













為什么要做多活?餓了么多活技術架構及運維挑戰
原創【51CTO.com原創稿件】餓了么業務快速發展,給技術帶來了海量請求和高并發、微服務的挑戰,同時開發團隊快節奏的版本迭代和服務快速上線的要求也驅動運維團隊提供穩定、高效的運維服務。
2017 年 12 月 01 日-02 日,由 51CTO 主辦的 WOTD 全球軟件開發技術峰會在深圳中州萬豪酒店隆重舉行。
餓了么技術運營負責人程炎嶺在創新運維探索專場與來賓分享了"跨越籬笆-餓了么多活運維上下求索"的主題演講,從業務發展和多活后的技術運營保障,結合具體案例,分享餓了么在運維方面的探索以及實踐經驗。
我是餓了么的技術運營負責人,見證了餓了么業務的飛速發展。記得 2015 年加入餓了么的時候,我們的日訂單量只有 30 萬筆;而到了 2017 年,我們的日訂單量已經超過 1000 萬筆。
考慮到我們在整個市場的體量和單個機房至多只能處理 2000 萬筆訂單的上限,我們逐步推進了面向***冗余多活的新規劃。
今天的分享主要分為三個部分:
- 多活場景及業務形態
- 餓了么多活運維挑戰
- 餓了么運營體系探索
多活場景及業務形態
餓了么多活的現狀

首先介紹一下餓了么整個多活的現狀:我們在北京和上海共有兩個機房提供生產服務。機房和 ezone 是兩個不同的概念,一個機房可以擴展多個 ezone,目前是一對一關系。
我們還有兩個部署在公有云的接入點,作為全國流量請求入口。它們分別受理南北方的部分流量請求,接入點都部署在阿里云上面,同時從運維容災角度出發。
我們考慮到兩個云入口同時“宕掉”的可能性,正在籌建 IDC 內的備用接入點,作為災備的方案。
多活從 2017 年 5 月份的***次演練成功到現在,我們經歷過 16 次整體性的多活切換。
這 16 次切換既包含正常的演練,也包含由于發生故障而進行的真實切換。其中,最近的一次切換是因為我們上海機房的公網出口發生了故障,我們將其所有流量都切換到了北京。
實現多活的背景
下面我從五方面介紹實施多活之前的一些背景狀況:
- 業務特點
- 技術復雜
- 運維兜底
- 故障頻發
- 機房容量

業務特點:我們有三大流量入口,分別是用戶端、商戶端以及騎手端。
一個典型的下單流程是:用戶打開 App 產生一個訂單,店家在商戶端進行接單,然后生成一個物流派送服務的運單。
而該流程與傳統電商訂單的區別在于:如果在商城生成一個訂單,后臺商戶端可以到第二天才收到,這種延時并無大礙。
但是對于餓了么就不行,外賣的時效性要求很高,如果在 10 分鐘之內商戶還未接單的話,用戶要么會去投訴,要么可能就會取消訂單,更換美團、百度外賣,從而會造成用戶的流失。
另外,我們也有很強的地域性。比如說在上海生成的訂單,一般只適用于上海本地區,而不會需要送到其他地方。
同時,我們的業務也有著明顯的峰值,上午的高峰,一般在 11 點;而下午則會是在 5 點到 6 點之間。
我們通過整個監控曲線便可對全鏈路的請求一目了然。這就是我們公司乃至整個外賣行業的業務特點。
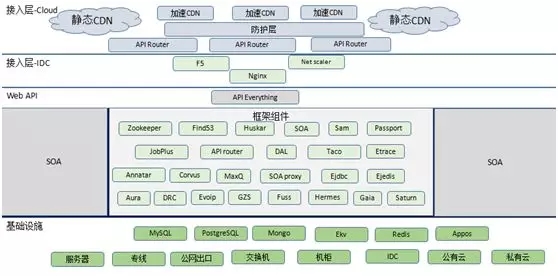
