC 怎么處理?
目前的解決方案是 DBA 系統的 MHA 工具會通知 DRC 控制中心,DRC 的控制中心會找到對應的復制鏈路,然后把復制鏈路從老的 Master 切到新的 Master。
但是關鍵點是 MHA 在通知之前先把老的 Master 設置為不可寫,阻斷 DRC 可能往老的 Master 繼續寫數據。
DRC 線上運行狀況(規模)

這個是我們 DRC 上線之后的運行狀況。現在大概有將近 400 多條復制鏈路。這個復制鏈路是指單向的鏈路。我們提供的消息訂閱大概有 17 個業務方接入,每天產生超過 1 億條的消息。
DRC 線上運行狀況(性能)
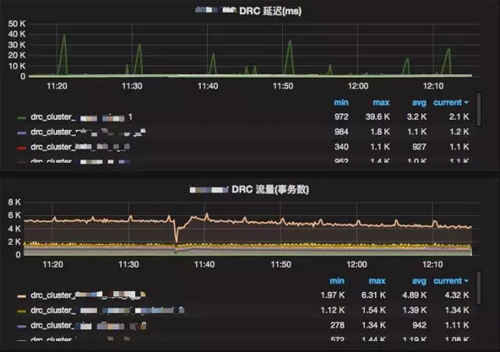
這是 DRC 線上運行的一個性能監控快照,我們可以看到,它是上午 11 點多到 12 點多的一個小時的性能,你會發現其實有一個 DB 是有毛刺的,有一個復制鏈路有毛刺,復制延遲最高達到 4s,但是大部分的復制鏈路的延遲大概也是在 1 秒或 1 秒以下。
陳永庭
餓了么框架工具部高級架構師
主要負責 MySQL 異地雙向數據復制,支撐餓了么異地多活項目。曾就職于 WebEx、Cisco、騰訊等公司。