數(shù)據(jù)有限時(shí)怎樣調(diào)優(yōu)深度學(xué)習(xí)模型
遷移學(xué)習(xí)
所謂遷移學(xué)習(xí),就是將一個(gè)問題上訓(xùn)練好的模型通過簡(jiǎn)單的調(diào)整,使其適用一個(gè)新的問題,可以認(rèn)為是一種模型調(diào)優(yōu)的“取巧”方法。可以類比人的舉一反三能力。
習(xí)")
遷移學(xué)習(xí)的特點(diǎn)
1. 需求數(shù)據(jù)量少
假設(shè)有兩個(gè)領(lǐng)域,一個(gè)領(lǐng)域已經(jīng)有很多的數(shù)據(jù),能成功地建一個(gè)模型,有一個(gè)領(lǐng)域數(shù)據(jù)不多,但是和前面那個(gè)領(lǐng)域是關(guān)聯(lián)的,就可以把那個(gè)模型給遷移過來。比如,我們想做一個(gè)化妝品推薦模型,但數(shù)據(jù)量較少,可以先用一個(gè)成型的較為穩(wěn)定的飾品推薦模型進(jìn)行調(diào)優(yōu)。跨領(lǐng)域的在學(xué)術(shù)界也有嘗試哦,比如網(wǎng)絡(luò)搜索可以遷移到推薦,圖象識(shí)別可以遷移到文本識(shí)別。
2. 訓(xùn)練時(shí)間少
在沒有GPU的普通臺(tái)式機(jī)或者筆記本上,實(shí)現(xiàn)Google的Inception-v3模型遷移學(xué)習(xí)訓(xùn)練過程只需要大約五分鐘(tensorflow框架)。
3. 容易滿足個(gè)性化需求
比如每個(gè)人都希望自己的手機(jī)能夠記住一些習(xí)慣,這樣不用每次都去設(shè)定它,怎么才能讓手機(jī)記住這一點(diǎn)呢?
其實(shí)可以通過遷移學(xué)習(xí)把一個(gè)通用的用戶使用手機(jī)的模型遷移到個(gè)性化的數(shù)據(jù)上面 。不過,如果數(shù)據(jù)量足夠的情況下,遷移學(xué)習(xí)的效果一般不如完全重新訓(xùn)練哦。遷移學(xué)習(xí)適合與快速小巧的工程化,解決所謂的冷啟動(dòng)問題,當(dāng)數(shù)據(jù)收集得足夠多了以后,我們?cè)俑挠蒙疃葘W(xué)習(xí)。
遷移學(xué)習(xí)四種實(shí)現(xiàn)方法
習(xí)四種實(shí)現(xiàn)方法")
1. 樣本遷移Instance-based Transfer Learning
一般就是對(duì)樣本進(jìn)行加權(quán),給比較重要的樣本較大的權(quán)重。
樣本遷移即在數(shù)據(jù)集(源領(lǐng)域)中找到與目標(biāo)領(lǐng)域相似的數(shù)據(jù),把這個(gè)數(shù)據(jù)放大多倍,與目標(biāo)領(lǐng)域的數(shù)據(jù)進(jìn)行匹配。其特點(diǎn)是:需要對(duì)不同例子加權(quán);需要用數(shù)據(jù)進(jìn)行訓(xùn)練。比如下圖,可以將一個(gè)動(dòng)物識(shí)模型的源數(shù)據(jù)中的狗狗圖片增多,達(dá)到專門針對(duì)狗的識(shí)別模型。

2. 特征遷移Feature-based Transfer Learning
在特征空間進(jìn)行遷移,一般需要把源領(lǐng)域和目標(biāo)領(lǐng)域的特征投影到同一個(gè)特征空間里進(jìn)行。
如下圖示例,特征遷移是通過觀察源領(lǐng)域圖像與目標(biāo)域圖像之間的共同特征,然后利用觀察所得的共同特征在不同層級(jí)的特征間進(jìn)行自動(dòng)遷移。

3. 模型遷移Model-based Transfer Learning
整個(gè)模型應(yīng)用到目標(biāo)領(lǐng)域去,比如目前常用的對(duì)預(yù)訓(xùn)練好的深度網(wǎng)絡(luò)做微調(diào),也可以叫做參數(shù)遷移。