技術復雜:上圖是流量請求從進入到底層的整個技術架構。
SOA(面向服務的體系結構)系統架構本身并不復雜,其實大部分互聯網公司的技術架構演進到***都是類似的。
我們真正的復雜之處在于:各種組件、基礎設施以及整個的接入層存在多語言的問題。
在 2015 年之前,我們的前端是用 PHP 寫的,而后端則是 Python 寫的。在經歷了兩年的演進之后,我們現在已把所有由 PHP 語言寫的部分都替換掉了。而為了適用多種語言,我們的組件不得不為某一種語言多做一次適配。
比如說:我們要跟蹤(trace)整個鏈路,而且用到了多種語言,那么我們就要為之研發出多種 SDK,并需要花大量的成本去維護這些 SDK。
可見,復雜性往往不在于我們有多少組件,而是我們要為每一種組件所提供的維護上。
我們當前的整個 SOA 框架體系主要面向兩種語言:Python 和 Java,逐漸改造成更多地面向 Java。
中間的 API Everything 包含了許多為不同的應用場景而開發的各種 API 項目。而我們基礎設施方面,主要包括了整個存儲與緩存,以及公有云和私有云。

運維兜底:在業務飛速發展的過程當中,我們的運維團隊做得更多的還是“兜底”工作。
***的統計,我們現在有將近 16000 臺服務器、1600 個應用、1000 名開發人員、4 個物理 IDC、以及部署了防護層的兩朵云。也有一些非常小的第三方云服務平臺,包括 AWS 和阿里聚石塔等。
在業務增長過程當中,基于整個 IDC 的基礎設施環境,我們對交付的機型統一定制,并且改進了采購的供應鏈,包括:標準化的整機柜交付和數據清洗等。
對于應用使用的數據庫與緩存,我們也做了大量的資源拆分與改造工作,比如數據庫,改造關鍵路徑隔離,垂直拆分,sharding,SQL 審核,接入數據庫中間件dal,對緩存 redis 使用治理,遷移自研的 redis cluster 代理 corvus,聯合框架實現存儲使用的規范化,服務化。
曾經面臨比較大的挑戰是數據庫 DDL,表設計在每家公司都有一些自己的特點,例如阿里、百度他們每周 DDL 次數很少。
但是我們每周則會有將近三位數的 DDL 變更,這和項目文化以及業務交付有關。
DBA 團隊以及 DAL 團隊為此做了幾件事情:表數據量紅線,基于 Gh-OST 改進 online schema change 工具,Edb 自助發布。這樣大大減少了數據庫 DDL 事故率以及變更效率。
在多活改造過程中,工具的研發速度相對落后,我們在運維部署服務,組件的推廣和治理過程中,大部分都還是人工推廣、治理。
我們還負責全網的穩定性,以及故障管理,包括預案演練、故障發現、應急響應、事故復盤等,以及對事故定損定級。
故障管理并不是為了追責,而是通過記錄去分析每一次故障發生的原因,以及跟進改進措施,避免故障再次發生。
我們還定義了一個全網穩定性計數器,記錄未發生重大事故的累計時間,當故障定級應達到 P2 以上時清零重新開始。
歷史上我們保持最長的全網穩定性紀錄是 135 天,而美團已經超過了 180 天,還有一些差距。
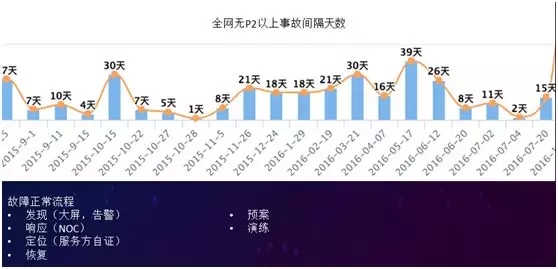