模型遷移利用上千萬的圖象訓(xùn)練一個(gè)圖象識(shí)別的系統(tǒng),當(dāng)我們遇到一個(gè)新的圖象領(lǐng)域,就不用再去找?guī)浊f個(gè)圖象來訓(xùn)練了,可以原來的圖像識(shí)別系統(tǒng)遷移到新的領(lǐng)域,所以在新的領(lǐng)域只用幾萬張圖片同樣能夠獲取相同的效果。模型遷移的一個(gè)好處是我們可以區(qū)分,就是可以和深度學(xué)習(xí)結(jié)合起來,我們可以區(qū)分不同層次可遷移的度,相似度比較高的那些層次他們被遷移的可能性就大一些 。

這里講一個(gè)例子,比如我們想將訓(xùn)練好的Inception-v3簡(jiǎn)單調(diào)整,解決一個(gè)新的圖像分類問題。根據(jù)論文DeCAF : A Deep Convolutional Activation Feature for Generic Visual Recognition中的結(jié)論,可以保留訓(xùn)練好的Inception-v3模型中所有卷積層的參數(shù),只是替換***一層全連階層。在***這一層全連階層之前的網(wǎng)絡(luò)層稱之為瓶頸層。
將新的圖像通過訓(xùn)練好的卷積神經(jīng)網(wǎng)絡(luò)直到瓶頸層的過程可以看成是對(duì)圖像進(jìn)行特征提取的過程。在訓(xùn)練好的Inception-v3模型中,因?yàn)閷⑵款i層的輸出再通過一個(gè)單層的全連接層神經(jīng)網(wǎng)絡(luò)可以很好的區(qū)分1000種類別的圖像,所以有理由認(rèn)為瓶頸層輸出的借點(diǎn)向量可以作為任何圖像的一個(gè)新的單層全連接神經(jīng)網(wǎng)絡(luò)處理新的分類問題。
4. 關(guān)系遷移Relational Transfer Learning
如社會(huì)網(wǎng)絡(luò),社交網(wǎng)絡(luò)之間的遷移。
系遷移")
根據(jù)源和目標(biāo)領(lǐng)域是否相同、源和目標(biāo)任務(wù)是否相同、以及源和目標(biāo)領(lǐng)域是否有標(biāo)注數(shù)據(jù),又可以把遷移學(xué)習(xí)分成如下圖所示:
習(xí)")
前沿的遷移學(xué)習(xí)方向
1. Reinforcement Transfer Learning
怎么遷移智能體學(xué)習(xí)到的知識(shí):比如我學(xué)會(huì)了一個(gè)游戲,那么我在另一個(gè)相似的游戲里面也是可以應(yīng)用一些類似的策略的。
2. Transitive Transfer Learning
傳遞性遷移學(xué)習(xí),兩個(gè)domain之間如果相隔得太遠(yuǎn),那么我們就插入一些intermediate domains,一步步做遷移。
3. Source-Free Transfer Learning
不知道是哪個(gè)源領(lǐng)域的情況下如何進(jìn)行遷移學(xué)習(xí)。
假如你目前有了一些代表性數(shù)據(jù)集,進(jìn)入了溫飽階段,恨不得壓榨出每一滴數(shù)據(jù)的價(jià)值,又害怕用力過以偏概全(俗稱過擬合)。那么我們可能需要如下技巧。
嚴(yán)防死守過擬合(所謂盡人事,聽……)
深度學(xué)習(xí)由于超參數(shù)的個(gè)數(shù)比較多,訓(xùn)練樣本數(shù)目相對(duì)超參數(shù)來說略顯不足,一不小心就容易發(fā)生過擬合。從本質(zhì)上來說,過擬合是因?yàn)槟P偷膶W(xué)習(xí)能力太強(qiáng),除了學(xué)習(xí)到了樣本空間的共有特性外,還學(xué)習(xí)到了訓(xùn)練樣本集上的噪聲。因?yàn)檫@些噪聲的存在,導(dǎo)致了模型的泛化性能下降。
深度學(xué)習(xí)中有幾種較為常用的改善過擬合方法:
1. data augmentation
data augmentation即數(shù)據(jù)增強(qiáng),數(shù)據(jù)增強(qiáng)其實(shí)是增加訓(xùn)練樣本的一種方法。以人臉識(shí)別為例,對(duì)于人臉識(shí)別的數(shù)據(jù)增強(qiáng),一般有隨機(jī)裁剪,隨機(jī)加光照,隨機(jī)左右翻轉(zhuǎn)等。