故障頻發:根據上圖“故障頻發”所反映的數據,大家可以看到,2015 年和 2016 年的數據慘不忍睹。
按天計算,我們經常會出現 P2 級別以上的事故,最短的是隔 1 天就出現 1 個 P2 以上事故。
我們不得不進行改進,于是我們組建了一個叫 NOC(Notification Operation Center)的團隊。
這個是參照 Google SRE 所建立的負責 7*24 應急響應團隊,以及初步原因判斷,執行常規的演練,組織復盤,跟進復盤改進落地情況。
NOC 定義公司通用故障定級定損/定責的標準:P0—P5 的事故等級,其參照的標準來自于業務特性的四個維度,它們分別是:
- 在高峰期/非高峰期的嚴重影響,包括受損時間段和受損時長。
- 對全網業務訂單的損失比。
- 損失金額。
- 輿情的影響。包括與美團、百度外賣、其他平臺的競爭。不過區別于外賣食材的本身品質,我們這里討論的是技術上的故障。
比如商家無緣無故取消了客戶的訂單,或是由于其他各種原因導致客戶在微博、或向客服部門投訴的數量上升。
上述這些不同的維度,結合高峰期與低峰期的不同,都是我們定級的標準。
根據各種事故運營定級/定責的規范,我們建立了響應的排障 SOP(標準操作流程),進而我們用報表來進行統計。
除了故障的次數之外,MTTR(平均恢復時間)也是一個重要的指標。通過響應的 SOP,我們可以去分析某次故障的本身原因,是因為發現的時間較長,還是響應的時間較長,亦或排障的時間比較長。
通過落地的標準化流程,并且根據報表中的 MTTR,我們就可以分析出在發生故障之后,到底是哪個環節花費了較長的時間。
提到“故障頻發”,我們認為所有的故障,包括組件上的故障和底層服務器的故障,都會最終反映到業務曲線之上。
因此我們 NOC 辦公室有一個大屏幕來顯示重要業務曲線,當曲線的走勢發生異常的時候,我們就能及時響應通知到對應的人員。
在訂單的高峰期,我們更講求時效性。即發生了故障之后,我們要做的***件事,或者說我們的目標是快速地止損,而不是去花時間定位問題。
這就是我們去實現多活的目的,而多活正是為我們的兜底工作進行“續命”。原來我只有一個機房,如果該機房的設施發生了故障,而正值業務高峰期的時候,后果是不堪設想的。

機房容量:我們再來看看整個機房的容量,在 2015 年之前,當時訂單量很少,我們的服務器散落在機房里,機型也比較隨意。
而到了 2015 年,我們大概有了 1500 臺服務器;在 2016 年間,我們增長到了 6000 臺;2017 年,我們則擁有將近 16000 臺。這些還不包括在云上的 ECS 數量。
有過 IDC 相關工作經歷的同學可能都知道:對于大型公司的交付,往往都是以模塊簽的合同。
但初期我們并不知道業務發展會這么快,服務器是和其他公司公用模塊和機架,服務器也是老舊而且非標準化,同時組網的環境也非常復雜。甚至有一段時期,我們就算有錢去購買服務器,機房里也沒有擴容的空間。
為什么要做多活
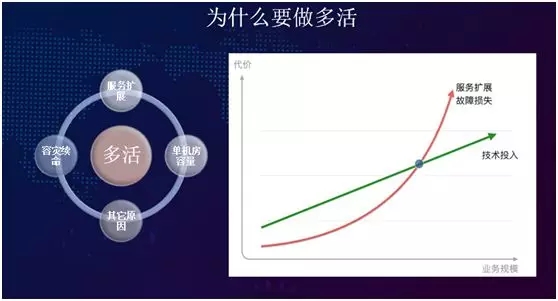
為什么要做多活,總結一下有四個方面:容災續命、服務擴展、單機房容量、和其他的一些原因。
如上圖右側所示,我們通過一個類似 X/Y 軸的曲線進行評估。隨著業務規模的增長,技術投入,服務擴展,故障損失已不是一種并行增長的關系了。
餓了么多活運維挑戰
下面分享一下我們當時做了哪些運維的規劃,主要分為五個部分:
- 多活技術架構
- IDC 規劃
- SOA 服務改造
- 數據庫改造
- 容災保障
多活技術架構
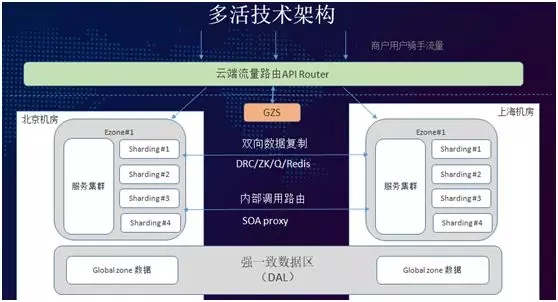
我們通過設置既可把昆山劃分到上海,又可以劃到蘇州(這與行政區無關、僅關系到外賣的遞送半徑)。因此我們提出了地理圍欄的概念,研發了 GZS 組件。
我們把全國省市在 GZS(globalzone service)服務上區分地理圍欄,將全國分成了 32 個 Shard,來自每個 Shard 的請求進入系統之后,通過 GZS 判斷請求應該路由到所屬的機房。
如圖最下方所示,對于一些有強一致性需求的數據要求,我們提出了 Global zone 的概念。屬于 Global zone 的數據庫,寫操作僅限于在一個機房,讀的操作可以在不同 zone 內的 local slave 上。
多活技術架構五大核心組件:
- API Router:流量入口 API Router,這是我們的***個核心的組件,提供請求代理及路由功能。
- GZS:管理地理圍欄數據及 Shard 分配規則。
- DRC:DRC(Data replication center)數據庫跨機房同步工具,同時支持數據變更訂閱,用于緩存同步。
- SOA proxy:多活非多活之間調用。
- DAL:原本是數據庫中間件,為了防止數據被路由到錯誤的機房,造成數據不一致的情況,多活項目中配合做了一些改造。
整個多活技術架構的核心目標在于:始終保證在一個機房內完成整個訂單的流程。
為了實現這個目標,研發了 5 大功能組件,還調研識別有著強一致性的數據需求,一起從整體上做了規劃和改造。
IDC 規劃
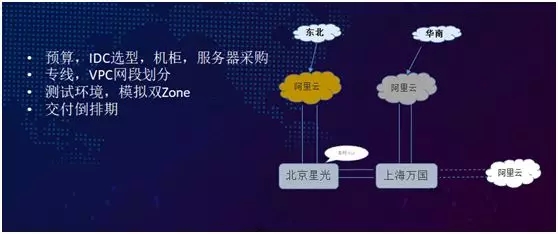
在 2016 年底啟動多活項目,確定了南北兩個機房,以及流量入口,開始進行 IDC 選型,實地考察了幾家上海的 IDC 公司,最終選擇了萬國數據機房。同時結合做抗 100% 流量服務器預算、提交采購部門采購需求。
規劃多活聯調測試環境,模擬生產雙 ezone、劃分 vpc,以及***的業務同期改造。
如上圖右側所示,以兩處不同的流量為例,不同區域通過接入層進來的流量,分別對應北京和上海不同的機房,在正常情況下整個訂單的流程也都會在本區域的機房被處理,同時在必要時能夠相互分流。
SOA 服務改造
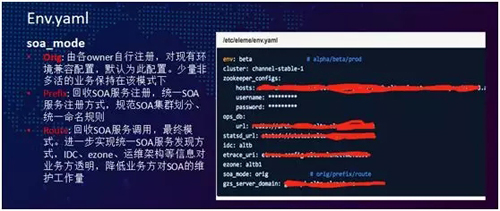
我們對 SOA 服務注冊發現也做了一些改造工作。先說下多活以前是什么情況,某一個應用服務 AppId 要上線,物理集群環境準備好,在 SOA 注冊時對應了一個 SOA cluster 集群。
另外一些大的集群,對不同的業務調用劃分不同的泳道,并將這些泳道在應用發布的時候,定義到不同的應用集群上,這就是整個 AppId 部署的邏輯。