通過類似的手段,無論是圖像處理,還是語音或者自然語言處理,我們都能有效地增加樣本數(shù)量。更多的訓(xùn)練樣本意味著模型能夠?qū)W到更多的本質(zhì)特征,具有對(duì)于噪聲更好的魯棒性,從而具有更好的泛化性能,能夠有效地避免過擬合。
2. early stopping
early stopping,顧名思義,就是在訓(xùn)練次數(shù)沒有達(dá)到預(yù)先設(shè)定的***訓(xùn)練次數(shù)時(shí),我們就讓網(wǎng)絡(luò)停止訓(xùn)練。采用early stopping需要我們?cè)谟?xùn)練集合上劃分出一小部分(大概10%~30%吧)作為驗(yàn)證集,驗(yàn)證集不參與訓(xùn)練,可以視為是我們知道結(jié)果的測(cè)試集。我們通過實(shí)時(shí)監(jiān)控模型在驗(yàn)證集上的表現(xiàn)來(實(shí)時(shí)監(jiān)控并不意味著每次迭代都去監(jiān)控,可以每1000次去觀察一次),一旦模型在驗(yàn)證集上的表現(xiàn)呈現(xiàn)下降趨勢(shì),我們就停止訓(xùn)練,因?yàn)樵儆?xùn)練下去模型的泛化性能只會(huì)更差。
而實(shí)際訓(xùn)練中,我們不可能一直坐在電腦旁觀察驗(yàn)證集的準(zhǔn)確率,更一般的做法是每隔一段時(shí)間(比如每1000次迭代)就保存一次模型,然后選擇在驗(yàn)證集上效果***的模型作為最終的模型。
3. 增加Dropout層

Dropout(https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf )原理非常簡(jiǎn)單,Dropout t的作用對(duì)象是layer,對(duì)于某一層中的每個(gè)節(jié)點(diǎn),Dropout技術(shù)使得該節(jié)點(diǎn)以一定的概率p不參與到訓(xùn)練的過程中(即前向傳導(dǎo)時(shí)不參與計(jì)算,bp計(jì)算時(shí)不參與梯度更新)。
如上圖所示,實(shí)驗(yàn)證明了,Dropout的效果非常爆炸,對(duì)于模型訓(xùn)練有非常好的效果。
為什么Dropout能起到這么大作用呢?
一個(gè)原因是通過Dropout,節(jié)點(diǎn)之間的耦合度降低了,節(jié)點(diǎn)對(duì)于其他節(jié)點(diǎn)不再那么敏感了,這樣就可以促使模型學(xué)到更加魯棒的特征;
第二個(gè)是Dropout 層中的每個(gè)節(jié)點(diǎn)都沒有得到充分的訓(xùn)練(因?yàn)樗鼈冎挥幸话氲某銮诼?,這樣就避免了對(duì)于訓(xùn)練樣本的過分學(xué)習(xí);
第三個(gè)原因是在測(cè)試階段,Dropout 層的所有節(jié)點(diǎn)都用上了,這樣就起到了ensemble的作用,ensemble能夠有效地克服模型的過擬合。
在實(shí)際的模型訓(xùn)練中,ropout在一般的框架中初始默認(rèn)的0.5概率的丟棄率是保守的選擇,如果模型不是很復(fù)雜,設(shè)置為0.2就夠了。
不過也要注意到Dropout的缺點(diǎn):
(1)Dropout是一個(gè)正則化技術(shù),它減少了模型的有效容量。為了抵消這種影響,我們必須增大模型規(guī)模。不出意外的話,使用Dropout時(shí)***驗(yàn)證集的誤差會(huì)低很多,但這是以更大的模型和更多訓(xùn)練算法的迭代次數(shù)為代價(jià)換來的。對(duì)于非常大的數(shù)據(jù)集,正則化帶來的泛化誤差減少得很小。
在這些情況下,使用Dropout和更大模型的計(jì)算代價(jià)可能超過正則化帶來的好處。
(2)只有極少的訓(xùn)練樣本可用時(shí),Dropout不會(huì)很有效。
4. weight penality(L1&L2)
第四種常用的辦法就是weight decay,weight decay通過L1 norm和L2 norm強(qiáng)制地讓模型學(xué)習(xí)到比較小的權(quán)值。
這里有兩個(gè)問題:
(1)為什么L1和L2 norm能夠?qū)W習(xí)到比較小的權(quán)值?