這對于單機房來說是很簡單的,但是在雙機房場景中,需要改造成同一個 AppId,只調用本機房的 SOA cluster,我們在甬道和分布集群的基礎上引入了一個類似于單元的 ezone 概念。
SOA Mode 的改造方案,其中包括如下三種模式:
- Orig:兼容模式,默認的服務注冊發現方式。
- Prefix:收回服務注冊、統一 SOA 服務注冊的方式。此模式主要針對的是我們許多新上線的多活應用。對于一些老的業務,默認還是沿用 Orig 模式。
- Route:這是回收 SOA 服務調用的最終模式,進一步實現了統一 SOA 的服務注冊發現。整個 IDC、ezone、運維架構等信息對于業務方都是透明,從而降低了業務方對于 SOA 所產生的維護工作量。
數據庫改造

按照前面對整個應用部署的劃分,即多活、非多活以及強一致性的 Global zone,對數據庫也進行了相應的規劃。
我們先后進行了業務數據一致性的調研,復制一致性的規劃,多活的集群改造成通過 DRC 來雙向復制,Global zone 則采用原生的 Replication。
具體改造可分為三部分:
- 數據庫集群改造,根據倒排期的時間點,分派專門的團隊去跟進,將整個過程拆分出詳細的操作計劃。
- 數據庫中間件 DAL 改造,增加校驗功能,保證 SQL 不會寫入錯誤的機房。實現了寫入錯誤的數據保護,增加一道兜底防護。
- DRC 改造,多活兩地實例間改造程 DRC 復制。
容災保障

容災保障,區分了三個不同的等級:
- 流量入口故障,常見的有 DNS 解析變更,網絡出口故障,某省市骨干線路故障,以及 AR 故障。
- IDC 內故障,常見的有變更發布故障,歷史 Bug 觸發,錯誤配置,硬件故障,網絡故障,容量問題等。
- 單機房完全不可用。目前尚未完全實現,但是我們如今正在進行斷網演練。模擬某個機房里的所有 zone 都因為不可抗力宕掉了,也要保證該機房的所有應用能夠被切換到另一個機房,繼續保障服務可用。
當然這沒能從根本上解決雙機房同時發生故障的情況。當雙機房同時發生問題時,目前還是要依賴于有經驗的工程師,以及我們自動化的故障定位服務。
餓了么運營體系探索
在整個餓了么運維轉型的過程中,我們如何將組織能力轉型成為運營能力?下面是我們的五個思路:
- 應用發布
- 監控體系
- 預案和演練
- 容量規劃
- 單機房成本分析
應用發布
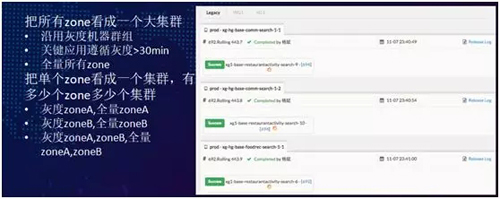
首先來看應用發布。在單機房的時候,我們一個 AppId 對應一個或多個 SOA cluster 集群,同時運維會配置灰度機器群組,并要求關鍵應用需要灰度 30 分鐘。
那么在多活情況下,應用如何實現發布呢?我們在規劃中采用了兩種方式可選:
- 把所有 zone 看成一個大型的“集群”,沿用灰度機器群體的發布策略。我們先在單個機房里做一次灰度,然后延伸到所有的 zone,保證每個關鍵應用都遵循灰度大于 30 分鐘的規則,***再全量到所有的 zone 上。