(2)為什么比較小的權(quán)值能夠防止過擬合?
對(duì)于***個(gè)問題:
首先看一下L1和L2的定義:
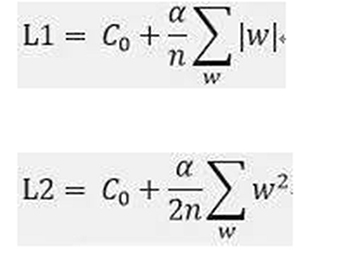
其中C0為未加上懲罰項(xiàng)的代價(jià)函數(shù)。那么L1和L2形式的代價(jià)函數(shù)會(huì)如何影響w的值呢?
1)未增加懲罰項(xiàng)w的更新
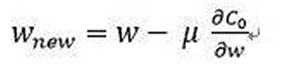
2) L1下的w更新,其中u為學(xué)習(xí)率
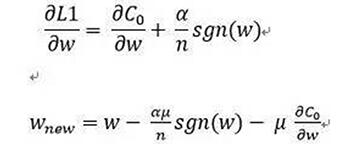
3) L2下的w更新,其中u為學(xué)習(xí)率
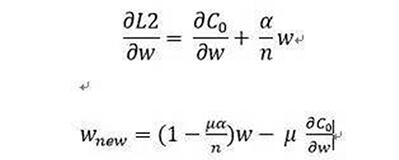
由上面的(1)(2)(3)可以看出,加上懲罰項(xiàng)之后,w明顯減少得更多。L1是以減法形式影響w,而L2則是以乘法形式影響w,因此L2又稱為weight decay。
對(duì)于第二個(gè)問題:
過擬合的本質(zhì)是什么呢?無非就是對(duì)于非本質(zhì)特征的噪聲過于敏感,把訓(xùn)練樣本里的噪聲當(dāng)作了特征,以至于在測(cè)試集上的表現(xiàn)非常稀爛。當(dāng)權(quán)值比較小時(shí),當(dāng)輸入有輕微的改動(dòng)(噪聲)時(shí),結(jié)果所受到的影響也比較小,所以懲罰項(xiàng)能在一定程度上防止過擬合。
除了千方百計(jì)增加數(shù)據(jù)多樣性,還要增加模型的多樣性
1、試試不斷調(diào)整隱層單元和數(shù)量
調(diào)模型,要有點(diǎn)靠天吃飯的寬容心態(tài),沒事就調(diào)調(diào)隱層單元和數(shù)量,省的GPU閑著,總有一款適合你。
一般來說,隱層單元數(shù)量多少?zèng)Q定了模型是否欠擬合或過擬合,兩害相權(quán)取其輕,盡量選擇更多的隱層單元,因?yàn)榭梢酝ㄟ^正則化的方法避免過擬合。與此類似的,盡可能的添加隱層數(shù)量,直到測(cè)試誤差不再改變?yōu)橹埂?/p>
2、試試兩個(gè)模型或者多個(gè)模型concat
比如,兩種不同分辨率的圖像數(shù)據(jù)集,分別訓(xùn)練出網(wǎng)絡(luò)模型a和網(wǎng)絡(luò)模型b,那么將a和b的瓶頸層concat在一起,用一個(gè)全連接層(或者隨便你怎么連,試著玩玩沒壞處)連起來,,輸入concat后的圖片,訓(xùn)練結(jié)果可能比單個(gè)網(wǎng)絡(luò)模型效果要好很多哦。
loss函數(shù)那些事兒
這里只從模型調(diào)優(yōu)的tric角度來介紹下。
Softmax-loss算是最常用的loss方法了,但是Softmax-loss不會(huì)適用于所有問題。比如在數(shù)據(jù)量不足夠大的情況下,softmax訓(xùn)練出來的人臉模型性能差,ECCV 2016有篇文章(A Discriminative Feature Learning Approach for Deep Face Recognition)提出了權(quán)衡的解決方案。通過添加center loss使得簡(jiǎn)單的softmax就能夠訓(xùn)練出擁有內(nèi)聚性的特征。該特點(diǎn)在人臉識(shí)別上尤為重要,從而使得在很少的數(shù)據(jù)情況下訓(xùn)練出來的模型也能有很好的作用。此外,contrastive-loss和triplet-loss也有其各自的好處,需要采樣過程,有興趣的可以多了解下。
花式調(diào)優(yōu)
1. batch size設(shè)置
batch size一般設(shè)定為2的指數(shù)倍,如64,128,512等,因?yàn)闊o論是多核CPU還是GPU加速,內(nèi)存管理仍然以字節(jié)為基本單元做硬件優(yōu)化,2的倍數(shù)設(shè)置將有效提高矩陣分片、張量計(jì)算等操作的硬件處理效率。
不同batch size的模型可能會(huì)帶來意想不到的準(zhǔn)確率提升,這個(gè)調(diào)節(jié)其實(shí)是有一定規(guī)律和技巧的。
2. 激勵(lì)函數(shù)
激勵(lì)函數(shù)為模型引入必要的非線性因素。Sigmoid函數(shù)由于其可微分的性質(zhì)是傳統(tǒng)神經(jīng)網(wǎng)絡(luò)的***選擇,但在深層網(wǎng)絡(luò)中會(huì)引入梯度消失和非零點(diǎn)中心問題。Tanh函數(shù)可避免非零點(diǎn)中心問題。ReLU激勵(lì)函數(shù)很受歡迎,它更容易學(xué)習(xí)優(yōu)化。因?yàn)槠浞侄尉€性性質(zhì),導(dǎo)致其前傳,后傳,求導(dǎo)都是分段線性,而傳統(tǒng)的sigmoid函數(shù),由于兩端飽和,在傳播過程中容易丟棄信息。ReLU激勵(lì)函數(shù)缺點(diǎn)是不能用Gradient-Based方法。同時(shí)如果de-active了,容易無法再次active。不過有辦法解決,使用maxout激勵(lì)函數(shù)。
3. 權(quán)重初始化
權(quán)重初始化常采用隨機(jī)生成方法以避免網(wǎng)絡(luò)單元的對(duì)稱性,但仍過于太過粗糙,根據(jù)目前***的實(shí)驗(yàn)結(jié)果,權(quán)重的均勻分布初始化是一個(gè)***的選擇,同時(shí)均勻分布的函數(shù)范圍由單元的連接數(shù)確定,即越多連接權(quán)重相對(duì)越小。
Tensorflow的 word2vec程序中初始化權(quán)重的例子,權(quán)重初始值從一個(gè)均勻分布中隨機(jī)采樣:

4. 學(xué)習(xí)速率
學(xué)習(xí)速率是重要的超參數(shù)之一,它是在收斂速度和是否收斂之間的權(quán)衡參數(shù)。選擇0.01或者伴隨著迭代逐步減少都是合理的選擇,***的方法開始研究學(xué)習(xí)速率的自動(dòng)調(diào)整變化,例如基于目標(biāo)函數(shù)曲率的動(dòng)量或自適應(yīng)調(diào)參等。
5. 選擇優(yōu)化算法
傳統(tǒng)的隨機(jī)梯度下降算法雖然適用很廣,但并不高效,最近出現(xiàn)很多更靈活的優(yōu)化算法,例如Adagrad、RMSProp等,可在迭代優(yōu)化的過程中自適應(yīng)的調(diào)節(jié)學(xué)習(xí)速率等超參數(shù),效果更佳。