- 把單個 zone 看成一個“集群”,有多少個 zone 就有多少個“集群”。首先灰度 zoneA、并全量 zoneA,然后灰度 zoneB、并全量 zoneB。
或者您也可以先灰度 zoneA、并灰度 zoneB,然后同時觀察、并驗證發布的狀態,***再全量 zoneA、并全量 zoneB。您可以根據自身情況自行選擇和實現。
監控體系
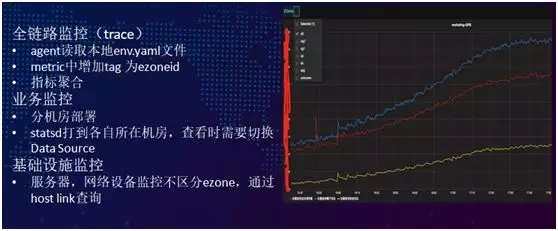
餓了么目前有三大監控體系:
- 全鏈路監控。在 Agent 啟動時讀取一個文件,以獲知當前處于哪個 zone,然后會在 metric 中為 ezoneid 增加一個 tag,并且進行指標聚合。默認在一個機房里可有多個 zone。
- 業務監控。進行分機房的部署,將 statsd 打到各自所在機房,而在查看時則需要切換 Data Source。
- 基礎設施監控。而對于服務器、網絡設備監控則不必區分 ezone,通過 host link 來進行查詢。
預案和演練

對于常見的故障做了預案,制定常規演練計劃,并且定期演練。目前我們也正在做一套演練編排系統,上線之后應該會有更好的效果。
容量規劃
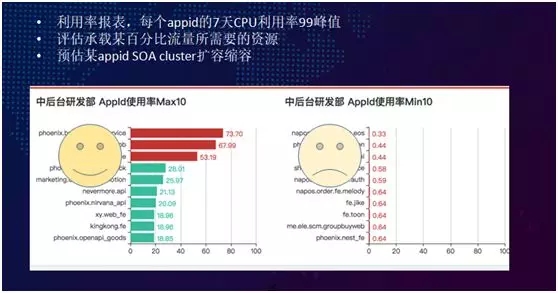
至于容量規劃(Capacity planning),我們目前只是采集到 AppId 的服務器 CPU 利用率。
結合現有兩地機房的常態化負載應該是:北京的 zone 承載 52% 的流量;而上海機房分攤 48%。
常規情況每周三會進行全鏈路壓力測試。通過評估,我們能獲知整個關鍵路徑的容量。
未來我們也會假設倘若再增加了 15% 的流量,那么在現有的 AppId 基礎上,我們還需要增加的服務器臺數。
同時,在承載了現有訂單數量的基礎上,我們要估算現有的單個 SOA cluster 所能承載的訂單請求極限。
如上圖所示,通過獲取 AppId 利用率統計列表,我們能夠發現:由于前期業務的爆炸式增長,我們在不計成本的情況下所購置的服務器機,其利用率實際上是比較低下的。
單機房成本分析

對于現有 IDC 成本核算,是按照一定的折舊標準將它們分攤到每個月,并與業務上單月的總體完成訂單量進行對比,最終計算出每筆訂單的 IT 成本,以及計算出每核成本。
另外,我們還可以與租用云服務的成本相比較,從而得出成本優劣。
對于一些公共池化資源,把池化的各種組件服務分攤到各個部門和每個 AppId 之上。
這樣就能指導每個 AppId 使用了多少臺服務器,IT 成本是多少,我們便可以進一步開展成本分析。
程炎嶺,現任餓了么技術運營負責人,從數據庫到運維,再到技術+運營。目前主要負責餓了么上千個 AppId 的運維、IDC 建設及穩定性保障工作。2015 年加入餓了么,兩年多來經歷了餓了么體量和技術的蓬勃發展,在一次次挑戰和困境中伴隨技術運營團隊的成長。作為一位 10 多年的運維老兵,希望把故事分享給大家,也很期待和大家一起學習和交流。

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】






















